Notre ReX du Devfest Nantes 2025 24 Oct 7:01 AM (yesterday, 7:01 am)

L’édition 2025 du DevFest Nantes, qui a réuni plus de 3500 passionnés à la Cité des Congrès sur deux jours intenses, restera un millésime à part pour l’équipe Ippon. Cette année, nous étions une vingtaine de Nantais, mobilisés et enthousiastes, accompagnés de nos speakers bordelais Vivien Malèze et Sébastien Oddo, venus partager leur expertise sur Open Telemetry et de Thomas Boutin venu de Tours pour échanger sur les impacts sociaux et environnementaux de nos smartphones. Notre stand n’a pas désempli, suscitant de nombreux échanges et rencontres tout au long de l’événement, entre deux conférences.

Dans la suite de cet article, nous vous proposons un retour détaillé sur les talks qui ont particulièrement retenu notre attention lors de cette nouvelle édition du DevFest. Plongez avec nous dans ces éclairages techniques qui ont nourri nos échanges et permis d’enrichir notre savoir-faire collectif.
OpenRewrite: Refactor as code
Présenté par Jérôme Tama – Onepoint Bordeaux
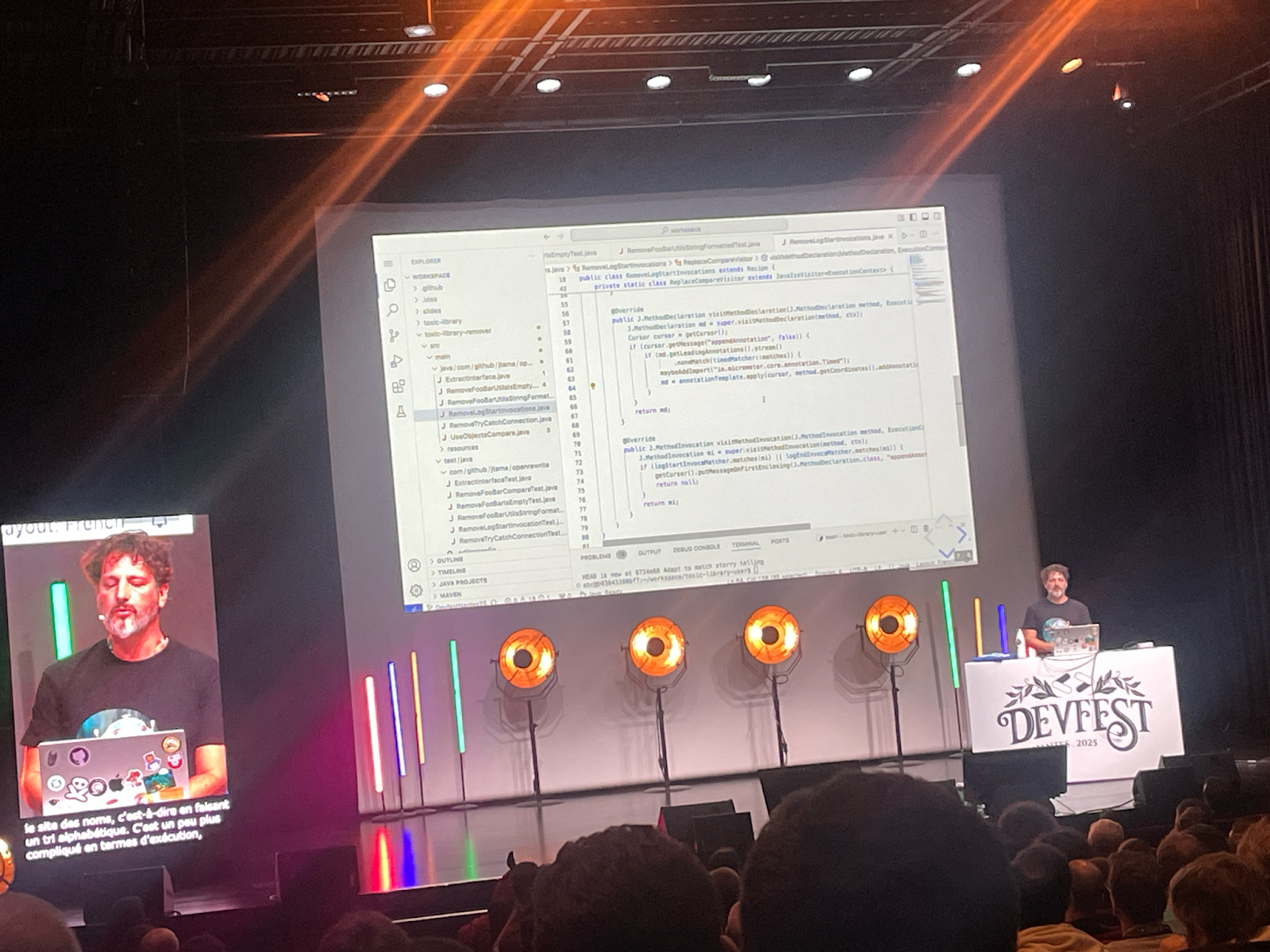
Jérôme débute en comparant le code à une maison : tout y est présent, mais pas toujours à sa place. Cette métaphore illustre parfaitement les difficultés de lecture et de maintenance rencontrées par les développeurs. Son objectif est clair : montrer comment réécrire le code de manière plus efficace, maîtrisée et automatisée.
Pour cela, il présente OpenRewrite, un framework open source conçu pour automatiser la réécriture de code. Testable, distribuable et multi-langage, il supporte Java, Kotlin, Groovy, YAML, et plus récemment TypeScript. Le cœur du framework repose sur le concept de “recipes”, de petites unités atomiques capables de parcourir et transformer le code. Ces recettes peuvent se composer entre elles pour réaliser des modifications plus complexes.
OpenRewrite s’appuie sur le Lossless Syntax Tree (LST), un arbre syntaxique préservant la mise en forme et les commentaires, garantissant ainsi que la structure du code reste intacte après transformation. Les recettes peuvent être exécutées de différentes façons, que ce soit via la CLI ou des plugins comme ceux de Maven.
Pour illustrer la puissance de l’outil, Jérôme montre la migration d’un projet de JUnit 4 vers JUnit 5 : une tâche habituellement longue de trois semaines, réalisée en quelques secondes grâce à une recette existante. Il précise qu’il existe des centaines de recettes gratuites, et qu’il est même possible d’en créer sans écrire de code, via une approche déclarative.
Cependant, Jérôme met en garde : un outil aussi puissant doit être utilisé avec discernement, notamment pour la maintenance de bibliothèques internes ou open source. En conclusion, OpenRewrite incarne une approche “refactor-as-code” à la fois pragmatique, testable et reproductible, offrant un véritable gain de temps et une amélioration durable de la qualité du code.
Unconf - Paroles de dev' : la conférence où vous avez la parole !
Par Benoit Martin et Damien Raude-Morvan
Cette Unconference, un des formats inédits pour l’édition 2025 du DevFest, était une réelle découverte. Et pour cause : il n’y a pas de sujet choisi au préalable. Après un rappel des règles de bonnes conduites pour les 2h que nous allions passer ensemble (écoute, empathie, bienveillance), Benoit et Damien nous ont invité à faire un brainstorming. Nous devions réfléchir aux sujets que nous souhaitions aborder avec les participants. Nous les avons noté sur des post-its, puis nous les avons mis sur un tableau. Ensuite, nous avons voté pour nos sujets préférés. Finalement, nous avons séparé la table en deux groupes en fonction des thématiques : une sur l’ubérisation des métiers du développement et la place des invisibles dans nos métiers. L’autre sur les problématiques liées au refactoring et à la gestion de la dette à grande échelle, avec ensuite un sujet sur l’avenir du TDD avec l’avènement de l’agentique. Sur toute la durée du créneau, il était possible de changer de table comme nous le voulions, voire de quitter l’assemblée pour retourner sur le salon. La loi des deux pieds était bien en place 🙂. De manière analogue, il n’y avait pas de temps imparti pour aborder un sujet : il pouvait aussi bien être traité en 10mn qu’en 1h30.
Comme nos deux animateurs le stipulaient en préambule, nous sommes aussi nombreux et nombreuses à venir en conférence pour les discussions qui se déroulent entre les présentations. Et c’est vrai que ce format présentait ce côté rafraîchissant, et comblait les manques que nous pouvons parfois ressentir en sortie d’une présentation : manque de retour concret du terrain, débat sur les limites d’une approche ou encore l’impossibilité de poser des questions parce que le temps imparti était dépassé.
Au final, on peut en ressortir avec des outils à tester comme vibe-flow et des certitudes qui se retrouvent infirmées ou confirmées.
En conclusion, merci ! Et si le format vous intéresse, les software crafters de Nantes ont l’habitude de fonctionner de cette manière. Jetez-y un oeil !
Détective de la prod: résoudre l’enquête avant le crash
Présenté par Sébastien Ferrer – OVHCloud Nantes

Sébastien ouvre son talk en opposant les deux grandes phases du cycle de vie logiciel : le build (développement) et le run (exploitation).Fort de son expérience d’astreinte, il décrit la difficulté de gérer plusieurs projets sans toujours les connaître en profondeur.
Être “de run”, explique-t-il, signifie assurer le suivi des incidents, des tickets et des indicateurs clés comme le TTA et le TTR, tout en restant le principal point de contact en cas de problème.Pour diagnostiquer efficacement, il faut adopter une posture de détective, en s’appuyant sur la Root Cause Analysis (RCA).
Différentes méthodes existent : le drill down, rigoureux mais long, et le bottom up, plus adapté aux couches basses comme le réseau.
Dans tous les cas, la priorité reste de restaurer le service avant de chercher la cause profonde.Une fois la situation stabilisée, vient le temps du cadrage, de la reproduction et du post-mortem.La méthode des Five Whys aide alors à remonter à l’origine du problème.
Cette logique s’inscrit dans une philosophie claire : “Développe ton application comme si tu allais la maintenir.”
Sébastien insiste ensuite sur l’importance des logs : anticiper les informations utiles, structurer les niveaux, et surtout adopter un format standardisé pour faciliter leur exploitation.Le monitoring complète cette visibilité, en offrant des métriques, des alertes et une meilleure réactivité face aux incidents.
Enfin, il relie ces bonnes pratiques à une démarche LEAN : uniformiser les projets grâce à des librairies communes, utiliser un linter pour garantir la cohérence du code, et continuer à progresser, notamment via son blog blog.kimi.ovh.
Angular Signal - Monde asynchrone, état dépendant
Workshop (lab de 2h) présenté par Modeste Assiongbon et Camille Pillot
Le DevFest, ce n’est pas que des conférences, mais aussi des “labs” ! Il s’agit d’ateliers de 2h, avec une trentaine de participants, où l’animateur anime une sorte de TD au travers de slides et petits exercices que les participants réalisent sur leur ordinateur.
J’ai assisté à un lab autour des signal et rxResource Angular, fraîchement matures depuis Angular 19. Ces nouveaux outils permettent de gérer des Observable de manière bien plus concise, tant dans le code TS que HTML. Elles permettent un affichage de l’état d’erreur ou de chargement simplifié. Les exercices se poursuivent sur des notions similaires avec les httpResource (qui simplifient la syntaxe d’appels serveur simples) et les LinkedSignal (qui rendent une computed modifiable au lieu de lecture seule).
Pourtant fervent utilisateur d’Angular au quotidien, j’ai appris plein de choses au travers de cet atelier, que je pourrai désormais appliquer sur mes projets !
Les exercices étaient très bien décrits et les slides très claires. La présentation est disponible sur SlideShare. Le dépôt avec les exercices est disponible sur GitHub.
Mobiles en Perspective: quels impacts sociaux et environnementaux ont nos smartphones ?
Présenté par Thomas Boutin (Ippon Technologies) et Robin Caroff (U Tech)
En 2007, le smartphone entrait dans nos vies. Depuis il est devenu notre réveil, notre appareil photo, notre carnet d’adresses, notre GPS, etc et les usages évoluent constamment au fur et à mesure des nouveautés proposées par les constructeurs et les éditeurs logiciels. Mais à quel prix ?

« Mobiles en Perspective », c’est une session un peu à part au DevFest Nantes 2025 : un format unconf, participatif, inspiré de la Fresque du Climat. Pas de slides ni de monologue : ici, on échange, on réfléchit ensemble et on explore les coulisses du numérique. On va donc essayer de ne pas tout dévoiler, parce que c’est avant-tout un format où le participant est acteur de l’atelier.
Thomas et Robin nous font redécouvrir le mobile étapes par étapes, avec une série de cartes prédéfinies : de sa fabrication à nos usages quotidiens, en passant par les infrastructures qui le font fonctionner. On parle beaucoup environnement aussi dans cet atelier. L’utilisation de ressources comme l’eau et les minerais lourds nécéssaires à la construction du matériel qu’il faut extraire (souvent dans des pays exploitant le travail des enfants.). La difficulté à recycler un smartphone, et son manque de rentabilité (moins de 5€ de matière première à récupérer) ainsi que le décyclage (perte de valeur des matériaux lors du recyclage) sont les sujets qui m’ont le plus choqués.
Enfin, les animateurs nous sensibilisent sur les impacts humains qui en découlent. Parfois positifs (accessibilité, changement des méthodes de travail), et trop souvent négatifs (santé mentale, isolement, fracture numérique), le smartphone a complètement changé nos modes de vie et nos habitudes.
Le tout, dans une ambiance conviviale, ouverte à toutes et tous, sans prérequis techniques. L’objectif n’est pas de culpabiliser, mais de comprendre ensemble et d’imaginer un numérique plus soutenable. Et pour celles et ceux qui voudraient prolonger la réflexion : tout le contenu de l’atelier est open source et libre d’accès sur GitHub.
L'aspirant chevalier LynxJS peut-il détrôner monseigneur React Native et le duc de Flutter ?
Présenté par Simon Bernardin - Mobiapps
Il existe déjà un grand nombre de frameworks multiplateformes promettant le Saint Graal : pouvoir déployer nos applications sur toutes les plateformes disponibles (android/ios/web/desktop) à partir d’une seule codebase.
Simon Bernardin, vêtu de son adorable armure et son heaume de guerre, vient alors nous présenter LynxJS, un nouveau framework cross-platform développé par ByteDance (le studio derrière TikTok), sorti le 5 mars 2025, qui cible Android, iOS, HarmonyOS et prochainement le web. Malgré son jeune âge, il est apparemment déjà utilisé par ByteDance en interne.
L'atout principal de LynxJS est son architecture à double thread automatique : le thread principal gère uniquement l'affichage tandis qu'un thread secondaire traite tous les calculs et interactions par défaut. Le framework utilise un moteur JavaScript développé spécifiquement pour le framework (Prim.js), écrit en Rust, et qui serait nettement plus rapide que ses concurrents (environ 28% plus rapide que QuickJS).
Simon termine sa présentation en définissant ses axes d’amélioration et ses points forts. En premier lieu, l’expérience développeur reste quasi inexistante sur la partie mobile avec beaucoup de choses manquantes : absence de gestion automatisée de la publication (tout doit être configuré manuellement par plateforme) et impossibilité d'utiliser des modules natifs existants, obligeant les développeurs à coder eux-mêmes les fonctionnalités natives.
Néanmoins, Il tenait à souligner les performances fluides "out of the box", la documentation qui est de qualité, ainsi que la compatibilité avec l'écosystème React permettant l'utilisation d'assistants/agents IA pour faciliter le développement.
C’est un aperçu intéressant que nous offre Simon ici bien que LynxJS reste très jeune et immature avec un écosystème limité, il mérite d'être surveillé grâce à ses promesses de performances tenues et l'écoute active de ByteDance vis-à-vis de la communauté.
SELECT 'amazing_features' FROM "postgresql"
Présenté par Kevin Davin - Gradle
Dans son talk, Kevin a mis en avant des fonctionnalités utiles, pratiques et souvent méconnues de SQL et de Postgres. L’objectif était de nous faire connaître ces features pour nous éviter de tout recoder “from scratch”.
Voici une liste non exhaustive de ces fonctionnalités:
- Les CTE (Common Table Expressions)
Leur usage améliore la lisibilité des requêtes en fragmentant les étapes. Dans certains cas, le plan d’exécution peut bénéficier d’une exécution parallèle et donc optimiser le temps d’exécution de la requête.
- Fonctions de fenêtrage (Window Functions)
Les window functions sont un outil SQL standard, qui permettent d’effectuer des calculs sur un ensemble de lignes liées à la ligne courante, sans regrouper les données comme avec GROUP BY. Un exemple courant est la déduplication via ROW_NUMBER().
Le mot-clé LATERAL permet de faire référence à des colonnes de la requête “parente” dans une sous-requête du FROM, ce qui ouvre beaucoup de possibilités (agrégations, appels de fonctions, filtrages dépendants).
Cela peut améliorer les performances en évitant des sous-requêtes coûteuses ou des jointures redondantes
L’ancienne pratique du SERIAL (auto-increment) continue d’exister, mais l’usage de UUID est recommandé pour certaines tables (notamment dans des environnements distribués ou microservices) pour éviter les attaques par énumération (si les identifiants sont séquentiels, un attaquant pourrait “deviner” des IDs).
PostgreSQL supporte nativement le type uuid et peut en générer via des fonctions intégrées comme gen_random_uuid() ou uuidv4().
Les contraintes (clé primaire, clé étrangère, contraintes de CHECK, contraintes d’unicité) sont essentielles pour protéger la cohérence et éviter la corruption de données.
Il vaut mieux s’appuyer sur les contraintes déclaratives du SGBD que sur du code applicatif pour valider la logique métier.
La commande NOTIFY permet de notifier d’un événement survenu dans la base de données. Il peut être accompagné du contenu de cet événement (le contenu d’un item qui vient d’être inséré en base par exemple). Il envoie cet événement à l’application qui a exécuté un LISTEN sur ce channel.
Les Foreign Data Wrappers permettent à PostgreSQL de consulter des sources externes comme s’il s’agissait de tables locales. Une table externe est créée et pointe sur la source externe. Cela permet d’exécuter facilement des opérations depuis Postgresql.
D’autres fonctionnalités peuvent permettre d’optimiser l’utilisation de votre moteur Postgresql (ltree, les types, jsonb pour stocker des données non structurées, … )
Let’s play Factorio - Ou “Comment j'ai appris à refactor mon code en jouant à Factorio”
Conférence présentée par Julien Wittouck
Julien utilise Factorio, un jeu d'automatisation industrielle, pour illustrer des concepts d'architecture logicielle. Dans ce jeu, le joueur doit construire des chaînes de production complexes pour transformer des ressources brutes en produits sophistiqués.
L'étape du PoC
Au départ, le joueur crée rapidement des usines reliées entre elles pour obtenir un résultat fonctionnel. On obtient vite du "code spaghetti" : un enchevêtrement chaotique difficile à comprendre et à faire évoluer.
Modularisation et isolation
En regroupant les usines par type de transformation, on crée des modules spécialisés qui alimentent les autres. Cette approche fait émerger des "couches" de responsabilités, comparable à une architecture en lasagne. Julien présente également les microservices via des drones autonomes qui transportent les ressources : excellente scalabilité (copier-coller de modules), mais problèmes d'observabilité avec des flux difficiles à suivre.
Urbanisation
Pour passer à l'échelle, on utilise des bus partagés auxquels se connectent les modules, permettant de déployer facilement des "quartiers" entiers (parallèle avec l'IaC). Julien illustre aussi les problématiques de sécurité (attaques aliens = cyberattaques) avec son "firewall" de tourelles lance-flammes, et l'importance de l'alerting via des sondes surveillant les débits et ressources.
On se rend bien compte dans cette conférence que le jeu vidéo permet d'expérimenter et visualiser des concepts architecturaux abstraits de manière ludique. Comme le dit Julien : "Je ne joue pas quand je fais du Factorio, je travaille" – les leçons tirées du jeu sont directement applicables à l'architecture logicielle.
Conclusion
Cette édition 2025 du DevFest Nantes aura été riche, inspirante et fédératrice pour nos Ippons. Ces deux jours nous ont permis d’explorer de nouvelles approches, de confronter nos pratiques et d’alimenter nos réflexions, autant sur les sujets techniques que sur l’impact de notre secteur. Nous repartons avec des idées concrètes à mettre en œuvre, des échanges qui continueront d’alimenter nos projets, et l’envie de faire grandir ces apprentissages au sein de nos équipes.Un grand merci à toutes celles et ceux rencontrés sur place pour leur énergie et leur curiosité. Nous avons déjà hâte de vivre la prochaine édition et de poursuivre ces discussions qui étaient, pour la plupart, légendaires !









Une journée à la première PlatformCon de Paris 24 Oct 12:30 AM (yesterday, 12:30 am)


Le Jeudi 16 Octobre 2025 avait lieu la très attendue première édition de la PlatformCon Live à Paris, premier événement organisé par l’Organisation Platform Engineering et nos collègues de chez WeScale, dédié au Platform Engineering en France. Ce sujet étant une de nos priorités depuis cette année, nous nous devions d’être de la partie, l’occasion de retrouver les amoureux du Platform Engineering. Chez Ippon Technologies, ce vaste sujet concerne tout nos corps de métier et ce faisant nous avions constitué une équipe de choc pour y participer, tous adeptes de la philosophie DevSecOps et une vision produit autour du Platform Engineering (Architecte Cloud & DevOps, ML Ops, Tech Lead Software Engineering, Coach Craftsmanship et notre Strategy Lead Platform Engineering). Le sujet de Platform Engineering ne se cantonne pas à nos collègues Ops (ou SRE, infra, DevOps Chapter, selon vos noms chez vous) mais bien à toute personne gravitant au sein d’une DSI pour construire les produits digitaux d'aujourd'hui et demain.

Le Platform Engineering, comme nous l’a présenté Luca Galante, contributeur principal de l’Organisation Platform Engineering, lors de la Keynote d’ouverture, a fortement progressé et s’est ancré de plus en plus dans la vie des entreprises tech, passant d’une composante dans les Hype Cycles (cycle des tendances) du Software Engineering d’après Gartner, à une évolution clefs de l’IT qui a son propre cycle de vie. Une statistique plus concrète: Gartner prévoyait une adoption du Platform Engineering chez 80% des entreprises tech d’ici 2026 et en fin de compte en 2025, 90% des entreprises ont entamé des démarches pour adopter ses pratiques d’après l’institut DORA (DevOps Research and Assessment).
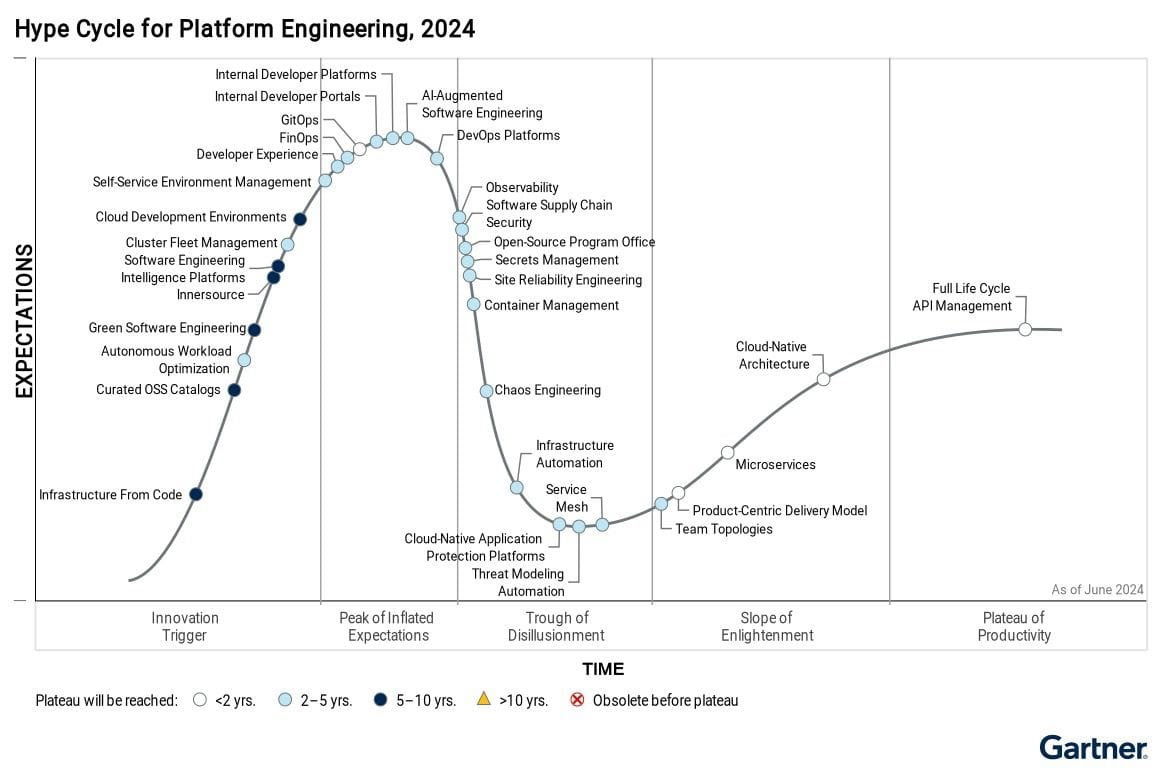
Si le Platform Engineering était d’abord une notion dédiée au développement logiciel, son impact avait l’air de s’étendre à d’autres horizons et de s’appliquer dernièrement à l’infrastructure, la data et encore l’IA. Le sujet de l’IA a forcément été abordé lors de cette Keynote et Luca Galante n’a d’ailleurs pas manqué de rappeler l’importance du Platform Engineering et de ses principes pour adopter correctement l’IA. La deuxième partie de la Keynote était présentée par Kelsey Hightower, ingénieur logiciel et conférencier. À travers son intervention, il a précisé un point que beaucoup de personnes se posent: non, le Platform Engineering n’est pas une invention de ces dernières années, c’est un nom qui a été apposé à une tendance qui existe depuis longtemps, la Plateformisation, mais qui n’avait jamais été correctement définie avant.
Ce que n’est pas la PlatformCon
Tout d’abord, ce n’est pas un rassemblement d’experts Unix, de mangeurs de hardware ou fanatiques de bare metal (même si une majorité en est passionnée). Il s’agit d’un rassemblement autour d’une vision partagée sur comment faire mieux dès demain en termes d’organisation de votre DSI.
Si vous attendiez d’avoir à PlatformCon la recette magique parfaite pour monter une Plateforme de développement interne ou de connaître la stack technique idéale pour la mettre en place alors vous serez déçu.
Une plateforme IT, la majorité des entreprises en possède une qui s’est construite au fil des 10 voir 20 dernières années avec ses évolutions majeures (l’arrivée de l’agilité, l’émergence de la virtualisation puis de la conteneurisation, l’avènement de la philosophie Cloud & DevOps qui s'orna du préfix Sec quelques années plus tard).
Ce qu’est la PlatformCon
C’est avant tout une journée où nous pouvons échanger sur nos expériences (réussites comme échecs) autour de la mise en place d’une plateforme. Peut-on considérer que la PlatformCon est aux DevOps ce qu’est DDD Europe au craftsmanship ?
Bien sûr, on va parler solution technique sur table pour accélérer la Plateformisation. Vous n’aurez jamais autant entendu le terme Kubernetes à une conférence … ou alors peut-être à la KubeCon 😀! Mais toujours avec un énorme panneau “warning”, vous indiquant d’être vigilant sur les technologies présentées car bien souvent, elles sont amenées dans un contexte particulier pour des besoins propres à l’entreprise (ne faites pas de Kubernetes si vous êtes au début de votre chemin pour la Plateformisation, baby step first).
Cette année, le focus a été sur des retours d’expérience de mise en place de Platform Engineering pour diverses entreprises avec chacune leur modèle (de la société offrant des service numériques, en passant par la banque, la plateforme data mais aussi la startup boostée par des investisseurs, etc…). Grâce à ce panel d’entreprises avec chacune leur stratégie d’évolution, leur budget, leur philosophie organisationnelle, on peut arriver à trouver des idées / similarités à notre entreprise et s’en inspirer pour à son tour se challenger et grandir.
Que faut-il retenir ? En bref
KISS: Keep it simple, stupid
Cet acronyme n’a jamais été aussi vrai. Tous les speakers qui sont intervenus sont alignés sur cette vision. Vouloir aller trop vite et trop complexe, dans le cadre de la mise en place d’une plateforme, est un échec assuré.
Tout d’abord, on commence par mettre à disposition des API Rest pour consommer les solutions et services. Même si pour certains cette étape est évidente, pour une majorité d’entre nous c’est un travail à mener (définir les bons contrats, identifier les services à exposer, prévoir de l’extension, adapter les outils aux usages des équipes, etc…). Si vous avez déjà un ensemble de services exposés par API au travers d’un point d’entrée unique (bien souvent une API Gateway), alors vous avez déjà acquis l’expérience pour avoir une vision produit de vos services, définir une organisation pour porter ces services et surtout acculturer et communiquer avec vos équipes pour l’usage et l’évolution de ce premier layer de votre plateforme.
Ensuite, on peut se poser la question de monter une IHM (Interface Homme Machine) pour améliorer la DevX (developer experience). Encore une étape pour faire grandir votre SI avec des questions comme:
- Ai-je un Design System pour accélérer sa mise en place ?
De nombreux Design Systems existent en opensource et peuvent être des accélérateurs avant même de construire le vôtre.
- Quelle structure d’équipe pour ce type de projet ?
Un product owner (celui de votre plateforme), 2 à 3 développeurs est un bon début pour monter ce produit.
- Comment mesurer la satisfaction et l’amélioration de la DevX ?
On évite de se lancer à corps perdu dans les métriques DORA dès le début (de nombreux REX en parlent). On peut commencer KISS (Keep It Simple and Stupid) avec le Squad Health Check de Spotify. On rencontre les équipes une fois par mois par exemple (pas trop souvent) et on leur demande leurs pain points concernant la Plateforme, leurs besoins, etc…
Créer une plateforme sans jamais échanger avec les équipes qui l'utilisent, sans leur proposer d’y participer (contribution interne, ouverture des dépôts de code) est un échec assuré. Profitez de vos équipes d’expertise technique (DevEx team, enabler team, coach interne) pour évangéliser les équipes à l’usage de votre Plateforme.
Eat your own food
Encore merci Mirakl pour cette citation qui est forte en sens. Il est important que vos équipes en charge de la plateforme soient les premières à s’en servir. Ils sont les mieux placés pour critiquer les produits proposés. Et on en revient à l’idée de l’inner sourcing avec la facilitation des évolutions par la contribution interne sur les bases de vos standards à vous. Votre plateforme reflète vos standards techniques.
L’expérimentation ne s’arrête jamais
Il ne faut pas craindre les échecs car ils sont toujours instructifs et la courbe d’apprentissage de la Plateformisation n’est pas linéaire. La Plateformisation est un excellent moyen d'expérimenter au sein de votre SI de nouvelles méthodologies, pratiques (ex: mise en place de feature flipping, rollout gateway, fine-tuning kafka), outils etc …
Vigilance sur l’usage de l’IA
Mais alors, le big boss final de la plateforme, c’est la mise en place d’un chatbot sur notre plateforme ou d’un agent de Plateformisation ? La réponse est claire et concise: NON.
On en revient à notre KISS, mais il est impératif de savoir faire une Plateforme avec votre vision et qui apporte de la valeur à vos équipes avant de vouloir l’enrichir avec de l’IA. On n’investit pas sur un agent IA plateforme avant même d’avoir créé sa plateforme. La plateforme se veut être un accélérateur fournissant un ensemble de guidelines, golden path, documentation avant tout. Il ne doit en aucun cas être un enjeu pour faire de l’IA. L’IA peut enrichir votre produit si vous êtes mature sur le sujet et des speakers ont indiqué se lancer sur ce sujet avec des use cases identifiés chez eux.
Comme disait Kelsey Hightower lors de la Keynote, si c’est pour faire un agent IA qui reset votre mot de passe, alors qu’un simple clique sur un reset est possible et que derrière cela vous demande une usine à gaz pour rattraper l’aspect non déterministe de l’IA, alors vous allez dans le mur.
Un alignement existe tout de même sur l’idée d’utiliser l’IA afin d'accélérer l'accès à de la documentation et simplifier la rédaction de documentation. C’est là où est la force de l’IA (et surtout du NLP), grâce à elle, il est possible de répondre rapidement aux besoins d’un développeur concernant la plateforme sur la base d’un agent conversationnel. Mais soyez conscient qu’il faut garder un système de débrayage avec des équipes de supports accessibles par divers canaux (ticketing via Jira, thread via Slack ou Teams, etc…).
Un aperçu de nos conférences préférées
Pour ceux d’entre vous qui souhaiteraient avoir un petit résumé des conférences que nous sommes allés voir, nous y consacrons cette section.
Platform Engineering à but non lucratif : leçons des Restos du Cœur - Julien Briault - Deezer
Julien Briault est un des speakers ayant été présent sur de nombreuses conférences en France en cette année 2025, nous avions déjà pu le voir présenter son magnifique sujet à des conférences comme Touraine Tech en février de cette année.
Ce premier talk de la journée a été une leçon d’humilité pour nous face à l’implication de Julien Briault, SRE chez Deezer mais aussi bénévole chez les Restos du Coeur. Julien est venu présenter son projet Cloud du Coeur, le Cloud privé des Restos du Coeur qu’il met en place depuis 4 ans afin de permettre à l’association et ses 78 000 bénévoles d’accéder aux outils numériques indispensables pour assurer leur mission tout en permettant à l’association d’économiser de précieuses ressources financières afin de fournir plus de repas au plus démunis. Un très beau projet qui allie technologie et social, merci Julien pour ce talk et bravo à toute ton équipe.

Platform as a product: Il faut savoir (parfois) réinventer la roue - Romain Broussard - Mirakl
Dans cette présentation, Romain Broussard, VP Platform Engineering (un intitulé de poste pas commun en France) chez Mirakl (éditeur de logiciel français) nous présente l’approche qu'il a eu lors de la mise en place de son équipe Plateforme et pose notamment l’accent sur l’approche produit qu'il faut avoir dans cette situation. En effet, de nombreuses entreprises font l’erreur de ne se concentrer que sur l’aspect technique du Platform Engineering sans aborder les vrais problèmes des structures. L’équipe Plateforme de Mirakl a mis en place une portail interne de développement mais Romain nous met en garde: nous pouvons avoir tendance à vouloir mettre en place un IdP(Internal Development Portal) directement en utilisant des projets comme Backstage de Spotify par exemple mais ceux-ci sont très complexes à mettre en place et il est préférable de d’abord exposer les services que l’on souhaite via des API par exemple, les mettre à disposition des développeurs avant de vouloir forcément une interface graphique. Si je devais retenir 2 leçons de cette conférence très intéressante : APIser d’abord et être soi même client de sa Plateforme pour pouvoir l’améliorer.
Construire une Plateforme d’ingénierie dans un groupe en pleine transformation : retour d’expérience - Florian Gasnier, Michaël Fery - Meilleurtaux
Chez Meilleurtaux, acteur du courtage en placement, assurance et crédit, l’hétérogénéité des équipes et l’absence de standards Dev, Sec et Ops freinaient l’innovation. Pour y remédier, l’entreprise a créé une équipe plateforme from scratch, combinant prestataires et recrutements internes, et impliquant l’ensemble des équipes infra, Ops, Sec et Dev.
Chaque squad dispose d’un champion DevSecOps, un Golden Path guide les développeurs, et l’architecture Hub & Spoke sécurise les environnements via des Landing Zones. L’objectif : réduire le Time to Cloud tout en garantissant sécurité et qualité.
Les bénéfices sont tangibles : autonomie accrue, déploiements plus rapides et sécurisés, meilleure visibilité sur les coûts et accès aux nouvelles fonctionnalités. Les défis restent la résistance au changement et la dette technique héritée.
Pour l’avenir, Meilleurtaux prévoit extension vers le cloud et la data, sandbox d’expérimentation, standardisation et suivi des métriques DORA et FinOps, tout en continuant l’onboarding de nouvelles squads.
Cloud Pi Native : Le Platform Engineering construit en OpenSource pour les ministères publics - Akram Blouza, Brice Trinel, Mathieu Laude - Ministère de l’intérieur
Conçue au sein du ministère de l’Intérieur, Cloud Pi Native illustre la montée en puissance du Platform Engineering dans le secteur public. Née d’un simple besoin de simplifier le déploiement d’applications, la Plateforme est devenue un produit stratégique, capable d’héberger des projets critiques tels que le Système d’Immatriculation des Véhicules (SIV) ou des applications interministérielles (Intérieur, Armées, Justice).
Dans la continuité de la stratégie cloud de l’État (2021), Cloud Pi Native s’inscrit dans une logique de souveraineté numérique et de maîtrise des infrastructures. Elle repose uniquement sur des briques open source et s’intègre dans l’écosystème des clouds souverains internes (Cloud Pi, Nubo) et des clouds de confiance (S3NS, Scaleway).L’objectif : conjuguer agilité, sécurité et indépendance tout en respectant les exigences réglementaires et les niveaux de confidentialité (jusqu’au niveau Diffusion Restreinte).
Cloud Pi Native offre un ensemble de services pour accélérer le time-to-market, mutualiser les ressources et améliorer la satisfaction des utilisateurs. Selon le degré d’intégration, les équipes ministérielles peuvent déployer leurs applications plus rapidement et en toute autonomie, tout en conservant un haut niveau de gouvernance et de sécurité.
Les prochaines évolutions incluent :
- Un catalogue de services (“Golden Path”) pour guider les équipes projets.
- Le soutien aux projets d’intelligence artificielle (gestion de GPU).
- Des plugins spécialisés, comme OpenCDS pour l’automatisation DNS.
Avec déjà 30 projets en production et plus de 100 agents formés, Cloud Pi Native s’impose comme un levier de modernisation et un vecteur de souveraineté numérique.Abstraction, standardisation, self-service, observabilité et sécurité by design : cette Plateforme open source incarne une nouvelle génération d’infrastructures publiques, pensées pour l’efficacité et la confiance.
“Platform Engineering is not about saving money, it is about making money" : Vers une Plateforme interne rentable chez Bpifrance - Hela Ben Farhat - BPI France
Hela Ben Farhat, Product Manager chez BPIfrance, aborde un sujet incontournable lorsqu’on met en place une équipe plateforme, c’est sa rentabilité par rapport aux équipes métier. Chez Bpifrance Digital, le Platform Engineering est désormais perçu comme un levier économique majeur, surpassant le statut de simple centre de coût. S'inspirant de l'impact de la machine à laver sur l'économie du 20e siècle, qui a libéré du temps pour l'innovation, la plateforme a pour mission de libérer les développeurs pour l'accélération et la créativité. Architecturalement, la plateforme est le cœur numérique, positionné entre les fondations (infrastructure Cloud, services internes) et les Produits Digitaux Métiers (parcours clients, demandes de financement). Conçue pour être générique, réutilisable et exposée via API, elle remplit une double fonction: elle est une couche d'abstraction masquant la complexité des fondations, et une couche d'accélération pour les équipes de développement.
Pour prouver cette valeur stratégique et répondre aux doutes initiaux des décideurs, Bpifrance s'appuie sur le calcul du ROI. Actuellement, la Plateforme affiche une rentabilité de 300 %, soit 3 € gagnés pour chaque euro investi. L'ambition est d'atteindre 5 € pour 1 € d’ici deux ans. Ce gain se décompose en trois familles : les économies de réutilisation, les gains de productivité, et les gains business (réduisant le time-to-market pour certains produits d’un an à trois mois). Au-delà de ces métriques quantifiables, la démarche intègre l'impact des gains invisibles, tels que la fidélisation client et l'amélioration de l’expérience développeur, qui ne figurent pas dans les calculs mais renforcent la performance globale de l’entreprise.
La pérennisation de ces bénéfices repose sur trois piliers fondamentaux. Le premier est le maintien d'un modèle économique lisible ; le second est une approche produit proactive qui se concentre sur le consommateur (le développeur) via le continuous discovery, visant à abandonner la "feature factory" pour prioriser les sujets alignés sur les enjeux business. Le troisième pilier est l’excellence opérationnelle, essentielle pour garantir la robustesse, la performance et la sécurité de la Plateforme.
Malgré ces succès, des défis persistent, notamment la nécessité d'une transformation culturelle vers un état d’esprit "produit" au sein des équipes, et la fiabilisation des mesures (acceptant l'imprécision des gains de productivité). À l'avenir, Bpifrance mise sur l'intégration de l'IA et des Plateformes "Agentic" pour orchestrer des agents, automatiser des chaînes de valeur entières et démultiplier l'innovation.
Conclusion
Cette journée à la PlatformCon aura été riche en informations et retours d’expériences. Nous avons déjà hâte d'assister à la prochaine édition.
%20720px%22%20/%3E%3C/figure%3E%3Cp%3ELe%20Jeudi%2016%20Octobre%202025%20avait%20lieu%20la%20tr%26%23xE8;s%20attendue%20premi%26%23xE8;re%20%26%23xE9;dition%20de%20la%20PlatformCon%20Live%20%26%23xE0;%20Paris,%20premier%20%26%23xE9;v%26%23xE9;nement%20organis%26%23xE9;%20par%20l%26%23x2019;Organisation%20Platform%20Engineering%20et%20nos%20coll%26%23xE8;gues%20de%20chez%20WeScale,%20d%26%23xE9;di%26%23xE9;%20au%20Platform%3C/p%3E)
Une journée au salon de la data et de l'IA de Nantes 2025 22 Oct 3:44 AM (3 days ago)

Mardi 16 septembre dernier, notre équipe Ippon était de retour pour les 10 ans du Salon de la Data et de L’IA de Nantes. Cet événement phare de la place nantaise nous permet de nous informer sur les dernières tendances et de renforcer nos liens avec la communauté tech.
Voici un résumé de quelques conférences auxquelles nous avons assisté.
Datawalk : voyage aux sources de la donnée !
Chose étonnante, Zazie Casimir-Favrot et Matthieu Chatry nous ont donné rendez-vous non pas dans une salle, mais sur l'esplanade de la Cité des Congrès. Au programme de cet atelier : une promenade dans le quartier.

La Datawalk, ou promenade de données, est un concept venu de Belgique. Il s'agit d'une visite guidée qui vise à nous faire (re)découvrir le mobilier urbain devenu invisible dans notre quotidien, mais dont la composante numérique améliore notre vie de tous les jours.
Le premier arrêt nous a conduits devant une station de vélos en libre-service Naolib. Un employé de JCDecaux, la société exploitante, nous a expliqué son fonctionnement et les données collectées. Ils sont capables de savoir si un vélo est amarré à une station ou s'il est en cours d'utilisation. Cela leur permet de connaître la fréquentation des stations pour optimiser la redistribution des vélos, améliorer le maillage des stations et rendre des comptes à la Métropole. Mais n'ayez crainte, les vélos ne sont pas géolocalisés et JCDecaux prend la RGPD au sérieux : les trajets non facturés (d'une durée inférieure à 30 minutes) sont anonymisés, et ceux qui sont facturés sont purgés au bout de 3 ans.
La balade nous a ensuite menés devant un guichet automatique de banque (GAB) du CIC, où une employée du groupe Société Générale nous a livré quelques anecdotes. Une employée de la Société Générale devant un CIC, n'y a-t-il pas là un problème ? Pas quand on sait que les GAB des banques BNP Paribas, Crédit Mutuel, CIC et Société Générale seront tous regroupés sous la marque Cash Services.
Prochain arrêt : une station d'autopartage Marguerite. Ces voitures sont truffées de capteurs et, à la différence des vélos, elles sont géolocalisées, mais pas en temps réel.
Le quatrième arrêt nous a conduits dans une pharmacie. La pharmacienne nous a fait une démonstration de son robot préparateur. En plus de préparer les commandes, cette énorme machine, constituée d'un grand couloir bordé de deux étagères, range et indexe automatiquement les médicaments. Ainsi, les médicaments souvent prescrits ensemble sont colocalisés pour optimiser les déplacements. De plus, il gère seul les dates de péremption afin de limiter les pertes.
Nous avons terminé cette DataWalk par une touche culturelle, devant le Grenier du Siècle. Ce lieu est une gigantesque capsule temporelle où les Nantais ont déposé des objets en 1999, à destination de leurs descendants de 2100.
Cet atelier était une bouffée d’air (pur ?) parmi toutes les conférences sur l’IA générative et ses agents.
Shadow AI: Le paradoxe de la Reine rouge
Dans ce quickie Angéline Perennes et Mourad Bouallak nous parlent de l’utilisation de l’IA générative en entreprise.
Le «Shadow AI» désigne l’utilisation de l’intelligence artificielle en dehors du cadre autorisé ou défini par l’entreprise. Un phénomène de plus en plus fréquent, porté par la curiosité, le besoin de productivité et l’accessibilité des outils d’IA générative.
Ce constat fait écho au paradoxe de la Reine Rouge, tiré d’Alice au pays des merveilles : dans un monde où tout évolue très vite, rester immobile revient à reculer. Pour les entreprises, interdire purement et simplement l’usage de l’IA reviendrait à se mettre en retrait, au risque d’être dépassées par les concurrents.

Il devient donc essentiel de proposer un cadre clair, qui permette de profiter des avantages de l’IA (gain de temps, automatisation, assistance à la création, etc.) tout en limitant les risques. Ces risques sont bien réels : près d’un prompt sur douze contient des données sensibles, exposant les organisations à des violations du RGPD ou à des pertes de propriété intellectuelle.
Refuser l’usage de l’IA sans alternative crée souvent de la frustration chez les employés, qui chercheront à contourner les interdictions. La réponse n’est donc pas l’interdiction, mais la formation.
Des programmes comme Objectif IA (OpenClassrooms) permettent de sensibiliser les collaborateurs à un usage responsable et maîtrisé de ces outils, tout en accompagnant l’évolution rapide des pratiques professionnelles.
Table Ronde : L’IA au féminin en 2025
En début d’après-midi s’est tenue une table ronde d’une trentaine de minutes sur un sujet encore peu abordé lors du salon : la place des femmes dans le domaine de la data et de l’IA. Trois intervenantes aux parcours inspirants ont échangé sur leurs expériences, leurs visions du secteur et les défis, techniques comme moraux, auxquels elles ont fait et font toujours face en tant que femmes dans la tech.
Andrea Leylavergne, data scientist et directrice de l’association Women in Big Data, a ouvert le débat. Engagée depuis plusieurs années dans la promotion des carrières féminines dans la tech, elle milite pour une meilleure visibilité des femmes dans la data. Pour elle, la représentation est le premier levier de transformation pour que les choses évoluent dans le bon sens. Son action au sein de l’association vise justement à présenter des modèles auxquels les jeunes femmes peuvent s’identifier, en mettant en avant des parcours variés et ambitieux.
Parmi ces modèles, certaines femmes se montrent plutôt optimistes quant à l’avenir du féminin dans la tech, convaincues que les choses progressent. C’est le cas de Camille Marini, docteure en océanographie dynamique et aujourd’hui Director of Machine Learning chez Sonos. Pour elle, l’enjeu est avant tout d’encourager les étudiantes à se faire confiance et à oser les carrières techniques.
Plus tranchée dans ses propos, Fransceca Iannuzzi, Head of Data chez iAdvize, a évoqué sans détour les obstacles quotidiens rencontrés dans un milieu encore largement masculin. Elle raconte même, avec une pointe d’ironie, un épisode de mansplaining qu’elle a vécu à peine trente minutes avant le début de la table ronde. Il s’agit de ces situations dans lesquelles un homme explique à une femme quelque chose qu’elle sait déjà, voire dont elle est experte, souvent sur un ton paternaliste ou condescendant.

De ces échanges, un message clair ressort : les femmes ont toute leur place dans la data et l’IA, mais la bataille n’est pas que technique. La compétence n’a pas de genre, mais la confiance, elle, se construit. Comme le souligne Fransceca, il faut « redistribuer les cartes dès la crèche » : donner aux petites filles des modèles inspirants et apprendre aux petits garçons à écouter, à collaborer, à co-construire. Le débat s’est conclu sur une note d’espoir pour tous : quel que soit le genre ou le milieu social, l’essentiel est d’oser et d’y croire.
Lien vers les articles des années passées:
Une journée au salon de la data 2022
Une journée au salon de la data et de l'IA 2023
Une journée au salon de la data et de l'IA 2024
L’IA au cœur de la Data Cloud : Révolution et Simplicité au Snowflake World Tour 2025 20 Oct 4:05 AM (5 days ago)
Keynote : L’IA, fil rouge d’une plateforme en mouvement

L’édition 2025 du Snowflake World Tour a placé l’intelligence artificielle au centre de toutes les discussions. Mais au-delà du simple buzzword, c’est une vision stratégique et opérationnelle qui s’est dessinée, une déclaration d'une ambition dévorante : transformer Snowflake d'une Data Cloud Platform en une "AI Data Cloud Platform". Cette refonte se concrétise par une plateforme unifiée, conçue pour simplifier radicalement l’accès à la data et à l’IA, tout en renforçant la confiance dans les résultats. La keynote, animée par des figures telles que Cecil Bove, Regional Vice President de Snowflake et Sridhar Ramaswamy, CEO de Snowflake, a posé les fondations d’un écosystème où la complexité technique s’efface au profit de la puissance et de l’accessibilité.
La simplicité a été érigée en différenciateur majeur face à la concurrence. Là où d’autres acteurs multiplient les fonctionnalités au risque de fragmenter l’expérience utilisateur, Snowflake mise sur une intégration native et fluide entre le cloud, la data et l’IA. Cette philosophie a été illustrée par un partenariat stratégique mis en scène avec le CEO d’Azure, Satya Nadella. Si les détails opérationnels de cette collaboration restent à préciser, elle symbolise une alliance forte dans un paysage cloud où les frontières, entre partenariat et concurrence, deviennent poreuses.
Une démonstration captivante est venue d’Hugo Barret, Solution Engineering Manager chez Snowflake, qui a présenté les nouvelles fonctionnalités avec un leitmotiv : faire de Snowflake une plateforme autonome et fiable. La gouvernance de l’IA a été placée au premier plan, comme un pilier essentiel pour garantir la transparence et la fiabilité des modèles génératifs. Pour soutenir cette ambition, la couche sémantique a été présentée comme le socle de l’IA générative, structurant les données de manière intelligible et ouvrant la voie à des outils comme Horizon Agent, dédiés aux Data Stewards. L’annonce d’un format généralisé, Open Semantic Interchange marque concrètement les intentions de Snowflake.
L’annonce la plus marquante restera sans doute Snowflake Intelligence : un chatbot métier capable d’interroger les bases de données en langage naturel, sans requête SQL. Une révolution pour les utilisateurs non techniques, qui pourront désormais exploiter la data via de simples prompts. Cette démonstration, enrichie par l’intervention d’Elizabeth den Dulk, Enterprise Solution Engineer chez Snowflake, a montré comment l’IA s’intègre désormais directement dans les pipelines, permettant de traiter aussi bien des données structurées que non structurées, comme des transcriptions audio ou des analyses d’images.
La keynote s'est conclue par un retour d'expérience concret de TF1, représenté par son Chief Data Officer, François-Xavier Pierrel. Il a détaillé le virage data du groupe pour soutenir sa transition vers le streaming (TF1+), gérant des volumes de données importants pour personnaliser l'expérience de millions d'utilisateurs. Son mot de la fin, à la fois drôle et décalé, a offert un moment de légèreté : « Ce n’est pas grave de rater, il faut juste que cela arrive une fois ». Une conclusion qui, à contre-courant du "fail fast" habituel, a rappelé avec humour que l'innovation, si elle comporte des risques, doit avant tout mener à un succès durable.
Conférences : Retours d’expérience et visions d’avenir
Au-delà de la keynote, plusieurs retours d’expérience ont illustré la maturité croissante de la plateforme.
L’intervention de Saint Jean, groupe agroalimentaire historique, a illustré comment une migration vers Snowflake, facilitée par l’outil Coalesce et son interface no-code, a permis de transformer une culture data encore émergente en une véritable capacité industrielle. En passant de plus de 30 rapports statiques à seulement deux rapports dynamiques, l’entreprise a non seulement regagné la confiance des métiers, mais aussi accéléré son time-to-value. Le choix de Coalesce, pour son interface visuelle et son intégration native, a été crucial pour une équipe initialement dépourvue de data engineers experts.
Le cas Stellantis a, quant à lui, impressionné par son ampleur. Face à un héritage technique complexe – 16 plateformes data distinctes – le constructeur automobile a su unifier son paysage autour de Snowflake, en s’appuyant sur une stack moderne intégrant dltHub et dbt. Leur framework open source, couplé à un monitoring maison basé sur Elastic, leur permet de gérer des milliers de pipelines et une centaine de développeurs avec une rigueur remarquable. L’utilisation des Data Metric Functions (DMF) de Snowflake pour piloter la qualité des données à grande échelle témoigne d’une vision résolument industrielle.
Enfin, la conférence dédiée à l’interopérabilité avec le format Apache Iceberg a confirmé la volonté d’ouverture de Snowflake et sa stratégie pour éviter le vendor lock-in. Grâce à des innovations comme l’intégration de catalogues externes (tel que Polaris, le catalogue open source de Snowflake) et la possibilité d’écrire directement dans des tables Iceberg, la plateforme permet de séparer le stockage des données du moteur de calcul, tout en conservant la scalabilité et la performance du compute Snowflake.
Conclusion : Vers une plateforme data auto-suffisante ?
Cette édition du Snowflake World Tour a confirmé une ambition claire : faire de Snowflake une plateforme tout-en-un, où l’IA, la data et le cloud s’intègrent de manière fluide et accessible. Les annonces vont toutes dans le même sens : réduire la complexité pour les utilisateurs métiers, automatiser les tâches techniques et intégrer l’IA non comme une couche supplémentaire, mais comme un levier de productivité native.
Cette évolution interroge néanmoins les rôles traditionnels. L’émergence d’outils comme Snowflake Intelligence et la couche sémantique pourrait bien redistribuer les cartes, faisant évoluer le métier de Data Analyst vers des profils plus spécialisés, comme le Data Steward, garant de la qualité et de la cohérence sémantique.
Si la vision de Snowflake se concrétise, la plateforme pourrait bien s’imposer comme la référence incontournable pour les entreprises cherchant à unifier leur stack data, sans pour autant renoncer à la puissance et à l’expertise technique offerte par des écosystèmes ouverts et interopérables.
GraphRAG - Augmenter la puissance de votre RAG avec L’intégration Neo4J 17 Oct 12:51 AM (8 days ago)
Introduction & Motivation

Cela fait plusieurs semaines que j’ai booké une session “lab / discovery” sur le sujet des RAG mais abordé par le prisme d’une technologie particulière : Neo4J.
Neo4J, c’est le leader de la base graphe. C'est un outil particulièrement adapté aux nouveaux enjeux technologiques dans lesquels on manipule des données pas forcément structurées. Ayant déjà utilisé Neo4J plusieurs années auparavant, je me souvenais d’un outil abouti et vraiment performant. Et c’est donc tout naturellement que j’ai voulu participer à ce Lab pour voir où se situait Neo4J dans la galaxie des outils qui gravitent dans l'écosystème LLM / IA.
En voici une synthèse.
Présentation & Déploiement moteur Neo4J
Après la classique présentation de la société Neo4J, du principe des bases graphes, et pourquoi c’est bien de l’utiliser, on nous présente “Neo4j Aura Professionnal” qui est la solution SaaS de Neo4J et qui se décline en plusieurs briques :
- Neo4J Aura DB qui est le moteur de la base graphe
- Neo4j Aura Graph Analytics
Evidemment, Neo4j Aura Professionnal est indépendant du cloudProvider : on va donc pouvoir l’installer sur les grands fournisseurs de cloud, et ce, en quelques clics. Mais il est également possible de faire du self managed.
Le Lab (et tout ce qui est nécessaire) est accessible depuis le github de Neo4J :
https://github.com/neo4j-partners/hands-on-lab-neo4j-and-bedrock/tree/main
La formation se déroulant dans les locaux d’AWS, il était normal que le choix du cloudProvider soit AWS. Les premières étapes consistent à déployer sur un compte AWS de “bac à sable” une instance du moteur neo4j. Comme c’est une solution SaaS, complètement intégrée dans l’AWS Marketplace, cela se fait très facilement :
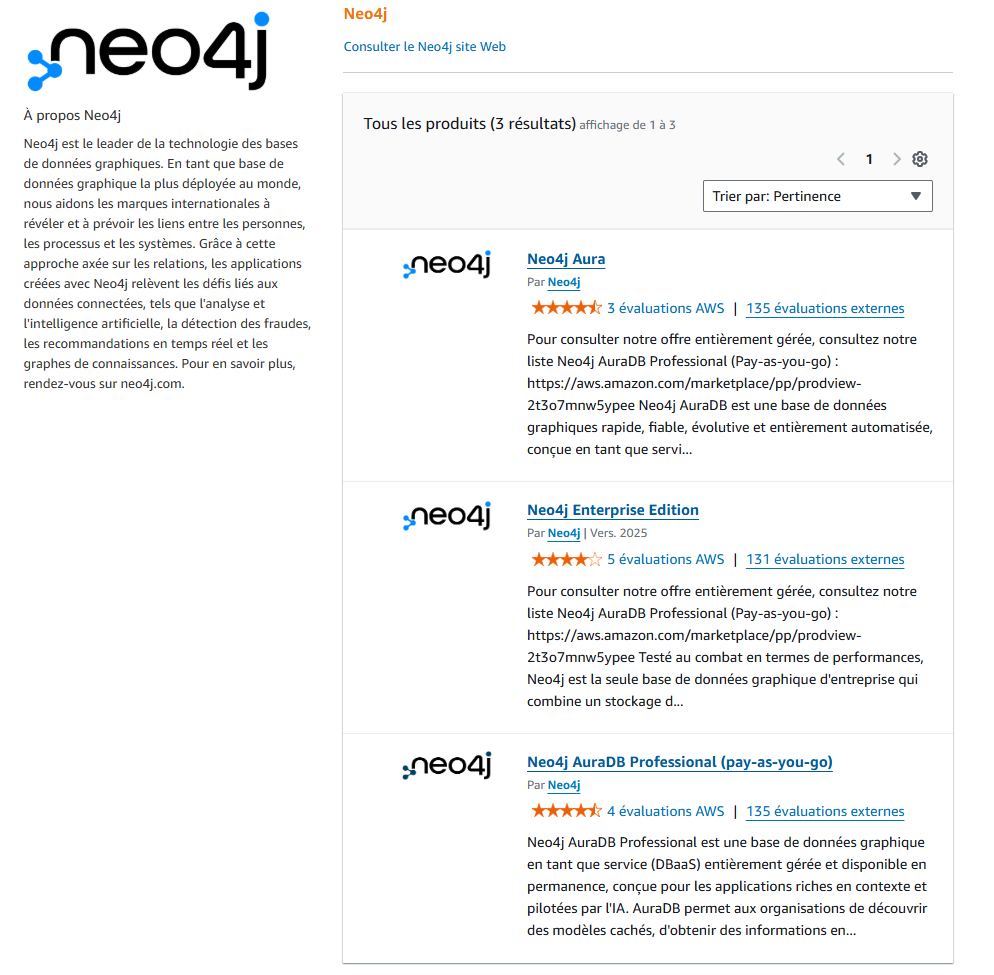
Notez qu’il faudra sélectionner à minima “Neo4J AuraDB Professionnal (pay as you go)” pour bénéficier des fonctionnalités IA.
Notez également que le système de Licensing Neo4J n’autorise pas à déployer en production la version communautaire, qui est de toute façon bridée.
Pour vos productions, il faudra sélectionner “Neo4J Enterprise Edition”.
Une fois déployée, nous nous connectons sur l’interface via la console d’administration :
Puis nous enchaînons sur une étape de création de la base graphe à l’intérieur de notre instance. Et enfin, nous la remplissons.
L’ensemble de ces étapes sont très bien décrites dans le repo github.
L’IA rentre en jeu
Un SA AWS nous présente le service AWS BedRock et les différents modèles qu’il supporte.
Ce n’est pas l’objet de ce billet mais voici quelques notes :
Amazon BedRock est une surcouche au-dessus des modèles que vous aurez sélectionnés. Je citerai juste ce que le SA AWS nous a conseillé : “Dans votre phase exploratoire, n’hésitez pas à tester les différents modèles : entre pertinence et coûts associés, trouvez le modèle qui correspond le plus à vos besoins.”
Ici, nous utilisons Anthropic et le modèle claude-sonnet-4-20250514-v1 comme LLM.
Pour terminer notre environnement, nous déployons, côté AWS, un domaine “SageMaker” pour dérouler les notebooks Jupyter fournis dans le repository git.
Le 1er notebook Jupyter : chargement des données
Voici les grandes lignes du notebook :
Objectif : Utiliser le LLM claude sonnet pour parser automatiquement des données semi-structurées (mélange de texte et XML) issues d’un fichier initial.
Le notebook permet de montrer comment générer des requêtes Cypher (langage natif neo4j pour interagir avec la base graphe) pour charger les données extraites dans notre base neo4J. Notez qu’à aucun moment on écrit un parser spécifique : c’est le LLM qui se charge de tout.
Le notebook utilise des prompts spécifiques pour guider le LLM dans l’extraction des informations. Dans notre cas particulier, nous manipulons des “managers” et des informations sur des “investments”. Voici les prompts (que vous pouvez retrouver directement dans le notebook).
Prompt pour guider le LLM pour extraire les informations “manager”
mgr_info_tpl = """From the text below, extract the following as json. Do not miss any of these information.
* The tags mentioned below may or may not namespaced. So extract accordingly. Eg: <ns1:tag> is equal to <tag>
* "managerName" - The name from the <name> tag under <filingManager> tag
* "street1" - The manager's street1 address from the <com:street1> tag under <address> tag
* "street2" - The manager's street2 address from the <com:street2> tag under <address> tag
* "city" - The manager's city address from the <com:city> tag under <address> tag
* "stateOrCounty" - The manager's stateOrCounty address from the <com:stateOrCountry> tag under <address> tag
* "zipCode" - The manager's zipCode from the <com:zipCode> tag under <address> tag
* "reportCalendarOrQuarter" - The reportCalendarOrQuarter from the <reportCalendarOrQuarter> tag under <address> tag
* Just return me the JSON enclosed by 3 backticks. No other text in the response
Text:
$ctext
"""
Prompt pour guider le LLM pour récupérer les infos “investments”
filing_info_tpl = """The text below contains a list of investments. Each instance of <infoTable> tag represents a unique investment.
For each investment, please extract the below variables into json then combine into a list enclosed by 3 backticks. Please use the quoted names below while doing this
* "cusip" - The cusip from the <cusip> tag under <infoTable> tag
* "companyName" - The name under the <nameOfIssuer> tag.
* "value" - The value from the <value> tag under <infoTable> tag. Return as a number.
* "shares" - The sshPrnamt from the <sshPrnamt> tag under <infoTable> tag. Return as a number.
* "sshPrnamtType" - The sshPrnamtType from the <sshPrnamtType> tag under <infoTable> tag
* "investmentDiscretion" - The investmentDiscretion from the <investmentDiscretion> tag under <infoTable> tag
* "votingSole" - The votingSole from the <votingSole> tag under <infoTable> tag
* "votingShared" - The votingShared from the <votingShared> tag under <infoTable> tag
* "votingNone" - The votingNone from the <votingNone> tag under <infoTable> tag
Output format:
* DO NOT output XML tags in the response. The output should be a valid JSON list enclosed by 3 backticks
Text:
$ctext
"""
La variable $ctext sera remplacée par chaque ligne récupérée du fichier initial.
Le notebook fournit des fonctions spécifiques permettant d’interagir avec le LLM, comme par exemple le moyen de découper (chunk) les données pour éviter de dépasser les limites de tokens du LLM.
Le LLM est utilisé pour générer des requêtes Cypher à partir des données extraites, afin de les charger dans Neo4j.
Conclusion
Même si ce n’est pas une révolution, on sent bien toute la puissance du LLM : à partir d’un fichier non structuré (le fichier de départ contient des données XML et des données en vrac), le LLM arrive à ne pas se perdre et à extraire les 2 listes d’informations relatives à des entités métier : le manager et le “investment”.
Mise en place d’une “fenêtre conversationnelle”
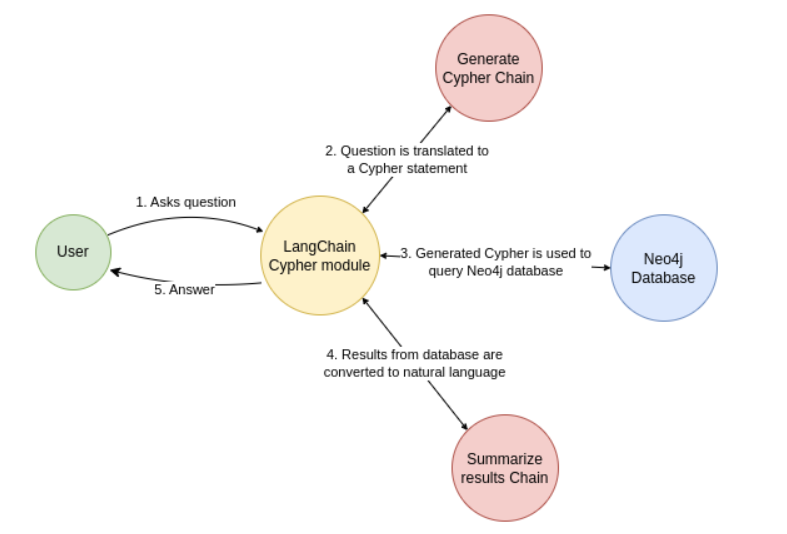
La session continue sur le lab 6 “ChatBot”. Il se base sur la librairie python “gradio” pour mettre en place cette fenêtre conversationnelle.
Le fonctionnement qui est proposé par ce nouveau notebook est le suivant :
- L’utilisateur pose une question en langage naturel.
- L’IA générative convertit cette question en requête Cypher (langage de requête pour Neo4j).
- La requête Cypher interroge la base Neo4j pour obtenir des faits contextuels.
- L’IA générative convertit la réponse de la base en langage naturel.
- La réponse est présentée à l’utilisateur.
Dans ce notebook, on nous présente l’avantage de l’utilisation de Neo4J. Sans précision particulière, une question du style : “Which managers own FAANG stocks?” ne permet pas d’avoir une réponse pertinente.
En effet, un modèle de langage (comme ceux utilisés dans les chatbots) peut reconnaître des termes courants comme FAANG (Facebook, Apple, Amazon, Netflix, Google ), mais il ne donnera que des réponses générales et limitées.
Or, dans un environnement professionnel, les questions portent souvent sur des données spécifiques : des noms de projets, des relations entre entités, ou des règles internes. Un LLM seul ne connaît pas ces détails. Neo4j résout ce problème en stockant ces informations dans un graphe de connaissances, où chaque élément est relié de manière structurée.
Grâce à LangChain, on peut alors :
- Traduire la question en une requête précise (en langage Cypher pour Neo4j).
- Interroger la base pour obtenir des réponses exactes et contextualisées.
- Restituer le résultat en langage naturel, comme le ferait un expert du domaine.
C’est cette combinaison — LLM + Neo4j — qui permet de passer d’une réponse vague à quelquechose de beaucoup plus pertinent pour notre contexte.
Voici le schéma présenté dans le notebook :
Pour permettre au LLM de traduire la question de l’utilisateur en “Cypher Chain”, encore une fois, nous allons fournir un “prompt” qui va le guider. Il est disponible dans le notebook et est plutôt assez gros. Ci-joint un extrait de ce prompt :
CYPHER_GENERATION_TEMPLATE = """You are an expert Neo4j Cypher translator who understands the question in english and convert to Cypher strictly based on the Neo4j Schema provided and following the instructions below:
<instructions>
* Use aliases to refer the node or relationship in the generated Cypher query
* Generate Cypher query compatible ONLY for Neo4j Version 5
* Do not use EXISTS, SIZE keywords in the cypher. Use alias when using the WITH keyword
* Use only Nodes and relationships mentioned in the schema
* Always enclose the Cypher output inside 3 backticks (```)
* Always do a case-insensitive and fuzzy search for any properties related search. Eg: to search for a Company name use `toLower(c.name) contains 'neo4j'`
* Use the relationship variable `o` to access the `shares` and `value` properties of the `OWNS` relationship when calculating the sums.
* Cypher is NOT SQL. So, do not mix and match the syntaxes
* Use the elementId() function instead of id() to compare node identifiers
</instructions>
Strictly use this Schema for Cypher generation:
<schema>
{schema}
</schema>
The samples below follow the instructions and the schema mentioned above. So, please follow the same when you generate the cypher:
<samples>
Human: Which fund manager owns most shares? What is the total portfolio value?
Assistant: ```MATCH (m:Manager) -[o:OWNS]-> (c:Company) RETURN m.managerName as manager, sum(distinct o.shares) as ownedShares, sum(o.value) as portfolioValue ORDER BY ownedShares DESC LIMIT 10```
Human: Which fund manager owns most companies? How many shares?
Assistant: ```MATCH (m:Manager) -[o:OWNS]-> (c:Company) RETURN m.managerName as manager, count(distinct c) as ownedCompanies, sum(distinct o.shares) as ownedShares ORDER BY ownedCompanies DESC LIMIT 10```
Human: What are the top 10 investments for Vanguard?
Assistant: ```MATCH (m:Manager) -[o:OWNS]-> (c:Company) WHERE toLower(m.managerName) contains "vanguard" RETURN c.companyName as Investment, sum(DISTINCT o.shares) as totalShares, sum(DISTINCT o.value) as investmentValue order by investmentValue desc limit 10```
Human: What other fund managers are investing in same companies as Vanguard?
Assistant: ```MATCH (m1:Manager) -[o1:OWNS]-> (c1:Company) <-[o2:OWNS]- (m2:Manager) WHERE toLower(m1.managerName) contains "vanguard" AND elementId(m1) <> elementId(m2) RETURN m2.managerName as manager, sum(DISTINCT o2.shares) as investedShares, sum(DISTINCT o2.value) as investmentValue ORDER BY investmentValue LIMIT 10```
Human: What are the top 10 investments for rempart?
Assistant: ```MATCH (m:Manager) -[o:OWNS]-> (c:Company) WHERE toLower(m.managerName) contains "rempart" RETURN c.companyName as Investment, sum(DISTINCT o.shares) as totalShares, sum(DISTINCT o.value) as investmentValue order by investmentValue desc limit 10```
...
Human: {question}
Assistant:
"""
Maintenant qu’on a guidé notre LLM avec suffisamment de contexte dans notre prompt, il nous reste plus qu’à exploiter la puissance de Neo4J avec notre LLM.
Le notebook montre comment utiliser LangChain pour "ancrer" le LLM avec Neo4j, c’est-à-dire :
- Lier le LLM à la structure du graphe (schéma, relations, propriétés).
- Générer des requêtes Cypher précises à partir des questions utilisateurs.
- Exécuter ces requêtes sur Neo4j et restituer les résultats.
LangChain agit comme un pont entre le LLM (générique) et Neo4j (spécifique).
Il permet de structurer les interactions pour obtenir des réponses précises et contextualisées.
L’utilisation de GraphCypherQAChain automatise la conversion question → Cypher → réponse, pil poil ce dont on a besoin pour un “chatbot métier”.
Si maintenant on repose notre question “Which managers own FAANG stocks?”, la réponse devient complètement pertinente.
Conclusion [point de vue neo4j]
Pourquoi "Ancrer" un LLM avec Neo4j ?
"Ancrer" un LLM (Large Language Model) avec Neo4j signifie connecter le modèle à une base de données de graphes pour améliorer ses réponses. Voici 3 raisons :
Gestion de Questions Complexes (Multi-Hop Knowledge Retrieval)
Les questions complexes nécessitent souvent de relier plusieurs informations entre elles (ex : "Quels gestionnaires de fonds basés à New York détiennent des actions dans des entreprises technologiques cotées après 2020, et qui ont un rendement supérieur à 10% ?").
Dans une base de données relationnelle classique, cela implique des jointures multiples, qui peuvent être lentes et difficiles à optimiser.
Solution avec Neo4j :
Neo4j stocke les relations entre les données (ex : Gestionnaire → DÉTIENT → Action → COTÉE_DANS → Secteur). Ces relations sont pré-calculées et optimisées avant même que la question ne soit posée.
Pour une question nécessitant 4 "sauts" (hops) (ex : Gestionnaire → Action → Entreprise → Secteur), Neo4j traverse ces relations instantanément, sans calculs lourds.
Résultat : Nous obtenons des réponses rapides et précises, même pour des questions complexes.
Fiabilité et Sécurité d’Entreprise
Neo4j permet de limiter l’accès aux données en fonction des permissions de l’utilisateur (ex : un chatbot ne verra que les données autorisées pour le rôle de l’utilisateur). C’est une fonctionnalité qui n’est pas accessible dans la version communautaire.
Performance
Neo4j est optimisé pour les requêtes complexes sur des graphes, avec une latence faible même avec un grand nombre d’utilisateurs simultanés. C’est idéal pour des applications comme un chatbot utilisé par des centaines d’utilisateurs en parallèle.
Ma Conclusion
À première vue, l’impact est indéniable : sans l’appui d’un LLM, l’extraction de données à partir de fichiers non structurés aurait été un défi de taille. L’envie d’ajouter une couche conversationnelle pour interroger ces données devient rapidement évidente. Le Lab, centré sur les atouts d’une base graphe comme Neo4j, met en lumière ces avantages. Une fois les données chargées dans Neo4j, la précision des réponses de l’agent s’en trouve décuplée.
Un aspect important qui n’est pas montré dans le Lab, est que Neo4j a intégré dès sa conception une approche pragmatique de la sécurité, notamment à travers la gestion de la visibilité des données. Par exemple, il est possible d’attribuer des niveaux de confidentialité (comme une échelle de C1 à C4, où C4 représente le niveau le plus restreint). Ainsi, selon les droits de l’utilisateur, la base graphe filtre automatiquement les informations accessibles : un profil autorisé uniquement pour le niveau C2 ignorera les nœuds classés C3 ou C4. Une fonctionnalité qui renforce la sécurité tout en restant transparente pour l’utilisateur.
Si les LLM sont impressionnants, ils ne remplacent pas l’expérience humaine. Leur efficacité dépend largement de la qualité des prompts qui les guident. Dans le cadre du Lab, ces prompts ont été soigneusement testés pour garantir des résultats pertinents. Cependant, en dehors de ce contexte, leur élaboration reste un exercice exploratoire, profondément lié au projet en cours, aux données et aux usecases. Impossible, donc, d’établir un guide universel pour rédiger des prompts efficaces.
Cette réalité rappelle les protocoles de recherche en laboratoire : en IT, comme en science, il est impératif de tester, d'ajuster et d'itérer, à la manière des laboratoires pharmaceutiques, jusqu'à obtenir la pertinence et l'efficacité souhaitées.
Durant cette semaine, j'ai pu rencontrer bon nombre de collègues et amis, jeunes étudiants et professionnels expérimentés, avec qui j'ai eu le plaisir d'échanger sur l'avenir de nos métiers dans l'IT, la place de l’IA qu’elle va prendre, et comment la “dompter”. Le temps que la frénésie autour de l’IA se stabilise, gageons que maîtriser le “prompt” soit le défi de demain, toute génération confondue.
Pour ceux qui sont dans le Sud de la France et qui souhaitent découvrir l'autre révolution en cours dans l'IA (i.e les MCP Servers), Venez nous rencontrer au meetup IA "Piloter votre infra AWS en langage naturel avec LangFuse le 23 Octobre pour une démonstration technique des capacités des MCP Servers.
Retour sur la Swift Connection 2025 14 Oct 11:07 PM (10 days ago)

Retour au Théâtre de Paris : pour sa nouvelle édition, la Swift Connection a de nouveau transformé la scène en point de rencontre privilégié pour les passionnés de l’écosystème Apple. Durant ces deux journées, développeurs, designers et acteurs du numériques ont échangé autour des tendances qui redessinent le développement iOS — de l’IA aux stratégies de tests, en passant par les interfaces expérimentales comme Liquid Glass et les premières explorations autour du Vision Pro.
Présente sur place, notre équipe a assisté à plusieurs conférences marquantes et en partage ici les principaux enseignements. Entre retours d’expérience, réflexions prospectives et bonnes pratiques, cette édition a confirmé que la scène iOS continue d’évoluer vite, et dans toutes les directions à la fois.
Les interventions qui ont marqué !
1 - The Science of Habit-Forming Apps
- Présentateur-rice(s) : Tamia James
- Auteur du résumé : Dylan Le Hir

Résumé
Comprendre la différence entre les mécanismes de manipulation (dark patterns) et les mécanismes d’engagement sain (Hook Model) dans la conception d’applications.
En tant que junior, j’ai beaucoup apprécié la clarté avec laquelle Tamia James a expliqué le concept de dark pattern c’était un bon rappel, utile pour ancrer les pratiques. En revanche, la découverte du Hook Model de Nir Eyal (auteur du livre Hooked) a été une vraie révélation. Ce modèle m’aidera à concevoir des expériences plus engageantes et respectueuses pour les utilisateurs.
Tamia a illustré le Hook Model avec des exemples très parlants :
- DuoLingo et ses triggers redoutables : les notifications quotidiennes qui te rappellent de ne pas perdre ta série d’apprentissage, un petit geste de 3 minutes, mais une habitude bien ancrée.
- Instagram, pour la partie reward : chaque nouvelle publication apporte une dose de satisfaction et renforce l’envie de revenir.
Trois points clés à retenir :
1 - Le côté obscur de la force : Évitez les dark patterns. Ces pratiques qui piègent l’utilisateur, comme : le paiement obligatoire après installation, les abonnements qui se renouvellent automatiquement après la période d’essai ou encore les désabonnements volontairement compliqués (👀).
2 - “May the Force be with you” : Inspirez-vous du Hook Model de Nir Eyal, articulé autour de quatre étapes : Trigger (déclencheur), Action, Reward (récompense) et Investment (investissement). L’objectif : créer des habitudes positives et utiles, sans manipuler.
3 - Pensez avant tout à l’humain : La conception d’une application mobile doit servir les besoins réels des utilisateurs, pas exploiter leurs faiblesses.
Conclusion
Cette conférence m’a éclairé sur la manière dont se forment les habitudes chez les utilisateurs, un levier essentiel pour concevoir des expériences à la fois engageantes et responsables.
En intégrant ces notions, nous pouvons non seulement créer des parcours plus intuitifs, mais aussi mieux identifier les dérives du design persuasif, ces fameux dark patterns qu’il est si facile d’ignorer. D’ailleurs, Tamia n’en a qu'effleurer la surface : en dresser une typologie complète serait précieux pour affiner nos pratiques et affirmer nos choix éthiques en UX.
Ce que j’ai particulièrement apprécié, c’est la justesse du propos : un équilibre rare entre technologie et psychologie, servi avec clarté et pédagogie. Les exemples concrets d’applications mondialement connues ont rendu le sujet vivant et inspirant.
Une présentation qui donne envie d’aller plus loin, de questionner nos propres produits, nos réflexes de conception et la frontière parfois ténue entre influence et manipulation.
2 - Hello Foundation Models
- Présentateur-rice(s) : Alex Logan
- Auteur du résumé : Dylan Le Hir
Résumé
Alex Logan nous a présenté Foundation Models, le nouveau framework d’Apple dédié à l’IA générative intégrée à Apple Intelligence.
Ce framework permet d’ajouter dans vos apps iOS des capacités de :
- Résumé ou compréhension de texte,
- Affinage ou réécriture,
- Extraction d’entités (personnes, lieux, objets),
- Et même rédaction créative.
En une vingtaine de minutes, Alex nous a guidés pas à pas à travers la mise en œuvre du framework, du concept à la première implémentation.
Trois points clés à retenir :
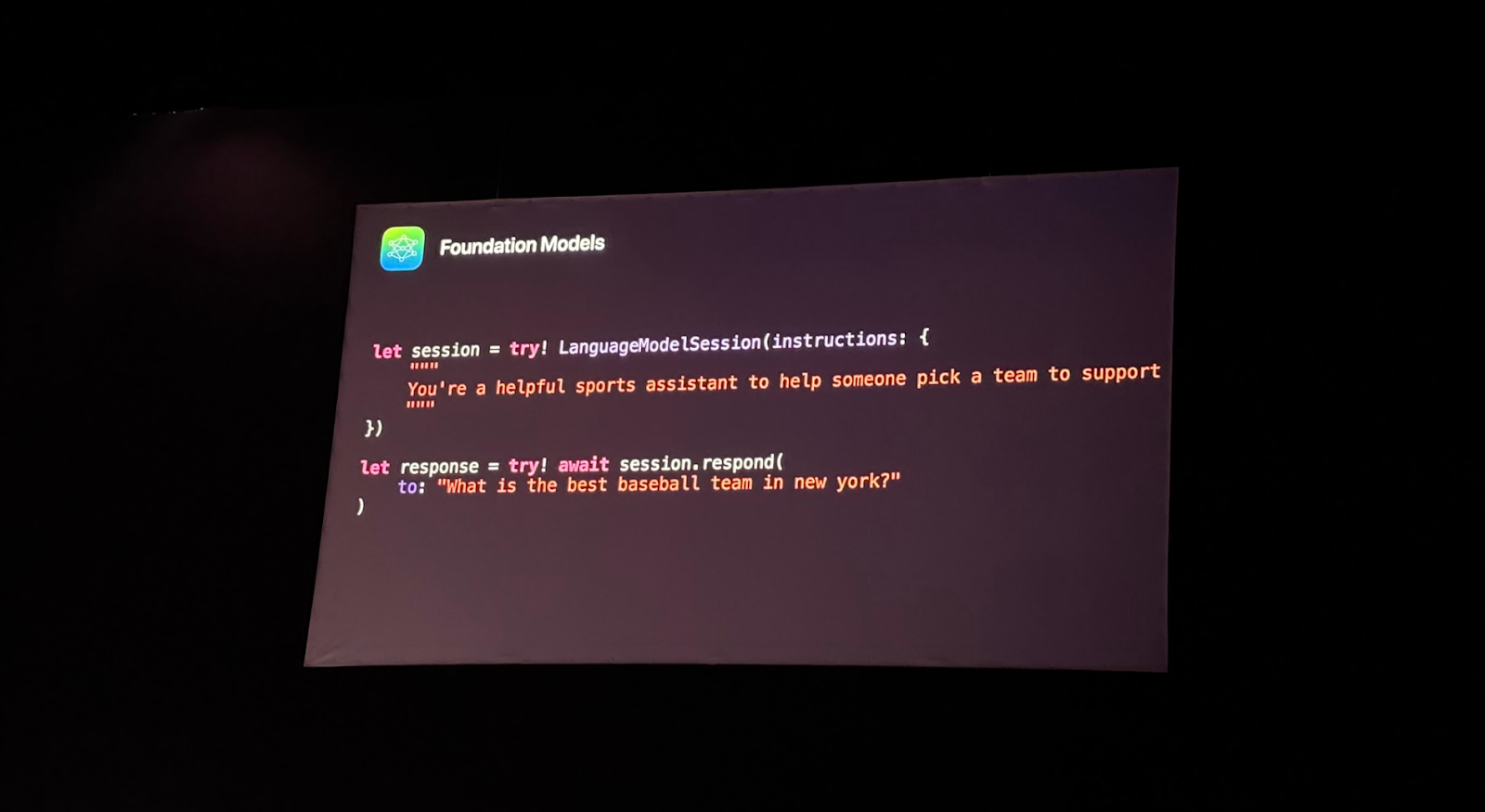
1 - Simplicité d’implémentation : En quelques lignes de code, vous pouvez interagir avec le modèle et obtenir des réponses générées en langage naturel. L’intégration se fait directement dans votre app via LanguageModelSession.
2 - Importance des instructions : Le modèle répond mieux et plus rapidement lorsqu’on lui fournit des instructions claires et des garde-fous. C’est ce qui permet d’orienter la génération et d’éviter des réponses imprécises ou trop longues.

3 - Annotation @Generable : En annotant vos structures ou enums avec @Generable, vous pouvez guider le modèle pour qu’il réponde dans un format Swift précis.
➤ Parfait pour les cas où vous voulez transformer la réponse en données structurées.
Tout était nouveau !
Foundation Models marque une vraie étape dans la façon d’intégrer l’IA générative directement sur l’appareil (on-device). Le framework ouvre des perspectives créatives sans dépendre d’API externes ou de serveurs distants.
Alex a montré comment ce modèle pouvait générer une structure logique autour d’un thème, par exemple :
Choisir une équipe de sport en fonction de critères donnés.
L’idée : montrer que Foundation Models peut servir à construire une réponse intelligente à partir d’une consigne naturelle, le tout dans un environnement Swift natif.
Conclusion
Cette conférence montre à quel point l’IA devient accessible aux développeurs iOS.
On peut désormais imaginer :
- des assistants embarqués,
- des recommandations intelligentes,
- ou des systèmes de génération de contenu sans dépendance réseau.
Le framework simplifie la création d’expériences interactives qui reposent sur des prompts, mais respectent les contraintes de performance et de confidentialité d’iOS.
Une présentation claire, vivante et accessible, d’environ 15–20 minutes, qui donne une très bonne première approche du framework.
Même si la démo restait simple, elle montrait bien le potentiel immense de Foundation Models pour l’écosystème iOS.
Seul petit bémol : j’aurais aimé voir un cas d’usage plus ancré dans le monde professionnel ou applicatif.
Mais dans l’ensemble, une session inspirante et concrète sur l’avenir de l’IA sur nos appareils Apple.
3 - Building iOS Apps Without Xcode, Using Cursor, Claude Code and XcodeBuildMCP
- Présentateur-rice(s) : Thomas Ricouard
- Auteur du résumé : Vincent Blanchet
Résumé
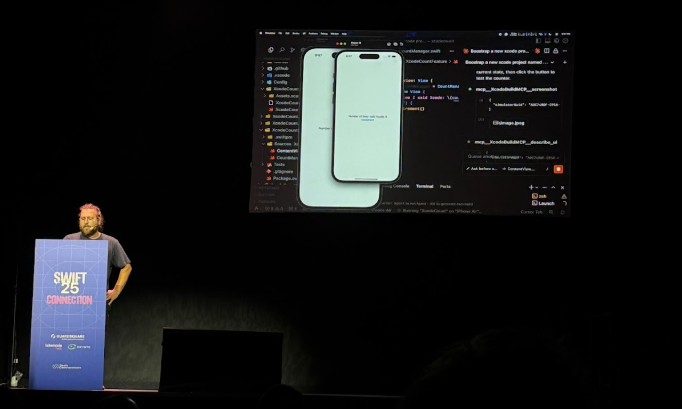
Thomas Ricouard fait une impressionnante démonstration de vibe coding avec Cursor et Claude Code. Il génère en live une application de comptage de clic en partant de zéro. Il commence par le setup du projet, puis il génère une première version très simple où il prompt son besoin. Le résultat est un simple texte et un bouton de clic sans aucun travail sur l’UI. Il demande une refactorisation du code. Il nous montre aussi la force de la suggestion de code de la part de Cursor. Il enchaîne les “Tab” pour produire du code. Puis il demande ensuite à Claude code de rajouter une couche d’ui pour rendre ça plus attirant. Le résultat est assez bluffant. Confettis et barre de progression. En relançant l’app, on constate que le compte de clic n’est pas conservé, il demande alors la correction du bug et le test de celui-ci pour vérifier qu’il a bien été réglé. Le code est généré l’app lancée et testée…
Trois points clés à retenir :
1 - Claude code est tout à capable de générer une app iOS en Swift
2 - Il est plus à l’aise avec les API ayant quelques années, ce qui est pratique pour le support des versions d’iOS précédentes.
3 - Claude code avec le MCP Xcode peut tester ses implémentations
Conclusion
Thomas a parfaitement illustré avec son talk qu’un développeur pouvant utiliser une telle génération va être nettement plus véloce que sans. Il apparaît clairement que le métier de développeur doit composer maintenant avec de tels outils et qu’ils doivent être pris en main au plus vite.
Une belle présentation, dynamique et risquée (live coding). Une belle démonstration de la puissance de ces outils.
4 - Live Activities - Notifications That Users Actually Enjoy
- Présentateur-rice(s) : Maxime de Chalendar
- Auteur du résumé : Vincent Blanchet

Résumé
Les Live Activities représentent une opportunité sous-exploitée pour enrichir l'expérience utilisateur iOS. Au-delà des cas d'usage évidents (VTC, livraison), toute fonctionnalité temporelle ou événementielle peut bénéficier de cette API pour offrir une visibilité permanente et contextuelle à l'utilisateur.
Le talk permet de mieux comprendre comment repenser l’interaction utilisateur autour des notifications :
- La dualité ActivityKit/WidgetKit : J'ai particulièrement apprécié la clarification sur la séparation des responsabilités entre ces deux frameworks. ActivityKit gère la logique métier et le cycle de vie, tandis que WidgetKit se concentre uniquement sur le rendu visuel.
- Le potentiel de l'Apple Watch : Maxime a mentionné que les Live Activities s'étendent également à l'Apple Watch, ce qui ouvre des perspectives intéressantes pour une expérience cross-device cohérente.
- L'état de l'adoption actuel : Le constat que les Live Activities restent sous-utilisées dans l'écosystème est révélateur. C'est une information stratégique importante pour quiconque cherche à différencier son app.
Il a d’abord revisité les exemples classiques que nous connaissons tous, comme les applications de ride-sharing (Uber, Bolt) ou encore la livraison de nourriture en temps réel, où les Live Activities offrent une visualisation instantanée de la progression d’un trajet ou d’une commande directement depuis l’écran verrouillé. Mais il a surtout mis en avant des cas plus innovants et inspirants, qui vont bien au-delà de la simple information pratique. L’application Lumy, par exemple, propose une approche artistique en affichant les cycles solaires sous forme de visuels élégants et immersifs, transformant l’écran verrouillé en une expérience sensorielle. Flighty, de son côté, se distingue par des mises à jour de vol en temps réel. Maxime cite aussi Pixel Pals, un exemple original de gamification où un petit compagnon virtuel évolue directement dans la Dynamic Island, prouvant qu’il est possible de créer un lien émotionnel avec l’utilisateur à travers une simple animation. Enfin, il a mentionné Tinder, qui exploite les Live Activities pour afficher des comptes à rebours liés à des power-ups temporisés, une manière habile d’intégrer cette fonctionnalité dans une mécanique de jeu et d’engagement.
Trois points clés à retenir :
1 - L'implémentation est plus accessible qu'on ne le pense : Maxime a démontré que l'intégration des Live Activities ne nécessite que deux frameworks principaux (ActivityKit et WidgetKit) et suit un cycle de vie simple. La barrière à l'entrée technique est relativement basse pour un gain d'UX considérable.
2 - La créativité prime sur les conventions : Les exemples non-conventionnels (Lumy pour les levers/couchers de soleil, Pixel Pals avec son Tamagotchi dans Dynamic Island) prouvent qu'il faut sortir du cadre traditionnel "suivi de livraison" pour exploiter pleinement le potentiel de cette API.
3 - Facteur de différenciation stratégique : Peu d'apps implémentent encore les Live Activities. C'est une fenêtre d'opportunité pour se démarquer sur l'App Store et améliorer significativement la rétention utilisateur grâce à une présence continue sur l'écran verrouillé et Dynamic Island.
Conclusion
Une présentation technique solide, sans superflu, qui inspire à repenser nos apps existantes. Maxime a brillamment démontré que les Live Activities ne sont pas un "nice-to-have" gadget, mais un véritable levier d'engagement utilisateur qui mérite d'être intégré de manière réfléchie. Je recommande vivement de revoir ce talk et d'auditer vos apps pour identifier les opportunités d'implémentation.
5 - A talk… Two ways
- Présentateur-rice(s) : Josh Holtz, Zach Brass
- Auteur du résumé : Dan Perocheau

Résumé
Le talk de Zach et Josh explore la diversité des styles de présentation et la manière dont chacun peut trouver sa voix en conférence. Plutôt que de se focaliser sur le contenu technique (les reusable cells en Swift dans ce cas là), l’idée centrale est de montrer qu’il n’existe pas une seule “bonne” manière de présenter. En combinant deux approches radicalement différentes — l’over-préparation méthodique de Zach et la spontanéité de Josh — ils démontrent qu’un talk réussi repose autant sur la connaissance de son propre style que sur la capacité à s’adapter à son public.
Le véritable tour de force de cette conférence réside dans l’expérience qu’ils ont tentée : chacun a préparé les slides de l’autre et les a présentés selon le style opposé au sien. Ce renversement a révélé, avec humour et lucidité, à quel point la préparation et l’improvisation sont deux forces complémentaires, et non des approches concurrentes. En se glissant dans la méthode de l’autre, ils ont prouvé qu’un bon talk ne dépend pas du format, mais de la maîtrise du rythme, de l’intention et de la connexion avec le public.
Zach illustre sa méthode par une préparation minutieuse : chaque phrase est notée, chaque pause est planifiée après une blague ou un meme, et le talk est répété jusqu’à la mémorisation complète. Josh, au contraire, prépare ses slides à la dernière minute, les répète peu et improvise son discours, transformant son talk en une conversation vivante avec l’auditoire. Ensemble, ils créent un talk méta, où le contraste entre leurs styles devient lui-même un enseignement : comprendre son propre rapport à la préparation et à l’improvisation est une compétence clé pour tout intervenant.
Trois points clés à retenir :
1 - Connaître et jouer de son style : il est crucial de comprendre si l’on est plus à l’aise en préparant chaque mot ou en improvisant, et de tirer parti de ses forces naturelles pour captiver l’audience.
2 - Préparation vs spontanéité : chaque méthode a ses avantages : la préparation rigoureuse permet de maîtriser le rythme, les pauses et l’impact des blagues, tandis que la spontanéité offre de la fluidité et de l’authenticité.
3 - Collaboration et contraste : combiner deux styles différents peut créer un talk riche et dynamique, démontrant que la diversité d’approche peut renforcer l’expérience pour l’auditoire.

Conclusion
Même si le contenu Swift n’est pas central, le talk fournit des enseignements sur la communication et la transmission des idées. Dans le cadre de projets où il faut présenter des concepts techniques, qu’il s’agisse de démos internes ou d’articles destinés à un public plus large, comprendre l’impact de son style de présentation peut influencer la clarté et l’adhésion des interlocuteurs. Cela invite à réfléchir sur la manière de partager nos connaissances efficacement, que ce soit en réunion, en workshop ou lors d’un talk public.
Le talk de Zach et Josh était très clair et bien rythmé. La combinaison de deux styles contrastés a permis de maintenir l’attention et de rendre l’exposé captivant, tout en délivrant un message simple mais puissant : comprendre et exploiter son style personnel est essentiel pour communiquer efficacement. Leur complicité et le format méta ont rendu l’expérience instructive et agréable pour l’ensemble de l’audience.
6 - Designing for the Post-Screen Era
- Présentateur-rice(s) : Maxim Cramer
- Auteur du résumé : Dan Perocheau

Résumé
Le talk de Maxim porte sur la notion de post-screen era, une ère où les interfaces ne se limitent plus à ce qui est visible à l’écran, mais savent quand se mettre en retrait pour laisser l’utilisateur interagir efficacement. Elle souligne que le véritable enjeu n’est pas la sophistication de la technologie mais la capacité à concevoir des systèmes centrés sur l’humain, compréhensibles et dignes de confiance.Pour Maxim, l’IA doit devenir un partenaire capable de s’adapter au contexte, de fournir un feedback clair et d’orchestrer les interactions selon les besoins de l’utilisateur, afin de transformer des outils puissants en expériences réellement utiles et accessibles.
Maxim cite l’ouvrage de Don Norman (The design of everyday things) pour appuyer ses idées : “Si une porte nécessite un panneau “Push”/“Pull”, c’est un échec du design.”. Cette illustration traduit un principe simple : le bon design doit guider sans instructions explicites. La compréhension intuitive est fondamentale, savoir non seulement où interagir, mais également comment, et sans manuel.
Un autre exemple mis en avant par Maxim est une expérience personnelle qui lui est arrivée lors d’un déplacement en vélo. L’iPhone détecte un ‘workout’ et demande à l’utilisateur de valider ou non l’activité avec les AirPods de l’utilisateur en hochant la tête. Ce design n’est absolument pas adapté lors d’un déplacement en vélo et met en danger l’utilisateur, et met en avant les limites actuelles des interfaces dites invisibles ou proactives.
Trois points clés à retenir :
1 - Chaque époque a ses angles morts : les designers d’hier ont su anticiper certaines révolutions (comme la personnalisation ou la biométrie) tout en se trompant complètement sur d’autres (la matérialité des supports, l’absence de cloud)
2 - Nos schémas d’interface actuels sont datés : nous perfectionnons les gestes tactiles (taps, swipes) alors que les systèmes intelligents apprennent déjà à anticiper nos besoins, sans interface visible.
3 - Penser au-delà de l’écran : il ne s’agit pas seulement de créer de nouveaux écrans ou formats, mais de questionner la nature même de l’interaction homme-machine dans un futur où l’IA sera omniprésente.

Conclusion
En tant que tech, j’ai souvent tendance à me concentrer sur le “comment”, la mise en œuvre, les tâches et les solutions, en laissant parfois de côté le “pourquoi” derrière les produits sur lesquels je travaille. Ce talk m’a poussé à envisager nos phases de conception avec une approche plus prospective, en intégrant davantage de veille technologique et en élargissant nos référentiels de réflexion au-delà du seul développement mobile. Il invite à expérimenter des interfaces allégées ou proactives, capables d’anticiper certaines interactions plutôt que d’attendre une action explicite de l’utilisateur.
Cela soulève naturellement de nouvelles questions : comment définir les critères d’une “bonne” expérience utilisateur dans un monde post-écran ? Quelles seront les implications éthiques et les enjeux de contrôle utilisateur dans des interfaces de plus en plus pilotées par l’IA ? Et, plus concrètement, quelle place accorder aux App Intents dans cette évolution des interactions ?
L’intervention de Maxim se distinguait par sa clarté, sa structure, et la richesse des exemples présentés. Au-delà de son contenu technique, elle a su fédérer des profils très variés autour d’une réflexion commune sur l’avenir du design, rappelant que la technologie n’a de sens que lorsqu’elle sert véritablement l’humain.
Vous pouvez suivre Maxim via linkedin ou sa newsletter.
7 - What People Get Wrong with Accessibility
- Présentateur-rice(s) : Ben Freiband
- Auteur du résumé : Olivier Geffroy
Résumé
On entend souvent parler d'« amélioration de l'accessibilité » pour les applications, mais dans bien des cas, la meilleure approche consiste à en faire moins, “Less is More”. Dans cette présentation, Ben explique que la prise en charge intégrée de l'accessibilité d'iOS fonctionne souvent mieux lorsqu'elle n'est pas modifiée ou contournée, et comment des ajustements manuels excessifs peuvent nuire à l'ergonomie pour les utilisateurs. Avec humour, Ben précise que bien avant cela, une app accessible c’est avant tout une app bien conçue et claire pour tout le monde. Il nous présente donc son application “Apple Store” … qui permet bien évidemment d’acheter des … pommes. Et au travers de quelques démonstrations puis exemples, nous montrer comment la rendre accessible de manière efficiente.
Cela commence par une réflexion produit/UX afin de rendre claire la navigation et les CTA ainsi qu’une utilisation pertinente des outils d'accessibilité mis à disposition par Apple :
- Voice Over
- Switch control
- Assistive Touch
- Voice control
- Color Constrast
Nous avons vu que s'appuyer sur les paramètres par défaut du système pour rendre notre application accessible avec un minimum d'efforts supplémentaires reste la méthode la plus efficace et également maintenable dans le temps. Quand il est réellement nécessaire de personnaliser le comportement d'accessibilité cela reste possible mais avec parcimonie. Et quoi de mieux que cette présentation au travers d’exemples concrets de paramètres par défaut efficaces et de personnalisations excessives ou contre-productives.
Considérant un premier exemple sur l’application, le voice over lit sans distinction tous les éléments de la page et l’utilisateur est rapidement perdu dans la navigation.
Le besoin : l'ajout de headers sur les différentes sections de la page. Et plutôt que d’ajouter la fonction .accessibilityaddtraits(.isHeader) dans le code existant (ici par exemple pour la section “visit us”) :
... On pourra facilement remplacer toutes ces parties par la fonction “GroupBox” prévue par Apple et qui permet avec une économie de moyens d’obtenir un résultat comparable.
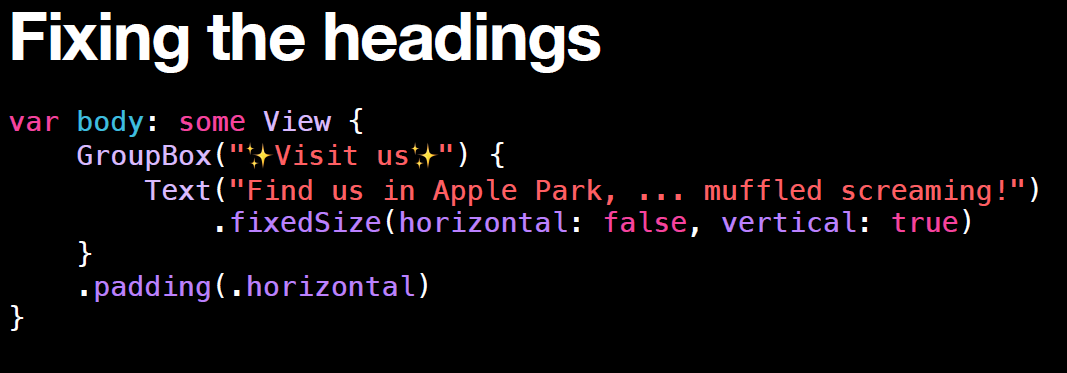
Trois points clés à retenir :
1 - Le plus simple reste d’utiliser un composant “built-in” Apple
2 - On peut ensuite customiser un composant pour certaines fonctions
3 - Et enfin, selon les besoins on pourra construire un composant custom (avec plus de sueur)
Conclusion
Rendre son application accessible c’est avant tout faire des actions pour s’assurer que tout le monde peut l’utiliser pleinement indépendamment de sa situation individuelle. Accessibilité et usabilité vont main dans la main. Les boutons d’actions et interactions proposés à l’utilisateur sont clairement identifiés et repérables (”affordance” et “signifier”). Si l’utilisateur doit se demander comment accéder à l’action ou la page qui l’intéresse, c’est un échec et ce que l’on soit en situation de handicap ou pas.
Ben nous livre une présentation claire de ce qui fait qu’une application est lisible, pratique et utilisable pour tous et permet de réaliser que l’accessibilité est une extension de cette lisibilité et ne doit pas être vu comme un coût, un défi ou une difficulté supplémentaire.
Vous pouvez suivre Ben via linkedin ou sur son blog.
En résumé :
Cette édition 2025 de la Swift Connection a une nouvelle fois montré la richesse et la maturité de l’écosystème Apple dans son ensemble. Au fil des conférences, un même fil conducteur s’est dégagé : la volonté de remettre en question nos habitudes de conception, d’explorer de nouvelles approches et de partager ouvertement les apprentissages du terrain.
Entre vision produit et approche user-centric, les discussions ont aussi mis en lumière la place grandissante de l’intelligence artificielle dans nos pratiques — non pas comme un simple outil, mais comme un levier pour repenser l’expérience et redéfinir la frontière entre interface et usage.
Plus qu’un simple rendez-vous technique, la Swift Connection reste un espace d’échange et d’inspiration, où chacun repart avec des idées concrètes, mais aussi une dose bienvenue de motivation. Un grand bravo à l’ensemble des intervenants et à l’équipe d’organisation pour la qualité de cette édition — et rendez-vous l’an prochain pour continuer à faire évoluer, ensemble, notre manière de concevoir et de développer.
Maîtriser GitHub Copilot dans VSCode : le guide ultime des instructions personnalisées 6 Oct 1:00 AM (19 days ago)

GitHub Copilot, lorsqu’il est utilisé dans Visual Studio Code, n’est pas seulement un outil d’autocomplétion : c’est un assistant capable de s’adapter à ton environnement, ton style et tes besoins.
Sans règles, Copilot agit comme un modèle générique : il propose du code standard, parfois en décalage avec tes conventions internes, tes contraintes techniques ou ta façon de rédiger. Avec des custom instructions, tu transformes Copilot en un collaborateur aligné avec ta façon de travailler.
Les custom instructions permettent de guider Copilot de manière précise : elles l’aident à produire du code conforme à ton style et à tes standards, à réaliser des revues de code ou des modifications en respectant les conventions de ton équipe, à adapter le ton et la structure des réponses selon ton public — qu’il soit technique ou non technique — et enfin à prioriser certains frameworks, bibliothèques ou patterns spécifiques à ton projet.
En définissant des règles, tu injectes ta voix et tes pratiques métiers dans les suggestions :
- Style de code : indentation, nommage, organisation des imports.
- Stack technique : préciser les bibliothèques, frameworks ou outils à utiliser.
- Structure des livrables : exiger des tests, des commentaires, ou un format précis pour les commits.
- Niveau de détail : demander des explications pédagogiques ou au contraire un code concis.
TL;DR — panorama des types de règles
| Type | Portée | Emplacement | Cas d’usage | Limites / Notes |
|---|---|---|---|---|
| Instructions personnelles | Globale (utilisateur) | Préambule Chat / Profil Copilot | Ton, style de réponse, niveau de détail | Non liées au dépôt, ne modifient pas les complétions inline |
| Instructions par dépôt | Projet (dépôt) | .github/copilot-instructions.md (ou .github/instructions/*.instructions.md + applyTo) | Conventions de code, outils, archi spécifiques au repo | applyTo/multi-fichiers selon disponibilité; éviter secrets; résolution de conflits nécessaire |
| Instructions organisationnelles | Organisation | Admin GitHub (Copilot Enterprise) | Standards transverses, sécurité/compliance | Réservé à Copilot Enterprise, géré par owners |
| Prompt files | À la demande (par exécution) | *.prompt.md dans le projet | Actions récurrentes (review, refactor, audit) | N’applique rien en arrière-plan; doit être déclenché manuellement |
Exemple concret
Utilisons un prompt simple pour développer une roue de sélection de noms. Les utilisateurs pourraient y entrer des noms, et il y aurait un bouton "Choisir un gagnant". Quand on clique dessus, la roue tourne et affiche un nom gagnant.
Develop a name picker widget in the form of a wheel. This widget should allow users to input names and include a "Choose Winner" button that, when clicked, spins the wheel and displays a winning name.
Prompt pour générer widget test
Sans règles personnalisées
La première version est très générique : elle se concentre sur la rotation de la roue et l'affichage du gagnant, sans trop se soucier de l'expérience utilisateur, du thème ou de la localisation. Les libellés sont en anglais, les commentaires s'affichent directement sous forme de texte brut et le style est minimaliste. Cela fonctionne, mais on a l'impression d'un code standard qui pourrait s'adapter à n'importe quel projet sans vraiment s'adapter à l'environnement.
Avec des custom instructions
Grâce à l’application créée pour un autre article sur les patrons de conception avec Flutter, je lui ai demandé de générer des instructions qui correspondent à mon style d’écriture. Mais vous verrez plus tard dans l’article que Copilot propose des solutions pour créer automatiquement ces règles.
You are an expert software assistant.
I want you to analyze this codebase and generate a **custom instruction guide** for GitHub Copilot so that its suggestions match the project’s coding style and best practices.
### Steps:
1. **Analyze the codebase**:
- Frameworks, libraries, architecture.
- Naming conventions.
- State management patterns.
- File and folder structure.
- Testing strategy.
- Commenting/documentation style.
2. **Generate a structured Copilot instruction guide** with the following sections:
- **Identity & Context** → who the developer is in this project context, what stack/framework is used.
- **Goals & Expectations** → what to optimize for (readability, testability, performance, etc.).
- **Style & Conventions** → naming rules, file structure, code style, widget/component design rules.
- **Do’s & Don’ts** → explicit rules for what to prefer/avoid in code generation.
- **Interaction Style** → how Copilot should explain or suggest code (minimal, detailed, alternatives, etc.).
3. **Output**:
- Clear, concise, and copy-paste ready.
- Written as if I will paste it directly into Copilot’s “Custom Instructions” section.
Prompt pour générer des customs instructions rapides
La deuxième version, cependant, montre une nette amélioration des pratiques. Le widget s'intègre mieux à Material Design en utilisant des Card, des Border, des Chip pour la gestion des participants et des AlertDialog pour les commentaires. Il respecte le thème de l'application en utilisant la palette de couleurs et adapte même les libellés au français. Le processus de sélection du gagnant est également plus abouti, avec une désactivation appropriée des boutons lorsque le nombre de participants ajoutés est insuffisant et une AlertDialog dédiée pour célébrer le résultat.
Au-delà de la simple fonctionnalité, des instructions claires transforment un extrait générique en composant prêt à s’intégrer à ton design system, ton langage et tes normes d’expérience utilisateur. C’est la différence entre du code standard e du code aligné sur les standards de ton équipe.
Types de règles (custom instructions)
Dans Visual Studio Code, Copilot peut être guidé par différents types de règles, chacune ayant sa portée et son utilité.
Même si certaines sont spécifiques à GitHub Web ou à Copilot Enterprise, nous allons surtout nous concentrer sur celles qui influencent l’expérience dans VS Code.
Instructions personnelles (Personal custom instructions)
C’est une phrase, un ordre que l’on met au début du chat, comme contexte, juste avant d’écrire ton prompt. Principalement utilisées dans GitHub Web, mais la logique est la même pour fixer un style global.
Adding personal custom instructions for GitHub Copilot - GitHub Enterprise Cloud Docs
Ces réglages s'appliquent à toutes tes conversations Copilot, peu importe le projet. Ils te permettent de personnaliser ton style de communication, tes préférences techniques et le format de sortie désiré.
Exemples :
- “Explique toujours le code en commentaires.”
- “Utilise le style Python PEP8 et des docstrings Google-style.”
- “Réponds toujours en français sauf si le code est en anglais.”
Ces instructions servent de socle : elles assurent une cohérence dans toutes les interactions avec Copilot.
Instructions par dépôt (Repository custom instructions)
Le cœur de la personnalisation dans VS Code. Adding repository custom instructions for GitHub Copilot - GitHub Enterprise Cloud Docs
Les instructions pour GitHub Copilot sont limitées à un projet précis et sont implémentées via un fichier .github/copilot-instructions.md à la racine du dépôt. Ce fichier, rédigé en Markdown et en langage naturel, sert à définir des conventions de code, spécifier les outils à utiliser (frameworks, CI/CD, test runners), et imposer des règles d'architecture ou de performance.
.github/instructions/ contenant plusieurs fichiers .instructions.md avec un champ applyTo pour cibler des dossiers ou types de fichiers spécifiques.Note de disponibilité : la configuration multi-fichiers avec front matter applyTo peut dépendre de la version/du tenant et n’est pas toujours activée. Si elle n’est pas disponible, utilisez le fichier unique recommandé .github/copilot-instructions.md.
---
applyTo: "src/**/*.ts"
---
Always explicitly type all TypeScript functions.
Prohibit `any`.
Use ESLint according to `.eslintrc`.Exemple d'instructions par dépôt
Instructions organisationnelles (Organization custom instructions)
Elles fonctionnent comme les instructions personnelles et sont réservées à Copilot Enterprise – non spécifiques à VS Code mais compatibles.
Adding organization custom instructions for GitHub Copilot - GitHub Enterprise Cloud Docs
Ces paramètres et règles s'appliquent à tous les dépôts et utilisateurs de l'organisation. Leur administration est gérée par les owners de l'organisation. Ils servent à uniformiser les conventions de code, les pratiques de développement, et à appliquer de manière cohérente les politiques de sécurité et les exigences de conformité sur l'ensemble des projets.
Prompt files (VS Code)
Si tu dois réécrire le même prompt, si tu as des usages redondants. C’est un outil puissant pour automatiser des prompts réutilisables.
Les fichiers *.prompt.md sont utilisés dans VS Code pour encapsuler et permettant de standardiser des actions récurrentes telles que les revues de code, les refactorings ou les audits. Leur contenu comprend un titre ou une description, des instructions claires et, si nécessaire, des variables dynamiques comme {{fileName}} ou {{selectedText}}.
# Title: Code review
Analyses the {{fileName}} file and identifies:
- Potential bugs
- Possible optimisations
- Style violationsExemple minimal de prompt files pour une revue de code
Copilot Edits et Agents dans VS Code
Le mode agent transforme Copilot en un assistant autonome capable de prendre en charge des tâches complètes, pas seulement des suggestions ligne par ligne. Use agent mode in VS Code
Dans ce mode, Copilot planifie, exécute et itère sur ses actions pour atteindre un objectif donné, à partir d’un simple prompt.
En mode Agent, Copilot peut :
- Modifier plusieurs fichiers en une seule tâche.
- Naviguer dans tout le projet pour trouver les points concernés.
- Exécuter des commandes (scripts, build, tests) selon le contexte.
- Proposer des plans de refactorisation détaillés avant de les appliquer.
- S’adapter dynamiquement aux résultats intermédiaires pour ajuster sa stratégie.
Les custom instructions jouent ici un double rôle. Elles servent de garde-fou afin d’éviter des choix techniques incompatibles avec ton projet, tout en constituant un cadre stratégique qui oriente les décisions de l’agent vers tes propres standards.
Exemple de comportement d’agent avec une règle d’instruction
Always document the functions you create with a Google-style docstring.
Custom instructions pour l'agent
Avec Agent Mode activé, cette consigne s’applique à chaque fonction générée, quel que soit le nombre de fichiers modifiés.
Implement a clear and intuitive checkbox option, labeled "Delete winning name," which, when selected, will automatically remove the name chosen as the winner from the list.Prompt minimal pour améliorer notre roue

Exemple du comportement agentique sur VSCode
En tant qu’agent, Copilot a lu les fichiers pertinents pour repérer le point d’intégration, et a implémenté la solution en ajoutant une option de suppression automatique du gagnant avec sa logique dédiée.
Il a ensuite vérifié le respect du style (libellés, widgets, gestion d’état) et des docstrings au format Google, a passé le lint et corrigé les ajustements nécessaires, et a contrôlé la conformité aux conventions du projet (structure, nommage, accessibilité).
Enfin, Copilot a conclu par un débrief indiquant que la fonctionnalité est isolée, contrôlable via la case à cocher, correctement documentée et sans régression observée.
Utilisation avancée dans VS Code
Génération des instructions
Bonne nouvelle, il y a un bouton magique pour créer ton fichier de règles.
Tu peux générer ces fichiers depuis l’interface de VS Code, sans passer par un éditeur externe :
- Palette de commandes → taper "Copilot: Create Instruction File".

Cette commande crée un prompt qui active Copilot afin qu'il génère un fichier .github/copilot-instructions.md spécifiquement adapté aux besoins et à la structure de ton projet actuel. Ce fichier contiendra des instructions détaillées et personnalisées pour l'utilisation optimale de Copilot dans le contexte de ton environnement de développement. L'objectif est de maximiser l'efficacité de Copilot en lui fournissant les informations nécessaires pour qu'il puisse proposer des suggestions de code, des complétions et des refactorisations pertinentes, en accord avec les conventions et les spécifications de ton projet.

Application des fichiers d’instructions dans Copilot Chat
Une fois que tes fichiers d’instructions sont en place (.github/copilot-instructions.md ou .instructions.md dans .github/instructions/), VS Code les charge automatiquement dès que tu ouvres le projet.
.instructions.md ciblés par applyTo peut être soumis à disponibilité. À défaut, le fichier unique .github/copilot-instructions.md est pris en charge de manière générale.Ces instructions influencent directement le comportement de l’outil. D’une part, elles orientent les réponses du Chat, puisque Copilot adapte son ton, son style et respecte les contraintes définies.
D’autre part, elles guident également les Copilot Edits : lorsque tu sélectionnes du code et demandes une modification, Copilot applique les règles établies afin de produire un résultat conforme aux attentes.

La fonctionnalité Copilot peut être activée ou désactivée globalement dans les paramètres de VS Code. Il est également possible de désactiver temporairement la prise en compte des instructions pour tester un comportement "neutre" de Copilot ou en cas de changement de contexte de projet. Les modifications prennent effet immédiatement lors de la prochaine interaction avec le Chat ou le mode Edits.
Organisation des instructions
Afin de maximiser la clarté et la maintenabilité, structure les fichiers par type de tâche : src.instructions.md pour les règles de génération et d'organisation du code, tests.instructions.md pour les règles spécifiques aux tests (framework, structure, conventions), et docs.instructions.md pour les règles de documentation (format, ton, sections obligatoires).
Limitations et portée
Les règles définies dans les fichiers d’instructions influencent Copilot Chat et Copilot Edits, mais n’ont aucun effet sur les complétions inline acceptées via Tab. Leur portée est limitée au dépôt ouvert : dès qu’une instruction est modifiée dans le fichier du projet, l’impact est visible à la prochaine interaction, que ce soit une nouvelle question ou une demande d’édition.
Il est important de garder à l’esprit que des instructions trop longues augmentent le nombre de tokens utilisés, ce qui peut ralentir les réponses ou diminuer la pertinence des suggestions ; il est donc préférable de rédiger des sections concises et ciblées.
Certaines fonctionnalités, comme le champ applyTo ou la configuration multi-fichiers via .github/instructions/*.instructions.md, dépendent de la version ou du tenant et peuvent être en preview : par défaut, il est recommandé d’utiliser le fichier unique .github/copilot-instructions.md.
Lorsque plusieurs fichiers d’instructions sont présents, Copilot fusionne les règles, mais celles ciblées via applyTo prennent le dessus sur les règles globales. Il est donc essentiel d’éviter toute contradiction entre les instructions personnelles, d’organisation et de dépôt. Par ailleurs, il ne faut jamais inclure de secrets (clés API, tokens, données sensibles) ni d’URL internes confidentielles dans les instructions, pour des raisons de sécurité.
Bonnes pratiques pour les règles
Pour que Copilot suive efficacement tes standards, tes instructions doivent être rédigées avec soin. Elles doivent être claires et concises, sans jargon inutile ni formulations ambiguës, afin d’éviter toute interprétation erronée. Elles doivent aussi être impératives, en privilégiant l’infinitif ou l’impératif direct : par exemple, au lieu d’écrire “On pourrait utiliser des doubles quotes”, mieux vaut préciser “Utilise uniquement des doubles quotes”. Enfin, elles doivent être contextuelles, en mentionnant explicitement les éléments clés de ton environnement, comme la stack technique (“Projet React avec TypeScript”), l’outil de build (“Utilise Bazel”) ou encore les règles de style de code à respecter (“Respecte les règles ESLint standard + Prettier”).
Plus ces instructions sont précises et adaptées à ton contexte, plus Copilot pourra produire un code aligné sur tes conventions et directement exploitable.
Tester et ajuster les effets
Pour optimiser les règles de Copilot, vérifie les instructions actives, ajuste le niveau de rigueur (alléger ou renforcer), assure la cohérence entre les règles personnelles, de dépôt et d'organisation, et utilise applyTo pour cibler précisément certains fichiers ou répertoires (si disponible).
Rechercher des règles sur des projets publics existants sur GitHub
De nombreux contributeurs mettent à disposition leurs règles Copilot, souvent tirées de projets open source. N'hésite pas à explorer ces ressources publiques : elles constituent une mine d'or d'inspiration pour affiner tes propres configurations et découvrir des approches que tu n'aurais pas envisagées. Par exemple le site https://www.copilotcraft.dev/ qui te permet de générer un template de règles.
Conclusion
Optimiser GitHub Copilot avec des custom instructions transforme ton flux de travail en l'alignant sur tes standards et ta culture d'équipe. Copilot s'adapte à ton style de code, tes outils et le niveau de détail de tes livrables, améliorant la qualité et la cohérence de tes projets.
L'expérimentation est cruciale : commence simple, observe l'impact, puis affine, en utilisant des fonctionnalités comme "applyTo" et en t'inspirant des travaux de la communauté dev.
En intégrant ces pratiques, Copilot devient un prolongement de ton expertise, garantissant un code de meilleure qualité, une productivité accrue et une harmonie technique. C'est le passage d'un simple outil à un partenaire de code indispensable.
Annexes
// .github/copilot-instructions.md
# Custom instructions for GitHub Copilot — flutter-design-pattern-configuration-builder
## Identity & context
- You are assisting a Flutter/Dart developer working on a small demo app that showcases a Builder + Director design pattern around “vehicle cards”.
- Tech stack: Flutter (Material 3), Dart null-safety, default flutter_lints.
- App uses simple state (setState in local StatefulWidgets). No Provider/Bloc/Riverpod.
- Project language is mixed FR/EN in UI strings; keep French labels in UI. The code intentionally uses the spelling “Vehicule” in many symbols and files—preserve it.
## Goals & expectations
- Optimize for clarity, immutability, and testability over micro-optimizations.
- Generate idiomatic Flutter widgets: prefer StatelessWidget, const constructors, final fields.
- Keep the design pattern separation: configuration objects, builders, and a director that sequences builder steps.
- Suggestions should compile with flutter_lints defaults and fit existing folder/barrel structure.
- When adding features, also propose/update minimal widget tests following the existing style.
## Style & conventions
Naming
- Classes, enums: PascalCase (e.g., `VehiculeCard`, `VehicleType`, `CarBuilder`).
- Methods, fields, variables: lowerCamelCase (e.g., `buildSpecsSection`, `isActionLoading`).
- Keep "Vehicule" spelling where already used (do not “correct” to Vehicle in identifiers or filenames).
Files & folders
- Widgets: `lib/widgets/` (icons, sections, card, header, button). New small reusable UI pieces go here.
- Views/pages: `lib/views/` (screens like bike demo pages).
- Models: `lib/models/` (simple data classes like `VehicleSpecsData`, `EngineData`, `VehicleType`).
- Config-only pattern: `lib/vehicule_with_configuration/` with `VehicleConfiguration` subclasses and a `VehicleWidget` factory.
- Builder pattern: `lib/vehicule_with_configuration_and_builder/` with `*CardConfiguration`, builders (e.g., `CarBuilder`, `BikeBuilder`), and `VehicleWidgetDirector`.
- Barrel exports: keep `lib/widgets/widgets.dart`, `lib/models/models.dart`, `lib/lib.dart` updated when adding public modules.
- Tests: `test/*.dart`, name with `_test.dart` and use `flutter_test`.
Widget & code style
- Prefer StatelessWidget. Use StatefulWidget + `setState` only for local UI state (e.g., loading toggles).
- Constructors: `const` when possible; mark parameters `required` and fields `final`.
- UI: Use Material widgets, simple layout, and consistent theming (`ColorScheme.fromSeed(seedColor: Colors.indigo)`).
- Card look: rounded corners (~18), subtle shadow, padding ~18, vertical spacing via SizedBox or Column spacing.
- Optional sections return null and are conditionally rendered with `if (widget != null) widget!`.
- Keep public APIs small and explicit; avoid global state/singletons.
Design pattern contracts
- Config-only flow (`vehicule_with_configuration`):
- Create configuration subtype (`CarConfiguration`, `BicycleConfiguration`) implementing:
- `buildIcon()`, `buildSpecsSection()`, `buildEngineSection()`, `buildButton()`.
- Use `VehicleWidget.car(...)` / `.bicycle(...)` factories to wrap config and render `VehiculeCard`.
- Builder flow (`vehicule_with_configuration_and_builder`):
- Define a `*CardConfiguration` with plain data.
- Implement a `VehiculeCardBuilder` subclass with step methods: `withType`, `withTitle`, `withSubtitle`, `withIcon`, `withSpecs`, `withEngine`, `withButton`.
- Use `VehicleWidgetDirector` to sequence steps into a recipe (may include/exclude sections).
- Call `builder.build()` to get a `VehiculeCard`.
Strings & localization
- Keep UI strings in French where present (e.g., “Immatriculation”, “Mon garage”, button labels like “Réessayer”). No i18n framework is used.
Testing
- Wrap widgets in `MaterialApp(home: Scaffold(body: widget))` for tests.
- Use `flutter_test` finders: `find.text`, `find.textContaining`, `find.byIcon`, `find.byType`.
- For button taps, `await tester.tap(find.byType(ElevatedButton)); await tester.pump();` and assert side effects.
- Prefer focused tests that assert visible text, icons, and conditional sections.
## Do’s & Don’ts
Do
- Use `const` and `final` aggressively; keep constructors `const` when possible.
- Follow existing naming and file placement; update barrel files when adding exports.
- Keep “Vehicule” spelling in identifiers and paths to match the project.
- In builders, implement all step methods even if some are no-ops for a given type.
- Keep UI minimal and accessible; use standard Material components and theming.
- For new public behavior, add/adjust a small widget test mirroring the existing style.
Don’t
- Don’t introduce state management frameworks (Provider/Bloc/Riverpod) or navigation libraries.
- Don’t print to console for UX; use SnackBar in UI code when needed.
- Don’t refactor to English spelling or rename established APIs.
- Don’t mix platform-specific code or plugins; keep pure Flutter where possible.
- Don’t over-abstract; prefer simple data classes and small widgets over deep hierarchies.
## Interaction style
- Default to concise, single-solution suggestions that match the established patterns.
- When multiple patterns exist (config-only vs builder), pick the one already used in the touched file/folder; otherwise, suggest config-only for simple cases and builder+director when demonstrating recipes.
- Show minimal explanatory comments inline only where the pattern isn’t obvious; otherwise, keep code comment-light as in the repo.
- Prefer imports from barrel files (e.g., `widgets/widgets.dart`, `models/models.dart`) when adding sample code.
- If creating files, propose filenames and locations that fit the structure and add the necessary exports.
— End of Copilot custom instructions —Instructions générées pour la roue du début, suite à l'article sur les design pattern en Flutter
# Copilot instructions for this repo
Context: Flutter app with Material 3 theme and simple stateful widgets. UI text mixes French/English. Analyzer uses `flutter_lints`. Keep code concise, null-safe, and idiomatic Flutter.
Note on existing rules: `.github/instructions/best_practice.instructions.md` describes a “Vehicule builder” demo. That structure does not exist here. You can reuse general style points from it (Material 3, `const`/`final`, French labels), but follow the actual files and patterns below for this app.
## Big picture
- Entry: `lib/main.dart` → `MyStartApp` (MaterialApp with `ColorScheme.fromSeed(Colors.indigo)`), shows a top-end `Banner("Thomas D.")`, home is `StartPage`.
- Primary screen: `lib/start_page.dart` renders the wheel picker UI via `Generated2` (see below).
- Two wheel implementations exist:
- `lib/generated_1.dart` (`Generated1`, `WheelPainter`) – earlier version.
- `lib/widgets/generated2.dart` (`Generated2`, `_WheelPainter`) – current version used by `StartPage`.
- Custom painters draw the pie slices, labels, and a pointer; state is local (`setState`) with `AnimationController` for spin effects.
## Current patterns & conventions
- Keep UI strings in French where present (e.g., "Gagnant !", "Choisir le gagnant"). No i18n framework.
- Prefer `StatelessWidget`; use `StatefulWidget` + `setState` for local UI state only (text input, animation, selection).
- Constructors `const` when possible; fields `final`. Dispose controllers in `dispose()`.
- Small reusable UI pieces go in `lib/widgets/`. A barrel exists: `lib/widgets/widgets.dart`.
- Theming: use `Theme.of(context)` and Material 3 components; keep rounded corners (~18) and subtle elevation consistent with `Generated2`.
- Lints: follow `analysis_options.yaml` (inherits `flutter_lints`). Use `flutter analyze` to validate.
## Known quirks to mind
- `start_page.dart` imports `package:copitot_rules/widgets/name_picker_wheel.dart`, but that file is not present. The screen currently uses `Generated2`. Prefer importing from the barrel `widgets/widgets.dart` or the actual file `widgets/generated2.dart`. If you add `name_picker_wheel.dart`, export it from the barrel.
- There are two similar wheel implementations; avoid duplicating logic—prefer `Generated2` unless you are intentionally comparing versions.
## Typical workflows
- Install deps: `flutter pub get`
- Analyze: `flutter analyze`
- Run (hot reload): `flutter run` (select device; Android and web configs are present)
- Test: add widget tests under `test/*.dart` then `flutter test`
## Extension points and examples
- Adding a new widget:
- Place in `lib/widgets/your_widget.dart`.
- Export in `lib/widgets/widgets.dart` and import via `package:copitot_rules/widgets/widgets.dart`.
- Animation pattern (see `Generated2`):
- Mixin `SingleTickerProviderStateMixin`.
- Create/`dispose` `AnimationController` in `initState`/`dispose`.
- Drive `Tween<double>(begin: _currentAngle, end: targetAngle)` with a curved animation; update `_currentAngle` in the listener and call `setState`.
- On completion, compute winner index and show a dialog with the name.
- CustomPainter pattern:
- Compute `anglePerName = 2*pi / names.length`.
- Loop to draw arcs with `Colors.primaries[i % ...].withOpacity(0.8)`.
- Use `TextPainter` to draw labels at `radius * 0.65` along the mid-angle; draw a triangle pointer above the circle.
## When adding features
- Keep labels French where the UI already uses FR.
- Maintain the Material 3 look and spacing similar to `Generated2` (padding ~18, rounded corners ~18).
- Validate with `flutter analyze` and ensure controllers are disposed.
- If you introduce new public widgets, add minimal widget tests (wrap with `MaterialApp(home: Scaffold(body: widget))` and assert visible text/icons).
## Key files
- `lib/main.dart` – app entry, theme, banner, home.
- `lib/start_page.dart` – home screen using `Generated2`.
- `lib/widgets/generated2.dart` – current wheel UI + painter.
- `lib/generated_1.dart` – earlier wheel variant for reference.
- `lib/widgets/widgets.dart` – barrel export for widgets.
Questions or gaps? If anything above is unclear (e.g., desired barrel usage or which wheel to standardize on), ask for confirmation before broad refactors.
Instructions générées par le bouton de Vscode
Découvrons des design patterns dans Flutter 28 Sep 11:17 PM (26 days ago)
Qui n’a jamais ouvert un fichier et rencontré un fichier de 3000 lignes, un constructeur à rallonge, une logique métier mélangée à l’UI, et des if/else partout ? Et si on se posait une question simple : combien de temps perdez-vous à comprendre un widget « monstre » avant de le modifier sans crainte ?
Dans cet article, nous allons partir d’un cas concret transposé au domaine des véhicules (voiture, vélo, camion) pour montrer comment des design patterns classiques - Builder, Factory, Strategy, Template Method - transforment un code fragile en architecture claire, testable et extensible. Le code produit sera disponible sur un lien github à la fin de l’article ! Bonne lecture.
L’exemple d’aujourd’hui
Écrans d'exemple des fiches de véhicules
Une fiche véhicule doit :
- Afficher les informations clés d'un véhicule (nom, type).
- Inclure une icône de profil correspondant au type de véhicule.
- Afficher des spécifications globales (nombre de roues, type de moteur thermique/électrique).
- Afficher des spécifications spécifiques au véhicule
- Voiture : la marque, le modèle et l'immatriculation
- Vélo : le type
- Déclencher une action contextuelle spécifique (ex: affichage d'un message) lors d'un appui, sans boutons supplémentaires.
- Avoir des états différents selon le contexte (chargement, erreur, stable)
Quand un widget devient un monstre
Des constructeurs à rallonge : le cauchemar du développeur
Problème réel : 15+ paramètres par constructeur, répétitions, et risques d’erreurs.
Exemple (simplifié) d’un widget de fiche véhicule :
// AVANT - constructeur « voiture » verbeux
const VehicleWidgetCar({
required this.typeLabel,
required this.brand,
required this.model,
required this.imageUrl,
required this.onTap,
required this.title,
required this.subtitle,
required this.wheelCount,
required this.fuelType,
required this.doorCount,
required this.hasSunroof,
required this.registration,
required this.tryAgainButtonLabel,
required this.isLoading,
required this.isActionLoading,
super.key,
}) : vehicleType = VehicleType.car,
// … 8 autres champs initialisés à null pour d’autres types
bikeSpecificData = null,
truckSpecificData = null;Code verbeux de départ pour un widget fiche de voiture
Cette approche nuit gravement à la lisibilité du code, rendant la maintenance extrêmement complexe, et elle crée un couplage fort et indésirable entre les données, la logique métier et le rendu, ce qui complique les évolutions futures et l'ajout de nouvelles fonctionnalités. Ça devient un processus risqué, augmentant le risque d'oublis ou d'incohérences potentielles.
Un widget, toutes les responsabilités : violation du SRP
Le SRP (Single Responsibility Principle) dit qu’une classe ou un module doit avoir une seule raison de changer, c’est-à-dire une seule responsabilité.
Ce widget était responsable de la configuration des différents types (voiture, vélo, camion).
Il décidait également de l’affichage, intégrant la logique métier et il construisait l’UI en assemblant les différentes sections PUIS gérait l’état (chargement, erreurs).

Manque d’extensibilité et de testabilité
L'ajout d'un nouveau type (par exemple, vélo électrique) nécessite de modifier les constructeurs, la méthode build(), l'énumération, et d'implémenter des conditions à de TOUS les endroits.
L'écriture de tests unitaires impliquait l'instanciation de widgets complexes avec des dizaines de paramètres à chacun des tests
Une lisibilité impossible
Le widget présentait à lui-même plus de 3000 lignes indentées, on ne se retrouvait plus du tout.
// Pseudo code du widget
build() {
return Column(
if titre
Text(titre)
if vehicule.type == car
Text(model)
else if vehicule.type == bicycle
Text('bicycle')
if vehicule.showSpec && vehicule.spec != null
Text(vehicule.spec)
Bouton(
onTap
if(vehicule.type == car and vehicule.type != camion)
showVehiculeMoteur()
}Pseudo code pour la construction du widget de départ
Première étape avec un premier patron de conception
Utiliser le pattern Factory pour des constructeurs intelligents
On masque la complexité d’initialisation derrière une API simple. La fabrique est un patron de conception de création qui définit une interface pour créer des objets dans une classe mère, mais délègue le choix des types d’objets à créer aux sous-classes.

class VehicleWidget extends StatelessWidget {
const VehicleWidget._({required this.configuration, super.key});
final VehicleConfiguration configuration;
factory VehicleWidget.car({
required String typeLabel,
required String title,
required String subtitle,
required VoidCallback onTap,
required String buttonLabel,
required bool isActionLoading,
required VehicleSpecsData specs,
required EngineData engine,
Key? key,
}) => VehicleWidget._(
key: key,
configuration: CarConfiguration(
typeLabel: typeLabel,
title: title,
subtitle: subtitle,
onTap: onTap,
buttonLabel: buttonLabel,
isActionLoading: isActionLoading,
specs: specs,
engine: engine,
),
);
factory VehicleWidget.bicycle({
required String typeLabel,
required String title,
required String subtitle,
required VoidCallback onTap,
required String buttonLabel,
required bool isActionLoading,
required VehicleSpecsData specs,
bool isElectric = false,
Key? key,
}) => VehicleWidget._(
key: key,
configuration: BicycleConfiguration(
typeLabel: typeLabel,
title: title,
subtitle: subtitle,
onTap: onTap,
buttonLabel: buttonLabel,
isActionLoading: isActionLoading,
specs: specs,
isElectric: isElectric,
),
);
@override
Widget build(BuildContext context) => VehiculeCard(
header: VehiculeCardHeader(
vehicleType: configuration.typeLabel,
title: configuration.title,
subtitle: configuration.subtitle,
icon: configuration.buildIcon(),
),
specs: configuration.buildEngineSection(),
engine: configuration.buildSpecsSection(),
button: configuration.buildButton(),
);
}Code principal pour la première version de résolution du widget de fiche de véhicule
Le design de l'API se veut propre, garantissant une initialisation centralisée et sécurisée, ce qui facilite grandement la consommation par le code appelant. On utilise aussi une nouvelle classe en plus de la Factory qui va centraliser les informations des différents véhicules.
Cette classe de configuration utilise aussi un patron de conception qui est la strategy. La stratégie est un patron de conception comportemental qui permet de définir une famille d’algorithmes, de les mettre dans des classes séparées et de rendre leurs objets interchangeables. On encapsule la logique spécifique à chaque type via une sealed class pour la sûreté et l’exhaustivité.
abstract class VehicleConfiguration {
const VehicleConfiguration({
required this.typeLabel,
required this.title,
required this.subtitle,
required this.onTap,
required this.buttonLabel,
required this.isActionLoading,
});
final String typeLabel;
final String title;
final String subtitle;
final VoidCallback? onTap;
final String? buttonLabel;
final bool isActionLoading;
VehicleType get vehicleType;
Widget buildIcon();
Widget? buildSpecsSection();
Widget? buildEngineSection();
Widget? buildButton();
}
class CarConfiguration extends VehicleConfiguration {
@override
VehicleType get vehicleType => VehicleType.car;
}
class BicycleConfiguration extends VehicleConfiguration {
@override
VehicleType get vehicleType => VehicleType.bicycle;
}Code pour la création de classe Stratégie
Cependant, cette approche se limite à abstraire la modélisation du véhicule et de son contenu au sein d'une classe distincte. L'ajout de nouveaux véhicules demeure laborieux et la compréhension des mécanismes internes reste compliquée, malgré une simplification de la construction des widgets et une clarté augmentée des constructeurs.
Ici, VehicleConfiguration gère la distribution des données, l'interface utilisateur, la logique et l'état, ce qui ne résout pas le problème de base, mais le délègue simplement. On veut séparer les responsabilités pour pouvoir mieux les comprendre et mieux les tester. Alors allons-y !
Design Patterns à la rescousse
SRP comme fondation
On sépare les responsabilités en quatre rôles complémentaires, alignés avec le diagramme et le code :
- VehicleWidgetDirector (Director) : orchestre la construction, choisit quelles sections inclure et dans quel ordre (Header, Specs, Engine, Button).
- VehiculeCardBuilder (Builder) : assemblent la fiche, implémentent les différences par type
- VehicleCardConfiguration (notre Strategy qui devient Template Method) : porte les données nécessaires (typeLabel, title, subtitle, specs, engine, onTap, buttonLabel) ; pas de logique de rendu.
- VehiculeCard : widget final composé (Header, Specs, Engine, Button).

Choisir un design pattern qui correspond au mieux pour structurer données et logique métier : Template Method !
Notre classe VehicleConfiguration, notre stratégie va devenir une template method car elle va servir uniquement à fournir les détails des véhicules. Le design pattern Patron de Méthode est un patron de conception comportemental qui permet de mettre le squelette d’un algorithme dans la classe mère, mais laisse les sous-classes redéfinir certaines étapes de l’algorithme sans changer sa structure.
abstract class VehicleCardConfiguration {
const VehicleCardConfiguration({
required this.typeLabel,
required this.title,
required this.subtitle,
required this.onTap,
required this.buttonLabel,
});
final String typeLabel;
final String title;
final String subtitle;
final VoidCallback onTap;
final String buttonLabel;
VehicleType get vehicleType;
}
class CarCardConfiguration extends VehicleCardConfiguration {
const CarCardConfiguration({
required super.typeLabel,
required super.title,
required super.subtitle,
required super.onTap,
required super.buttonLabel,
required this.specs,
required this.engine,
});
final VehicleSpecsData specs;
final EngineData engine;
@override
VehicleType get vehicleType => VehicleType.car;
}
class BicycleCardConfiguration extends VehicleCardConfiguration {
const BicycleCardConfiguration({
required super.typeLabel,
required super.title,
required super.subtitle,
required super.onTap,
required super.buttonLabel,
required this.specs,
this.isElectric = false,
});
final VehicleSpecsData specs;
final bool isElectric;
@override
VehicleType get vehicleType => VehicleType.bicycle;
}Code de la template method la seconde version de résolution du widget de fiche de véhicule
Ce pattern améliore la clarté, une meilleure sécurité sur le type et une logique métier testable. Chaque implémentation de VehicleConfiguration agit comme un nouveau vehicule : le VehicleBuilder s’adapte au type sans conditions éparpillées. Ajouter TruckConfiguration n’implique pas de modifier le VehicleWidget : on respecte l’OCP (ouvert à l’extension, fermé à la modification).
Pattern Builder : construire l’UI pièce par pièce
On sépare la construction d’un widget complexe en méthodes modulaires qui s’appuient sur la configuration. Le Builder est un patron de conception de création qui permet de construire des objets complexes étape par étape. Il permet de produire différentes variations ou représentations d’un objet en utilisant le même code de construction. Lien pour la documentation pattern builder : Builder et de son Directeur
abstract class VehiculeCardBuilder {
VehiculeCardBuilder();
late String _vehicleType;
late String _title;
late String _subtitle;
late Widget _icon;
Widget? _specs;
Widget? _engine;
Widget? _button;
void withType();
void withTitle();
void withSubtitle();
void withIcon();
void withSpecs();
void withEngine();
void withButton();
Widget build() => VehiculeCard(
header: VehiculeCardHeader(
vehicleType: _vehicleType,
title: _title,
subtitle: _subtitle,
icon: _icon,
),
specs: _specs,
engine: _engine,
button: _button,
);
}
class CarBuilder extends VehiculeCardBuilder {
final CarCardConfiguration configuration;
CarBuilder({required this.configuration});
@override
void withEngine() {
_engine = CarEngineSection(engine: configuration.engine);
}
@override
void withIcon() {
_icon = CarIcon();
}
@override
void withSpecs() {
_specs = CarSpecSection(specs: configuration.specs);
}
@override
void withSubtitle() {
_subtitle = configuration.subtitle;
}
@override
void withTitle() {
_title = configuration.title;
}
@override
void withType() {
_vehicleType = configuration.vehicleType.name;
}
@override
void withButton() {
_button = VehiculeCardButton(
onTap: configuration.onTap,
buttonLabel: configuration.buttonLabel,
);
}
}
class BikeBuilder extends VehiculeCardBuilder {
final BicycleCardConfiguration configuration;
BikeBuilder({required this.configuration});
@override
void withEngine() {
_engine = null;
}
@override
void withIcon() {
_icon = BikeIcon();
}
@override
void withSpecs() {
_specs = BicycleSpecSection(specs: configuration.specs);
}
@override
void withSubtitle() {
_subtitle = configuration.subtitle;
}
@override
void withTitle() {
_title = configuration.title;
}
@override
void withType() {
_vehicleType = configuration.vehicleType.name;
}
@override
void withButton() {
_button = VehiculeCardButton(
onTap: configuration.onTap,
buttonLabel: configuration.buttonLabel,
);
}
}
class BikeLoadingBuilder extends BikeBuilder {
BikeLoadingBuilder({required super.configuration});
@override
void withIcon() {
_icon = CircularProgressIndicator();
}
@override
void withButton() {
_button = VehiculeCardButton(onTap: () {}, buttonLabel: 'LOADING');
}
}Code pour les Builders de la seconde version de résolution du widget de fiche de véhicule
Ce document offre une flexibilité appréciable, des sections réutilisables et une maintenance simplifiée. L’utilisation des mots clés late permettent d’avoir une erreur au runtime si les éléments obligatoires ont été oubliés par le directeur.

Pour notre exemple de fiche de véhicule, quelle que soit la méthode utilisée, nous avons besoin d’au moins un titre et un sous-titre, donc si il ne sont pas appelé par le Directeur au moment de la création, il y aura une late initialization error (documentation : https://www.dhiwise.com/post/understanding-the-late-initialization-error-in-flutter)
class VehicleWidgetDirector {
const VehicleWidgetDirector();
void buildCarCard(CarBuilder carBuilder) {
carBuilder
..withType()
..withTitle()
..withSubtitle()
..withIcon()
..withButton()
..withSpecs()
..withEngine();
}
void buildCarCardWithoutSpecs(CarBuilder carBuilder) {
carBuilder
..withType()
..withTitle()
..withSubtitle()
..withIcon()
..withButton();
}
void buildBikeCard(BikeBuilder bikeBuilder) {
bikeBuilder
..withType()
..withTitle()
..withButton()
..withSubtitle()
..withIcon()
..withSpecs();
}
void buildBikeCardWithNoButton(BikeBuilder bikeBuilder) {
bikeBuilder
..withType()
..withTitle()
..withSubtitle()
..withIcon()
..withSpecs();
}
}Directeur de la seconde version de résolution du widget de fiche de véhicule
Sautons ensemble à la longue conclusion
Comparaison synthétique
Pour notre première version avec les design pattern Strategy et Factory, le VehicleWidget opère la sélection d'une configuration spécifique par les factories, telles que CarConfiguration ou BicycleConfiguration. Chaque configuration expose directement les composants prêts à être affichés (icône, spécifications, moteur, bouton). Le VehicleWidget procède ensuite à la composition du widget final en assemblant ces différents éléments.
Le flux de travail est simple; chaque configuration détermine les éléments à exposer (exemple: il n’y a pas de moteur sur un vélo, à part vos jambes).
Pour notre seconde version avec ses Builder et son Director, le VehicleWidget instancie un Director qui orchestre les étapes de construction (withType/Title/Subtitle/Icon/Specs/Engine/Button). Un Builder concret (CarBuilder/BikeBuilder) lit une configuration de données (CarCardConfiguration/BicycleCardConfiguration). Le Director impose une séquence uniforme et peut faire varier les "recettes" (inclure/exclure des sections).
Le produit final est construit étape par étape, de manière explicite, plus lisible par rapport à la première version.
Avantages par approche
L'implémentation de la première version est simple et rapide, nécessitant moins de classes et de formalités. Le code est très lisible, surtout lorsqu'il y a peu de variantes et d'options. Chaque configuration encapsule ses choix d'interface utilisateur, ce qui facilite la compréhension locale. Ce modèle est idéal pour des écrans plus simples.
Le système de la seconde version offre une forte cohérence du rendu grâce à un directeur centralisé qui permet d'appliquer facilement différentes recettes (par exemple, "fiche d’une voiture sans spécifications", "fiche d’un vélo sans bouton") sans dupliquer la logique d'assemblage. Il est évolutif lorsque le nombre de variantes (voiture, vélo, camion, etc..) ou de sections (section moteur, section nombre de pédales, etc..) augmente.
Le système améliore la testabilité en séparant les tests du directeur, des constructeurs et de la configuration.
void main() {
testWidgets('BikeLoadingBuilder shows progress and overrides button', (tester) async {
// caractéristiques du vélo
final config = BicycleCardConfiguration(
...
);
// builder pour une fiche qui affiche un loader
final builder = BikeLoadingBuilder(configuration: config);
const director = VehicleWidgetDirector();
director.buildBikeCard(builder);
final widget = builder.build();
await tester.pumpWidget(MaterialApp(home: Scaffold(body: widget)));
expect(find.byType(CircularProgressIndicator), findsOneWidget);
expect(find.text('LOADING'), findsOneWidget);
// on vérfie que malgré que nous sommes sur une fiche vélo
// les comportements sont bien écrasés par notre builder
expect(find.byIcon(Icons.directions_bike), findsNothing);
});
}Exemple de code pour tester un cas de fiche de véhicule
De plus, il simplifie l'implémentation des feature flags et les tests A/B en permettant de changer de directeur ou de recette selon un flag.
Bénéfices concrets des patterns
| Pattern | Description |
| Factory | Simplifie l’instanciation des bonnes variantes (configurations ou builders) sans exposer les détails au reste du code. Rend l’appelant plus propre et réduit le couplage. |
| Strategy | Permute le comportement par type de véhicule sans if/switch partout. Isole ce qui varie (données/présentation spécifique) de ce qui reste stable (structure de la carte). Simplifie l’ajout d’un nouveau véhicule : on ajoute une stratégie.
|
| Template method | Favorise la réutilisation du code en centralisant les parties communes de l’algorithme, réduit la duplication en évitant de réécrire les mêmes enchaînements de logique, et apporte de la flexibilité car chaque sous-classe peut redéfinir uniquement les étapes qui varient sans toucher au squelette général. Garantit aussi une meilleure lisibilité et maintenabilité en rendant explicite ce qui est fixe et ce qui peut changer dans un processus. |
| Director | Centralise les recettes d’assemblage pour différents cas d’usage (ex : “car sans specs”). Sépare le “quoi/quand” (ordre, inclusion) du “comment” (Builder). Facilite l’expérimentation : on crée une nouvelle méthode du Director sans toucher aux Builders existants. |
| Builder | Gère la construction d’un objet complexe par étapes, avec sections optionnelles (engine parfois absent). Réduit le risque d’incohérence visuelle : même squelette, étapes explicites. Permet la réutilisation d’étapes (withHeader, withSpecs…) et favorise la DRYness.
|
Quand choisir quelle approche : Configurateur (sans Builder) vs. Builder + Director
Le choix entre l'utilisation d'un Configurateur simple et l'association Builder + Director dépend principalement de la complexité et des exigences de votre interface utilisateur.
Choisir la première version si vous avez:
- Peu de variantes, peu d’options conditionnelles.
- Besoin d’aller vite avec une complexité UI limitée.
- L’équipe préfère une API simple et un code plus direct.
Choisir la seconde version de notre système si vous avez:
- Plusieurs variantes, options conditionnelles multiples, recettes différentes du même écran.
- Exigence forte de consistance et d’évolutivité.
- Besoin de tests unitaires fins par étape et d’expérimentations guidées.
Risques et garde-fous
L'over-engineering est un risque, mais les patrons de conception restent des outils précieux. Nous avons exploré ensemble quelques exemples pour illustrer leur existence et leur utilité.
Si vous avez seulement une ou deux variantes simples, il est préférable d'éviter une utilisation prématurée de Builder/Director.
Par contre, il y a des inconvénients au configurateur. À mesure que le nombre de variantes augmente, le Configurateur seul peut entraîner une duplication de l'assemblage et des incohérences visuelles.
Alors partons sur un compromis recommandé, il faudrait commencer par le Configurateur. Puis passer à Builder + Director lorsque les variantes ou les "recettes" deviennent trop nombreuses. Dans les deux cas, conservez la Strategy pour la configuration des données.
Votre prochain pas avec les Design Patterns en flutter
Cette approche, portée par les design patterns (Builder, Factory, Strategy, Template Method), transforme un widget « monstre » en architecture modulaire et élégante. On gagne en lisibilité, testabilité, et capacité d’évolution - exactement ce qu’on attend d’un code durable.
Investir dans la qualité du code n’est pas un luxe : c’est un accélérateur de livraison.
Comme promis, voilà le projet avec les différentes versions : https://github.com/thomasdhulst/flutter-design-pattern-configuration-builder
Essayez ces patterns sur vos propres widgets : partagez vos retours, posez vos questions, et comparez vos avant/après.
Arrêtez de débugger votre code et commencez par débugger votre emploi du temps 23 Sep 11:00 PM (last month)

Vous passez des heures à traquer des bugs dans votre code, mais quand avez-vous débuggé votre emploi du temps pour la dernière fois ?
Pendant des années j’ai travaillé sans réelle stratégie d’organisation ou de planification. Cela me convenait très bien, je gardais les sujets importants dans ma tête. Mes mails, les dailys, les outils du projet me permettaient de rester à jour. Puis après quelques années je me suis heurté à un mur ! J’étais lead développeur d’une équipe de 10 développeurs et je n’arrivais plus à tout gérer.
Au fil de votre carrière vous allez certainement prendre de plus en plus de responsabilités, vous aurez peut-être plusieurs projets à la fois, vous serez peut-être responsables de certaines tâches en interne. Vous deviendrez peut-être lead ou manager. En tout cas, il est fort probable que la gestion de toutes ces activités en parallèle devienne bien plus complexe qu’au début de votre carrière.
Votre agenda est comme un programme mal optimisé : des fuites mémoires, des dépendances bloquantes, des exceptions non gérées, des boucles infinies ! Il est temps de le refactorer et de corriger tous ces bugs !
Aujourd’hui j’aimerais vous partager mon expérience afin de vous permettre d’identifier les bugs dans votre gestion du temps et les corriger, comme vous le feriez avec votre code.Cela vous permettra de réduire votre stress et votre charge mentale tout en vous donnant les moyens de vous investir dans les projets qui vous tiennent à cœur.
Disclaimer
Maîtriser son temps est très personnel. Je pense qu’il faut avant tout apprendre à se connaître et créer la méthode qui vous convient. Il existe de nombreuses méthodologies déjà existantes. Au cours de cet article je citerais celles dont j’ai emprunté des éléments et qui ont bien fonctionné pour moi, mais comme toujours je vous invite à faire des recherches et des tests par vous-même.
Détection des bugs

Tout comme il est parfois important d'arrêter de développer des nouvelles features pour corriger les problèmes présents dans la base de code, il faudra un peu de courage et d'honnêteté pour prendre du recul sur votre façon de travailler. Prenez le temps de vous arrêter au moins 1 heure pour vous auto-diagnostiquer.
Dans mon cas, il était urgent que je prenne le temps de ralentir mon activité pour faire ce diagnostic et comprendre quels étaient les bugs de ma gestion du temps. Pourquoi avais-je toujours cette impression de courir partout et de ne pas réussir à tout faire ?
Pour cette étape de diagnostic je vous propose d’établir votre liste de tâches et de les caractériser :
- Regardez votre agenda des dernières semaines (dans mon cas j’ai utilisé un sprint de 3 semaines comme référence) et faites la liste de toutes vos activités.
- Comparez cette liste à celle des tâches correspondants à votre poste.
- Évaluez l’importance de chaque action pour la réussite du projet (principale ou secondaire)
- Évaluer le temps que vous consacrez à chaque activité
Avec cette comparaison vous devriez vous rendre compte de ce qui vous prend le plus de temps. Est-ce que ce sont vraiment les tâches principales ?
Mon exemple
Sur 25 tâches différentes j’ai trouvé 11 tâches que je n’avais simplement pas le temps de faire. Dont certaines très importantes pour le projet et d’autres pour lesquelles j’étais triste de ne pas pouvoir y consacrer du temps. Suite à la montée en charge de l’équipe je n’avais plus vraiment le temps de développer, encore moins de faire de la veille techno ou d’animer des coding dojo. Mais en parallèle de ça je consacrais parfois ½ journée à des tâches peu importantes.
De plus, j'ai remarqué que je consacrais parfois la moitié de mon temps de travail à répondre aux sollicitations des autres membres de l’équipe au détriment des mes propres tâches.
Réalisme, indulgence et ténacité
Une fois ce constat fait, il faut maintenant changer vos habitudes. Pour cela il faudra faire preuve de 3 qualités : réalisme sur vos objectifs, indulgence sur vos résultats et ténacité face aux obstacles. Dans mon cas j’ai décidé de prendre 2 sprints de 3 semaines pour mettre en place certains conseils et une méthodologie de gestion du temps.
Refactorer sa liste de tâches avec la priorisation

Suite à mon analyse, il était devenu évident que j’avais un problème avec le nombre de tâches dont je m’estimais responsable. Il me fallait donc apprendre à mieux les prioriser et ne pas me disperser.
Tout comme un code bien organisé permet de gagner en efficacité, une liste de tâches et un agenda “clean” seront vos meilleurs alliés dans votre gestion du temps.
Distinguer l’importance de l’urgence
Pour faire rentrer dans mon planning hebdomadaire les tâches les plus importantes, j’ai utilisé une variante de la matrice d’Eisenhower. Celle-ci permet de déterminer 6 niveaux de priorités en fonction de l’importance et de l’urgence de la tâche à accomplir.
L’urgence d’une tâche augmente au fur et à mesure que son échéance approche.
L’importance d’une tâche est proportionnelle aux risques liés à sa non-réalisation et aux gains de sa réalisation.
Vous pouvez utiliser le tableau de priorisation suivant pour déterminer la priorité de chaque tâche (de P1 à P6).
Les tâches P1 à P3 sont très importantes pour moi ou les autres.
Celles de P4 à P6 sont des tâches moins importantes.
Les P1 et P4 sont urgentes pour aujourd'hui
Les P2 et P5 sont urgentes pour cette semaine
Les P3 et P6 ne sont pas urgentes pour cette semaine
Selon le niveau de priorité la façon de traiter la tâche doit être différente :
- P1 Je réalise la tâche immédiatement
- P2 et P3 Je programme cette tâche dans mon agenda
- P4 Je délègue ou je réalise seulement si je n’ai aucune tâche P1 à P3 de prévu aujourd’hui
- P5 Je délègue ou je raye de la liste
- P6 je raye de la liste
En détectant et en supprimant les tâches P4 à P6 vous vous dégagerez le temps d’accomplir sereinement les tâches les plus importantes.
Anticipation à 3 semaines
De plus, les P1 (et même les P2) devraient être exceptionnelles. En effet, il est rare de découvrir une tâche importante au dernier moment. Et même si c’est devant le mur qu’on voit le mieux… le mur, il est trop tard pour l’éviter.
Planifier vos tâches P3 à l’avance permet d’utiliser tout l’arsenal des solutions disponibles (analyser, déléguer, demander de l’aide, organiser une réunion… etc) plutôt que de traiter seul et dans le rush car la deadline approche. Avec de l’anticipation il est souhaitable de consacrer 60% de son temps aux tâches P3 (les plus importantes mais non urgentes).
Fix: Planification et Time blocking
Maintenant que vous avez les idées claires grâce à cette analyse et ce refacto, il devient beaucoup plus facile de corriger les bugs ! Une liste de tâches caractérisées et priorisées est bien plus facile à insérer dans un emploi du temps.
Construire un agenda réaliste
Voici ma méthode pour construire mon agenda. J’ai choisi de construire celui-ci sur 3 semaines car c’est la durée d’un sprint et que cela permet d’anticiper suffisamment à l’avance les tâches P3. J’utilise principalement la méthodologie “Time-blocking”. Cela consiste à réserver à l’avance des plages de travail pour vos activités.
L’agenda se compose de 2 types de créneaux
- Les tâches programmées. Programmer une tâche signifie lui dédier un horaire fixe.
- Définissez les limites de vos journées. Soyez réalistes sur vos heures de début et de fin de journée. De même que pour vos temps de pauses. Cela vous évitera de déborder sur votre vie perso.
- Programmez à l’aide d’un rdv (si ce n’est pas déjà fait) toutes les réunions récurrentes (daily meeting, rétrospective, point d’équipe… etc)
- Programmez un créneau pour vos activités récurrentes même si cela ne concerne que vous.
L’ensemble des éléments programmés ne doit pas dépasser 30% de votre temps. Ce sont les points fixes de votre agenda et permettent d’avancer en terrain connu. Si elles sont trop nombreuses vous perdrez en souplesse. Si c’est le cas pour vous, il est important de questionner ces créneaux et de se demander si cela concerne vraiment votre activité principale.
- Les tâches planifiées. Planifier une tâche c’est réserver du temps pour cette tâche mais sans réserver un créneau précis. Idéalement 40% de votre temps devrait leur être dédiés. Pour celles-ci j’ai pris l’habitude de définir des créneaux mais sans préciser à l’avance ce que je ferais exactement : (2h de développement, 1h de pair programming, 1h de veille technique… etc). Cela me permet de sanctuariser du temps pour les tickets.
Répondre aux sollicitations
De mon côté j’avais 2 problèmes principaux. J’étais invité à beaucoup trop de réunions pour me laisser le temps de réaliser mes tâches personnelles, de plus j’étais souvent interrompu par des sollicitations extérieures du fait de la taille de mon équipe.
Le Time Blocking m’a beaucoup aidé à résoudre ces problèmes. Je sais d’avance que si j’accepte d’aider un collègue sur un des créneaux dédiés à un développement cela aura un impact sur le délai de réalisation de mon ticket. Je peux ainsi décider si j’ai le temps d’aider ce collègue ou si mon ticket est plus prioritaire. Lorsque je suis sur une tâche critique je peux signaler aux autres mon indisponibilité et quand je serai en mesure de les aider.
De la même manière, cette vision de mon agenda sur 3 semaines me permet de savoir quand je dois refuser une réunion ou envoyer un autre développeur à ma place.
Laissez respirer votre planning !
Le fait de remplir son agenda à 100% est un autre bug très courant. Il est important de laisser des créneaux libres pour les imprévus dans l’emploi du temps. On estime qu’il faut entre 20 à 30% du temps libre pour gérer sereinement ces imprévus.
De plus, essayez au maximum de garder ces créneaux libres jusqu’au dernier moment. Cela vous permettra de gérer les urgences sereinement. On ne sait jamais quand un bug critique surgira en prod ou quand l’un de vos développement prendra du retard.
Dans le cas où tout va bien, ces créneaux me permettent souvent d’aller aider mes collègues et de répondre aux nombreuses sollicitations que j’ai mises de côté plus tôt dans la journée.

Amélioration continue - la weekly review
Une des choses les plus importantes à accepter pour bien gérer son temps est que cela prend du temps. Tout comme j’étais déjà convaincu du gain de temps apporté par les tests unitaires et les code review, ma dernière expérience m'a convaincu de l'intérêt de cette weekly review.
Il faut impérativement consacrer un peu de temps à la planification pour ne pas se laisser submerger par les tâches et ne pas se faire surprendre par des urgences.
Vers le futur
Pour cela je vous conseille de réserver un créneau hebdomadaire d’1 heure pour faire le point. Cette pratique est souvent appelée la weekly review. C’est un moment que vous prenez toutes les semaines pour anticiper les 3 prochaines semaines à venir. C’est le moment d’appliquer la méthodologie expliquée dans le chapitre précédent.
- Vérifier vos mails et messageries instantanées pour ajouter les tâches à votre liste de tâches.
- Priorisez les tâches qui ne le seraient pas encore.
- Programmez dans votre agenda les réunions récurrentes. N’oubliez pas d’ajouter un créneau pour préparer la réunion et pour faire un compte rendu.
- Programmez ou planifiez des créneaux pour traiter vos tâches de priorités P2 et P3
- Programmez des créneaux pour gérer les imprévus.
Mais aussi le passé
Cette review est aussi le moment parfait pour faire le point avec vous-même sur les semaines précédentes. Tout comme une rétrospective en méthodologie agile c’est un temps consacré à l’amélioration continue. Cet aspect est particulièrement important lors des 6 premières semaines de changement dans votre façon de vous organiser.
Relancez-vous dans une phase de diagnostic et de debug ! Etes-vous satisfait de comment vous vivez vos semaines de travail ? Avez-vous eu le temps d’accomplir vos tâches importantes ?
Bilan de journée
Il sera souvent nécessaire d’actualiser votre agenda quotidiennement. Pour cela, réservez-vous 10 minutes pour faire le bilan de la journée. Personnellement j’aime bien le faire en fin de journée mais vous trouverez peut-être plus facile de faire ce bilan en arrivant le matin.Avez-vous terminé toutes les tâches importantes qui étaient prévues ? Si ce n’est pas le cas, il sera nécessaire de modifier votre plan pour la prochaine journée.
Est-ce que de nouvelles tâches importantes ou urgentes doivent être planifiées ?
Dans le cas échéant, il est important de bien prendre le temps de modifier votre liste de tâches et votre agenda pour les jours suivants. Dans le cas contraire, vous serez très content de réaliser que vous avez terminé tout ce que vous deviez faire aujourd’hui !
Le "Pair Programming" du lead
Afin de me libérer du temps dans la semaine j’ai eu besoin d’apprendre à mieux déléguer. Il y avait trop de tâches que je faisais seul et l’information ne circulait pas assez dans l’équipe. Finalement un lead dev qui ne délègue pas c’est comme une fonction qui fait tout : plus personne ne sait ce qu’elle fait vraiment…
La solution évidente à ce problème est de travailler en pair. Pour cela nous avons d’abord réalisé ces tâches ensemble puis quand les développeurs ont été autonomes j’ai pu complètement leur confier ces responsabilités.
Le fait de confier certaines tâches à d’autres membres de l’équipe était indispensable, au vu de la taille de l’équipe, et a permis à tout le monde de progresser et de mieux communiquer. En plus de cela j’y ai trouvé une satisfaction personnelle car j’ai réussi à retrouver le temps de développer. J’avais en effet moins de tâches différentes à accomplir et de réunions à suivre.
Conclusion
En tant que développeur.se, la gestion du temps est trop souvent survolée ou oubliée. Cependant il est très important de prendre soin de son emploi du temps, tout comme vous prenez soin de votre code.
Réserver des créneaux pour planifier mes semaines et accomplir mes tâches a vraiment été salvateur en tant que lead dev. Cela m’a pris plusieurs sprints pour reprendre le contrôle sur mon agenda mais je pense que le travail d’introspection accompli m’a énormément fait progresser. Je vous invite fortement à faire de même, avant de vous retrouver complètement sous l’eau !
Soyez courageux pour prendre du recul et détectez vos bugs.
Consacrez du temps à la gestion de votre agenda pour simplifier le reste de votre semaine et vous alléger l’esprit.
Anticipez et priorisez vos tâches pour créer de la confiance.
Sources
- Le livre les 5 cles pour gerer son temps - Dunod - CSP - Frederic Dulieu
- Todoist guides and videos - Beginner's Guide to The Weekly Review
- Todoist - Getting-things-done
- Todoist - Eisenhower-matrix
- Asana - Eisenhower-matrix
- Orga-milena - Time-blocking
Factoriser des déclarations de dépendances sur Android avec Gradle 21 Sep 10:34 PM (last month)

Lorsque votre application Android commence à grossir ou lorsque vous avez des portions que vous souhaitez isoler fortement les unes des autres, il y a de fortes chances que vous vous dirigiez vers une architecture multi-module. Si on se réfère à la documentation Android, on trouvera parmi les bénéfices recherchés :
| Bénéfice | Description |
|---|---|
| Réutilisabilité | La modularisation ouvre des possibilités de partage de code et de création de plusieurs applications à partir de la même base. Par exemple, une bibliothèque d’authentification pourrait être réutilisée dans une autre application. |
| Strict contrôle de la visibilité | Les modules, en particulier en kotlin avec le mot clé internal, vous permettent de contrôler facilement ce que vous souhaitez exposer. |
| Livraison personnalisée | Play Feature Delivery est une fonctionnalité qui vient avec les app bundles. Elle permet de livrer certaines fonctionnalités de votre application de manière conditionnelle ou à la demande. Par exemple, un utilisateur téléchargera un niveau d’un jeu vidéo seulement une fois qu’il sera débloqué. L’avantage étant de réduire la taille de l’application lors du premier téléchargement. |
Comme l’indique aussi la documentation officielle, modulariser est une manière d’atteindre ces autres bénéfices :
| Bénéfice | Description |
|---|---|
| Découplage / Encapsulation | Modulariser pousse à séparer le code en fonction de ses responsabilités, réduisant le risque de code spaghetti. |
| Facilitation de la gouvernance | Il est plus facile de faire travailler plusieurs équipes sur la même application en ayant des modules distincts. Un module A peut être affecté à une équipe X et un module B à une équipe Y. |
| Testabilité | Puisque l’isolation des modules est censée être plus grande, c’est aussi censé être plus facile de tester en isolation ces mêmes modules. |
| Temps de build | Gradle, qui est l’outil le plus utilisé pour construire des applications Android, se marie très bien avec la modularisation. Gradle utilise de la compilation incrémentale, du cache de build et de la parallélisation de build, ce qui est idéal avec des modules isolés. |
| Passage à l’échelle | Tout cela contribue à aider le passage à l’échelle de votre application, là où sinon des problèmes organisationnels et / ou de temps de compilation peuvent survenir. |
Voici un exemple d’app multi modules que je décrivais sur le blog Ippon dans cet article :
Chaque bloc est un module. Le découpage choisi à l’époque en 2020 est perfectible, mais l’idée étant de donner un exemple de ce que cela peut donner !
Module Android et module Gradle
Un module Android se traduit donc par un module Gradle. Lorsque vous en créez un via Android Studio (clic droit sur le dossier parent du projet -> new -> Module), on découvre qu’il en existe plusieurs types :
Votre choix déterminera la structure des dossiers généré sera et le type de plugin gradle importé. Par exemple, si votre module est une application, com.android.application sera importé.
Ci-dessous un exemple pour le module app, dans le fichier build.gradle.kts, qui déclare dans ses plugins alias(libs.plugin.android.application).
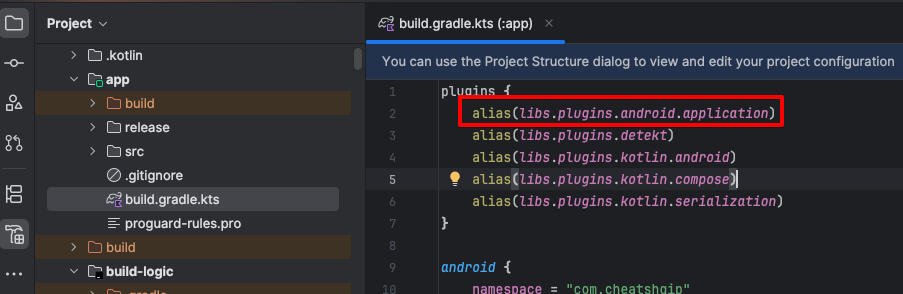
C’est une instruction qui correspond à une entrée dans nos version catalogs :
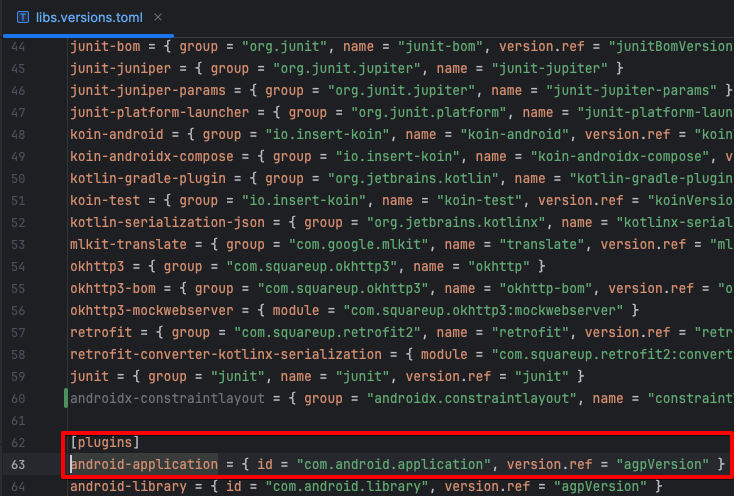
Si votre module est une bibliothèque, alors ça sera le même principe mais avec en plugin com.android.library de déclaré.
Version catalogs
Les version catalogs sont une fonctionnalité de gradle qui enrichit la manière de gérer les dépendances. Dans une manière plus classique, une dépendance est importée comme cela dans un fichier build.gradle.kts :
dependencies {
implementation("<group>:<name>:<version>")
}
La problématique, c’est que si la dépendance doit être réutilisée ailleurs dans un autre module, il faut exactement écrire la même chose pour chaque module consommateur. On prend donc le risque d’avoir une version différente ou même un artefact différent. À la lecture, on ne peut pas déterminer que les dépendances doivent être les mêmes.
Les version catalogs apportent des réponses en externalisant ces déclarations dans un ou plusieurs fichiers .toml visibles de tous les modules du projet. Ce fichier se situe par défaut dans le répertoire gradle à la racine du projet :
Dans ce fichier on définit tout d’abord des versions, ensuite des libraries et enfin des plugins :
[versions]
activityComposeVersion = "1.10.1"
agpVersion = "8.12.0"
...
[libraries]
android-gradle-plugin = { group = "com.android.tools.build", name = "gradle", version.ref = "agpVersion" }
androidx-activity-compose = { group = "androidx.activity", name = "activity-compose", version.ref = "activityComposeVersion" }
...
[plugins]
android-application = { id = "com.android.application", version.ref = "agpVersion" }
android-library = { id = "com.android.library", version.ref = "agpVersion" }
Des accesseurs sont générés automatiquement à la compilation. Il y a alors de l’autocomplétion lorsque les dépendances sont importées et la réutilisabilité est facile. Pour android-activity-compose on passerait alors de :
dependencies {
implementation("android.activity:activity-compose:1.10.1")
}
À :
dependencies {
implementation(libs.androix.activity.compose)
}
Note : libs est le préfixe utilisé par défaut comme répertoire de nommage pour tout ce qui est généré depuis le bloc libraries. Pour les plugins gradle, un suffixe plugins est ajouté à libs. On a alors pour un plugin android-library :
dependencies {
alias(libs.plugins.android.library)
}
Gestion des dépendances
Depuis l’introduction de AndroidX, les dépendances d’une application Android sont bien plus atomiques. C’est bien pour alléger l’application. En revanche, cela augmente le nombre de dépendances à spécifier dans les fichiers de configuration. Pour donner un ordre de grandeur, j’ai plus de 60 entrées (versions + dépendances) dans le fichier TOML de mon application, alors qu’elle ne se compose que de 3 écrans.
Le constat, c’est qu’un module de notre application a souvent entre 80 et 100% de dépendances communes avec un autre module d’un même archétype. J’entends par là deux modules dédiés à la création d’écrans, ou deux modules plutôt orientés métier. Le challenge est alors d’aller un cran plus loin dans la gestion des dépendances pour factoriser leurs déclarations.
Notes :
- L’environnement utilisé pour les tests ci-dessous est AGP 8.12.1, Gradle 8.14.3, Java 21 et Android Studio Narwhal Feature Drop 2025.1.2 Patch 1.
- Attention : sur Gradle 9.0.0 gradle essaie de résoudre des dépendances à chaque build, ce qui le ralentit de plusieurs secondes. C’est un bug ouvert sur GitHub.
Bundle
Les version catalogs offrent une offre fonctionnalité intéressante : les bundles. Comme son nom laisse supposer, il s’agit là de regrouper des dépendances ensemble pour les importer ensemble en une seule fois. Si vous connaissez Maven, cela vous rappellera les BOM. Voici l’exemple de la documentation :
[versions]
groovy = "3.0.9"
[libraries]
groovy-core = { group = "org.codehaus.groovy", name = "groovy", version.ref = "groovy" }
groovy-json = { group = "org.codehaus.groovy", name = "groovy-json", version.ref = "groovy" }
groovy-nio = { group = "org.codehaus.groovy", name = "groovy-nio", version.ref = "groovy" }
[bundles]
groovy = ["groovy-core", "groovy-json", "groovy-nio"]
Le bundle groovy est ensuite importé dans les dépendances :
dependencies {
implementation(libs.bundles.groovy)
}
Malheureusement, cela ne concerne pas les dépendances définies dans le bloc plugins. Impossible alors en une seule instruction de définir qu’un module importe x plugins et y dépendances.
Plugins gradle
Gradle fonctionne avec des plugins. Il en existe 4 grandes familles :
- Scripts plugins
- Precompiled script plugin
- BuildSrc / Convention plugin
- Binary Plugin
Script plugin (apply from file)
Une ancienne manière de faire était d’importer tout un fichier de configuration dans les modules où on souhaite le partager.
Prenons par exemple un fichier appelé configuration.gradle qui contient :
dependencies {
implementation(libs.bundles.groovy)
}
Pour appliquer ces dépendances dans chaque build.gradle.kts de nos modules, il faut alors écrire en haut du fichier :
apply("$rootDir/configuration.gradle")
plugins {
/* ... */
Notez bien ici que configuration.gradle est un fichier gradle simple, pas en kotlin script. Avec un fichier gradle.kts on ne peut pas faire cette même “magie” simplement.
Il s’agit d’une manière legacy de faire. On perd en performance puisqu’il faut fusionner les instructions spécifiées dans notre nouveau fichier avec celles contenues dans chaque module. Le script n’est pas compilé mais réinterprété à chaque fois. Il n’y a enfin pas non plus de sécurité à la compilation puisqu’on importe le script via une chaîne de caractères.
Script plugin (apply from file) - variante
La documentation de gradle propose aussi de définir un plugin comme ceci :
class CommonDependenciesPlugin : Plugin<Project> {
override fun apply(project: Project) {
val libs = the<LibrariesForLibs>()
project.dependencies {
add("implementation", platform(libs.androidx.compose.bom))
}
}
}
apply<CommonDependenciesPlugin>()
Malheureusement, malgré toutes mes tentatives, si le script kotlin est en dehors de certains dossiers spéciaux, la classe n’est pas reconnue correctement :
Caused by: java.lang.IllegalArgumentException: Class Common_gradle.CommonDependenciesPlugin is a non-static inner class
En fait, lors de la compilation kotlin, chaque script est relié à une classe kotlin. Dans notre exemple, gradle va créer une classe pour common-dependencies-plugin.gradle.kts, et va donc définir comme classe interne CommonDependenciesPlugin. Or, il semblerait que Gradle ait besoin de static pour travailler avec des plugins. Les classes internes ne sont pas static par défaut.
Precompiled Script Plugins
D’après la documentation, ce sont des scripts Groovy ou Gradle compilés et distribués au travers de bibliothèques. Ils sont appliqués via le bloc plugins d’un projet.
Par exemple, si un plugin contient dans un fichier plugin/src/main/kotlin/my-plugin.gradle.kts :
// This script is automatically exposed to downstream consumers as the `my-plugin` plugin
tasks {
register("myCopyTask", Copy::class) {
group = "sample"
from("build.gradle.kts")
into("build/copy")
}
}
Alors la tâche myCopyTask sera accessible dans tous les projets qui intégreront my-plugin comme ceci :
plugins {
id("my-plugin") version "1.0"
}
Gradle détermine automatiquement qu’il s’agit d’un plugin à partir du fichier .gradle.kts
BuildSrc et Convention Plugins
Il s’agit d’un format intermédiaire entre les Binary Plugins et les Precompiled Script Plugins. buildSrc est un module spécial qui est automatiquement compilé et inclus au projet si votre répertoire source a cette structure :
root/
├─ build.gradle (or build.gradle.kts)
├─ settings.gradle (or settings.gradle.kts)
├─ buildSrc/
│ ├─ src/main/kotlin (or java)
│ │ └─ ... Kotlin/Java classes
│ └─ build.gradle.kts
Le dossier buildSrc a besoin d’un fichier build.gradle.kts minimal comme celui-ci :
plugins {
`kotlin-dsl`
}
repositories {
google()
mavenCentral()
}
Ensuite, l’idée est de définir ensuite une structure que l’on souhaite voir partagée. Prenons en exemple un fichier buildSrc/src/main/kotlin/common-dependencies.gradle.kts :
val libs = project.extensions.getByType<VersionCatalogsExtension>().named("libs")
dependencies {
add("implementation", libs.findLibrary("androidx-activity-compose").get())
}
Ici, on récupère dynamiquement les versions définies dans les versions catalogs. Il serait aussi envisageable de se passer des versions catalogs et de définir les versions et dépendances à ajouter directement en Kotlin. On ajoute aussi dynamiquement des entrées aux dépendances avec la méthode add. L’inconvénient c’est que l’on perd la sécurité à la compilation.
Pour factoriser aussi la déclaration de plugins, on les ajoute de manière programmatique :
val libs = project.extensions.getByType<VersionCatalogsExtension>().named("libs")
project.pluginManager.apply(libs.findPlugin("android-application").get().get().pluginId)
dependencies {
add("implementation", libs.findLibrary("androidx-activity-compose").get())
}
Par défaut, un bloc plugins sera chargé avant l’évaluation des version catalogs. buildSrc n’a pas la vue non plus sur les plugins définis ailleurs dans le projet. Si on veut alors plutôt que charger le plugin en déclaratif que de manière programmatique :
val libs = project.extensions.getByType<VersionCatalogsExtension>().named("libs")
plugins {
id("com.android.application")
}
dependencies {
add("implementation", libs.findLibrary("androidx-activity-compose").get())
}
Ceci conduit à cette erreur :
* Exception is:
org.gradle.api.plugins.UnknownPluginException: Plugin [id: 'com.android.application'] was not found in any of the following sources:
- Gradle Core Plugins (plugin is not in 'org.gradle' namespace)
- Included Builds (No included builds contain this plugin)
- Plugin Repositories (plugin dependency must include a version number for this source)
À l’usage dans un module, il faut appliquer le plugin comme ceci :
plugins {
id("common-dependencies")
}
Le plugin est automatiquement référencé en fonction du nom du fichier dans lequel il est déclaré.
Binary Plugins
Ce sont des plugins compilés et distribués en tant que JAR dans le projet. L’objectif ici est de publier en local des plugins qui contiennent toute la factorisation de dépendances. C’est la manière la plus performante de distribuer des plugins gradle en local. En effet, il s’agit de code compilé, mis donc en cache entre deux builds.
La déclaration de ce plugin va suivre à peu près ce qu’il se fait pour buildSrc. Il faut commencer par créer un répertoire build-logic (ou qui porte le nom que vous voulez) dans votre projet. Puisqu’un JAR sera distribué, il aura un nom de package. La structure des sources change alors aussi pour avoir le package : src/main/kotlin/my/package si le package est my.package.
root/
├─ build.gradle (or build.gradle.kts)
├─ settings.gradle (or settings.gradle.kts)
├─ build-logic/
│ ├─ src/main/kotlin/my/package (or java)
│ │ └─ ... Kotlin/Java classes
│ └─ build.gradle.kts
│ └─ settings.gradle.kts
Ce module n’est pas compilé automatiquement par gradle. Il faut alors l’enregistrer dans les settings.gradle.kts parent. Puisqu’on distribue des plugins, cela se fait au niveau du bloc pluginManagement :
pluginManagement {
includeBuild("build-logic") // Inclusion du plugin
repositories {
google {
content {
includeGroupByRegex("com\\.android.*")
includeGroupByRegex("com\\.google.*")
includeGroupByRegex("androidx.*")
}
}
mavenCentral()
gradlePluginPortal()
}
}
dependencyResolutionManagement {
repositoriesMode.set(RepositoriesMode.FAIL_ON_PROJECT_REPOS)
repositories {
google()
mavenCentral()
}
}
Ce module doit aussi contenir un fichier settings.gradle.kts local pour activer les version catalogs et récupérer les dépendances du module :
dependencyResolutionManagement {
repositories {
google {
content {
includeGroupByRegex("com\\.android.*")
includeGroupByRegex("com\\.google.*")
includeGroupByRegex("androidx.*")
}
}
mavenCentral()
}
versionCatalogs {
create("libs") {
from(files("../gradle/libs.versions.toml"))
}
}
}
rootProject.name = "build-logic"
Le fichier build.gradle.kts de build-logic change aussi :
import org.gradle.initialization.DependenciesAccessors
import org.gradle.kotlin.dsl.support.serviceOf
plugins {
`kotlin-dsl`
}
dependencies { compileOnly(files(gradle.serviceOf<DependenciesAccessors>().classes.asFiles))
}
gradlePlugin {
plugins {
register("moduleAndroidPresentation") {
id = "com.cheatshqip.module.android.presentation"
implementationClass = "com.cheatshqip.build_logic.AndroidPresentationModulePlugin"
}
}
}
Il y a ici en dépendances les classes utilisées par DependenciesAccessor. C’est un service interne de gradle qui est utilisé avec les version catalogs. Il expose notamment la classe LibrariesForLibs. Elle représente le mapping Kotlin du contenu du fichier toml des versions catalogs.
Le bloc gradlePlugin sert à enregistrer le plugin que nous sommes en train de créer. On spécifie son identifiant (id) et la classe qui est le point d’entrée du plugin. Ici AndroidPresentationModulePlugin.
Enfin, justement cette classe contient le code suivant :
class AndroidPresentationModulePlugin : Plugin<Project> {
override fun apply(target: Project) {
with(target) {
val libs = the<LibrariesForLibs>()
with(pluginManager) {
apply(libs.plugins.kotlin.compose.get().pluginId)
}
dependencies {
implementation(libs.androidx.navigation.compose)
implementation(libs.androidx.lifecycle.runtime.ktx)
implementation(platform(libs.androidx.compose.bom))
implementation(libs.androidx.compose.foundation)
implementation(libs.androidx.activity.compose)
implementation(libs.androidx.ui)
implementation(libs.androidx.ui.graphics)
implementation(libs.androidx.ui.material3)
implementation(libs.androidx.ui.tooling.preview)
}
}
}
}
private fun DependencyHandler.implementation(dependencyNotation: Any) {
add("implementation", dependencyNotation)
}
private fun DependencyHandler.testImplementation(dependencyNotation: Any) {
add("testImplementation", dependencyNotation)
}
private fun DependencyHandler.androidTestImplementation(dependencyNotation: Any) {
add("androidTestImplementation", dependencyNotation)
}
Les fonctions privées implementation, testImplementation et androidTestImplementation servent à copier le DSL que nous utilisons habituellement dans un bloc dependencies pour déclarer nos dépendances.
Grâce à LibrariesForLibs nous avons accès aux dépendances utilisées lors de la compilation. C’est un vrai confort d’avoir de l’autocomplétion dans cette situation.
La classe AndroidPresentationModulePlugin implémente l’interface Plugin<Project>. En surchargeant la méthode apply, on a alors accès au Project sur lequel le plugin est appliqué. Via le pluginManager, on ajoute le plugin gradle jetpack compose et via le bloc dependencies on ajoute toutes les bibliothèques graphiques nécessaires pour travailler avec Jetpack Compose.
À l’usage, on importe le plugin par son id. On peut ajouter au préalable une entrée dans les version catalogs si on ne souhaite pas travailler avec des chaînes de caractères :
[plugins]
/* */
cheatshqip-module-android-presentation = { id = "com.cheatshqip.module.android.presentation" }
Puis, le plugin est ajouté dans le bloc dédié des modules, dans leurs fichiers build.gradle.kts :
plugins {
/* */
alias(libs.plugins.cheatshqip.module.android.presentation)
/* */
}
Conclusion
buildSrc (convention plugins) et les binary plugins sont les moyens préconisés par gradle pour partager de la logique de configuration. Si les binary plugins sont un peu plus compliqués à mettre en place, ils offrent plus de possibilités et surtout de meilleures performances. buildSrc présente par exemple comme limite le fait que le moindre changement en son sein conduit à l’invalidation de l’ensemble du paramétrage du projet, et donc à sa recompilation. Amusez-vous bien !
Sources
- Modularisation Android : https://developer.android.com/topic/modularization
- Play Feature Delivery : https://developer.android.com/guide/playcore/feature-delivery
- Code Spaghetti : https://en.wikipedia.org/wiki/Spaghetti_code
- Gradle Version Catalogs : https://docs.gradle.org/current/userguide/version_catalogs.html
- Maven BOM : https://www.baeldung.com/spring-maven-bom
- Kotlin Visibility Modifiers : https://kotlinlang.org/docs/visibility-modifiers.html
- O2, une App Offline-First déclinable : https://blog.ippon.fr/2020/06/24/o2-une-app-offline-first-declinable
- AndroidX : https://developer.android.com/jetpack/androidx
- Plugins gradle : https://docs.gradle.org/current/userguide/plugins.html
Devstral, votre compagnon de code en local 16 Sep 11:00 PM (last month)

iChaque exemple cité dans cet article a été réalisé avec succès grâce à Devstral, même s’il n’est pas toujours présenté visuellement.
Qu'est-ce que Devstral ?
Mistral AI a annoncé le lancement de Devstral, un nouveau modèle open source orienté ingénierie logicielle le 21 mai 2025.
Devstral est un modèle LLM agentique open source, conçu principalement pour les tâches de développement logiciel, c’est-à-dire la résolution de problèmes de programmation multi‑étapes dans de grands projets de code. Ce modèle est finement optimisé pour les agents de codage autonomes, capables de naviguer dans des bases de code complexes, modifier plusieurs fichiers, proposer des corrections tout en agissant de manière “agentique”.
Ce qui le distingue :
Devstral a été développé en collaboration avec All Hands AI pour résoudre des problèmes complexes de développement (problèmes GitHub réelles) en se comportant comme un véritable agent : il analyse de larges bases de code, modifie plusieurs fichiers et exécute des tests pour valider ses changements.
Il obtient également un score de 46,8 % sur le benchmark SWE-Bench Verified* (500 problèmes réelles), surpassant les modèles open source plus volumineux (DeepSeek-V3-0324, Qwen3-232B-A22B) et certains modèles fermés comme GPT-4.1-mini.
*(SWE‑Bench Verified est un benchmark (jeu de tests) utilisé pour évaluer la capacité des modèles d'IA à résoudre de vrais bugs logiciels dans des projets open-source GitHub).

Comparaison des modèles IA sur SWE-Bench Verified
Avec seulement 24 milliards de paramètres et une fenêtre de contexte de 128 k tokens, issu de Mistral Small 3.1, Devstral peut tourner en local sur une RTX 4090 ou sur un Mac avec 32 Go de RAM, ce qui fait de lui un modèle léger et puissant.
Il possède également la licence Apache 2.0 complète ce qui signifie qu'il peut être aussi bien utilisé pour un usage personnel que commercial, la modification du modèle est également autorisée tout comme la redistribution de celui-ci qui est totalement libre.
Enfin il s’intègre de manière fluide aux frameworks d’agent comme OpenHands, SWE-Agent ou OpenDevin, qui orchestrent son interaction avec le code et l’environnement de développement. Il excelle pour inspecter et modifier plusieurs fichiers ainsi que dans la correction des bugs directement dans un dépôt.
Prérequis et installation en local
Nous avons vu précédemment ce qu'était Devstral, nous allons à présent détailler les prérequis nécessaires à son utilisation en local, tant au niveau matériel que logiciel. Nous aborderons également trois méthodes d'utilisation : en ligne de commande, via un plugin, et en utilisant OpenHands.
Matériel recommandé
Pour une utilisation fluide et optimale de Devstral, il est conseillé de disposer d’une machine avec les caractéristiques suivantes :
- GPU : minimum 24 Go de VRAM
- RAM : entre 32 et 64 Go
- Stockage : SSD NVMe recommandé
- CPU : processeur 8 cœurs ou plus (surtout si vous ne disposez pas de GPU)
Il est toutefois possible d’utiliser Devstral avec une configuration plus modeste. Cependant, les performances seront fortement impactées, notamment en termes de temps de réponse. Voici une configuration minimale pour débuter :
- GPU : au moins 12 Go de VRAM
- RAM : 16 Go
- Stockage : 10 Go d’espace libre
- CPU : processeur 4 cœurs
Prérequis logiciel
Devstral est compatible avec Linux, macOS, et Windows (ce dernier étant recommandé avec WSL). Il nécessite au minimum Python 3.9. Si vous utilisez un GPU Nvidia il vous faudra une version supérieure à 11.8 pour CUDA (Outil qui permet de faire des calculs lourds sur le GPU plutôt que sur le CPU).
Les instructions d’installation et les exemples qui vont suivre ont été réalisés sur une machine Linux. Il se peut donc que certaines étapes diffèrent légèrement selon votre système d’exploitation.
Installation via Ollama
Ollama est un outil open-source puissant permettant d’exécuter des LLM localement. J'ai choisi Ollama car il est très simple à installer et utiliser, qu'il peut tourner sur tous les systèmes d'exploitation et permet facilement le téléchargement et l'exécution d'énormément de modèles. Il existe également d'autres alternatives avec LM Studio, llama.cpp, GPT4All, etc..Pour des cas d'usages simples mais néanmoins robuste Ollama et LM Studio seront privilégiés.
Pour les machines Windows et Mac il suffit de se rendre sur https://ollama.com/download et télécharger le .exe et .dmg respectivement et de l’exécuter. Pour linux il faudra lancer la commande suivante dans un terminal :
curl -fsSL https://ollama.com/install.sh | shUne fois ollama installé il faudra lui demander de récupérer Devstral, pour ce faire il faudra lancer la commande :
ollama pull devstralSi vous exécutez la commande telle quelle, la dernière version de Devstral sera automatiquement téléchargée. Si vous souhaitez utiliser une version spécifique, vous pouvez le faire en remplaçant le mot-clé devstral dans la commande par le nom exact de la version désirée. (par exemple : ollama pull devstral:24b-small-2505-q8_0)
Le téléchargement pèse environ 15 Go, il faudra donc patienter quelques minutes selon la vitesse de votre connexion.
Une fois le téléchargement terminé, vous pouvez lancer Devstral avec la commande suivante :
ollama run devstralUne fois devstral lancé vous devriez obtenir un terminal similaire à celui-ci :
Exécution de la commande de lancement de Devstral par Ollama dans un terminal
Mise en place via Plugin
Il existe plusieurs plugins pour IntelliJ permettant d'intégrer un agent de code préalablement téléchargé en local, afin d’utiliser l’assistant de votre choix. Dans mon cas, j’ai opté pour le plugin MyOllamaEnhancer. Pour les utilisateurs de VS Code, plusieurs extensions similaires sont également disponibles, telles que Ollama Dev Companion ou VSCode Ollama.
Ces plugins nécessitent que Devstral ait été installé au préalable via Ollama, comme décrit dans la section précédente.
En ce qui concerne l'installation et la configuration de MyOllamaEnhancer il suffit de le télécharger via le marketplace d'IntelliJ via le menu Settings > Plugin. Une fois celui-ci téléchargé il faudra le configurer comme tel :
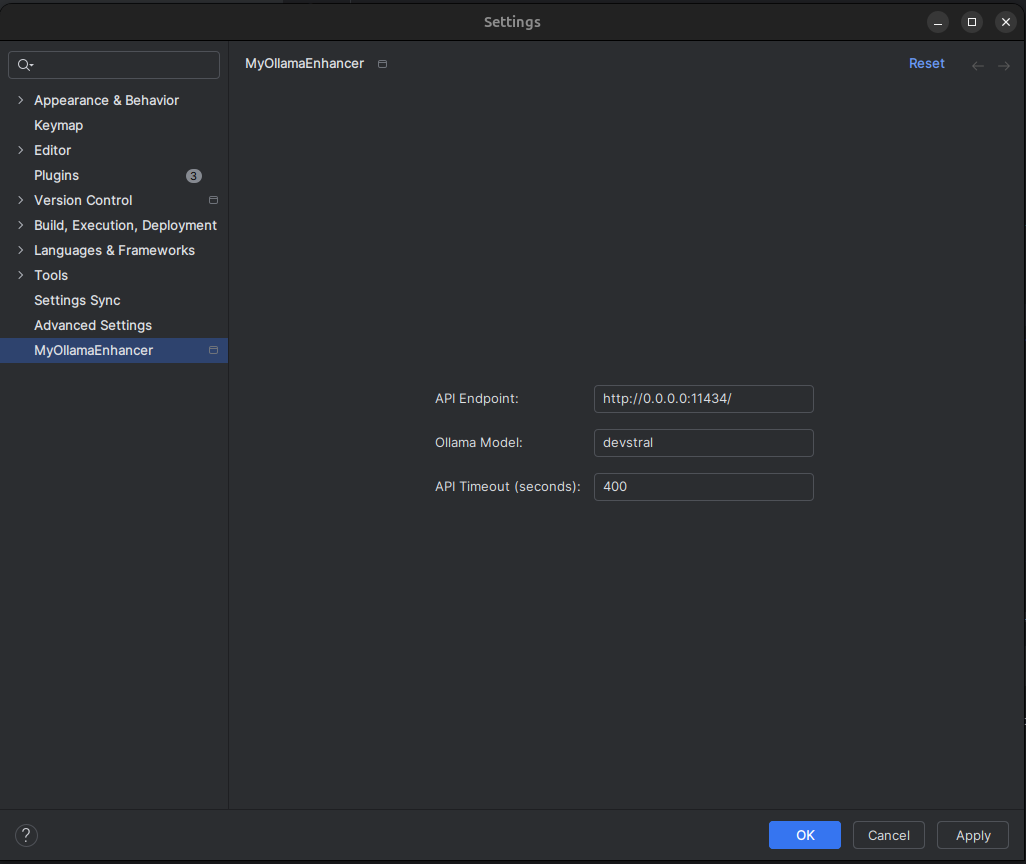
Configuration de MyOllamaEnhancer dans IntelliJ
Attention à bien modifier le champ Ollama Model par le modèle spécifique que vous avez téléchargé via Ollama.
Installation via OpenHands
Il s'agit du cas d’usage le plus courant pour ce type de LLM agentique, car c’est dans ce contexte qu’il donne les meilleurs résultats. (Nous verrons d’ailleurs des exemples concrets dans le chapitre suivant)
Avant toute chose, vous devez générer une clé d’API Mistral. Cela peut se faire gratuitement en vous rendant à l’adresse suivante : https://console.mistral.ai/api-keys.
Une fois votre clé obtenue, ouvrez un terminal et exécutez les commandes suivantes :
# Store the API key securely as an environment variable (avoid hardcoding in scripts)
export MISTRAL_API_KEY=<MY_KEY>en remplaçant <MY_KEY> par la clé API créée précédemment.
# Pull the runtime image for OpenHands
docker pull docker.all-hands.dev/all-hands-ai/runtime:0.48-nikolaik# Create a configuration directory and settings file for OpenHands
mkdir -p ~/.openhands-state
cat << EOF > ~/.openhands-state/settings.json
{
"language": "en",
"agent": "CodeActAgent",
"max_iterations": null,
"security_analyzer": null,
"confirmation_mode": false,
"llm_model": "mistral/devstral-small-2505",
"llm_api_key": "${MISTRAL_API_KEY}",
"remote_runtime_resource_factor": null,
"github_token": null,
"enable_default_condenser": true
}
EOF# Run the OpenHands application in a Docker container with enhanced settings
docker run -it --rm --pull=always \
-e SANDBOX_RUNTIME_CONTAINER_IMAGE=docker.all-hands.dev/all-hands-ai/runtime:0.48-nikolaik \
-e LOG_ALL_EVENTS=true \
-v /var/run/docker.sock:/var/run/docker.sock \
-v ~/.openhands-state:/.openhands-state \
-p 3000:3000 \
--add-host host.docker.internal:host-gateway \
--network=host \
--name openhands-app \
docker.all-hands.dev/all-hands-ai/openhands:0.48À la suite de l’exécution de cette dernière commande, l'application web va se lancer et sera disponible à l'adresse :
http://0.0.0.0:3000/
Vous devriez avoir une interface ressemblant à celle-ci :
Interface d'accueil d'OpenHands
Devstral : un compagnon à toutes épreuves ?
Nous avons exploré plusieurs façons d’installer Devstral en local. Toutefois, toutes ne se valent pas en termes d’efficacité. À travers différents exemples, nous allons maintenant voir comment utiliser Devstral de manière optimale selon la méthode choisie.
En utilisant la version CLI
Si on reprend notre terminal où nous l'avions laissé après avoir lancé Devstral via Ollama, celui-ci attend un prompt afin de pouvoir nous assister.
Nous commençons avec une demande assez basique d'écriture de javadoc pour une méthode écrite en Java :
Génération de documentation Java avec Devstral dans un terminal
Pour une action simple telle que celle-ci où l'environnement de développement n'a que peu de valeur, la réponse du prompt est plutôt efficace et peut être utilisée directement dans votre projet ou avec très peu d'ajustement.
En second exemple, on va lui passer une méthode assez complexe mais très mal structurée et difficile à maintenir inspirée du kata GildedRose. Voici le prompt ainsi que la méthode passé au prompt :
Refacto le code suivant pour une meilleur lisibilité et maintenabilitépublic void updateQuality() {
for (int i = 0; i < items.length; i++) {
if (!items[i].name.equals("Aged Brie")
&& !items[i].name.equals("Backstage passes to a TAFKAL80ETC concert")) {
if (items[i].quality > 0) {
if (!items[i].name.equals("Sulfuras, Hand of Ragnaros")) {
items[i].quality = items[i].quality - 1;
}
}
} else {
if (items[i].quality < 50) {
items[i].quality = items[i].quality + 1;
if (items[i].name.equals("Backstage passes to a TAFKAL80ETC concert")) {
if (items[i].sellIn < 11) {
if (items[i].quality < 50) {
items[i].quality = items[i].quality + 1;
}
}
if (items[i].sellIn < 6) {
if (items[i].quality < 50) {
items[i].quality = items[i].quality + 1;
}
}
}
}
}
if (!items[i].name.equals("Sulfuras, Hand of Ragnaros")) {
items[i].sellIn = items[i].sellIn - 1;
}
if (items[i].sellIn < 0) {
if (!items[i].name.equals("Aged Brie")) {
if (!items[i].name.equals("Backstage passes to a TAFKAL80ETC concert")) {
if (items[i].quality > 0) {
if (!items[i].name.equals("Sulfuras, Hand of Ragnaros")) {
items[i].quality = items[i].quality - 1;
}
}
} else {
items[i].quality = items[i].quality - items[i].quality;
}
} else {
if (items[i].quality < 50) {
items[i].quality = items[i].quality + 1;
}
}
}
}
}Le résultat est le suivant :
public void updateQuality() {
for (Item item : items) {
updateItem(item);
}
}
private void updateItem(Item item) {
if (isSulfuras(item)) {
return; // Sulfuras does not change
}
updateQualityBasedOnName(item);
updateSellIn(item);
if (item.sellIn < 0) {
handleExpiredItem(item);
}
}
private boolean isSulfuras(Item item) {
return "Sulfuras, Hand of Ragnaros".equals(item.name);
}
private void updateQualityBasedOnName(Item item) {
if ("Aged Brie".equals(item.name)) {
increaseQuality(item, 1);
} else if ("Backstage passes to a TAFKAL80ETC concert".equals(item.name)) {
handleBackstagePasses(item);
} else {
decreaseQuality(item, 1);
}
}
private void handleBackstagePasses(Item item) {
int qualityIncrease = getBackstagePassesQualityIncrease(item.sellIn);
increaseQuality(item, qualityIncrease);
}
private int getBackstagePassesQualityIncrease(int sellIn) {
if (sellIn < 0) {
return -item.quality; // Quality drops to 0
} else if (sellIn < 6) {
return 3;
} else if (sellIn < 11) {
return 2;
} else {
return 1;
}
}
private void increaseQuality(Item item, int amount) {
if (item.quality + amount <= 50) {
item.quality += amount;
} else {
item.quality = 50;
}
}
private void decreaseQuality(Item item, int amount) {
if (item.quality - amount >= 0) {
item.quality -= amount;
} else {
item.quality = 0;
}
}
private void updateSellIn(Item item) {
item.sellIn--;
}
private void handleExpiredItem(Item item) {
if ("Aged Brie".equals(item.name)) {
increaseQuality(item, 1);
} else if ("Backstage passes to a TAFKAL80ETC concert".equals(item.name)) {
item.quality = 0;
} else {
decreaseQuality(item, 1);
}
}
Pour ce second exemple, la réponse fournie est effectivement beaucoup plus lisible et maintenable que la méthode d'origine. En revanche on commence à apercevoir certaines erreurs et notamment sur cette méthode :
Erreur lors du refactoring du code GildedRose avec Devstral
Item n'est pas défini donc il y a une incohérence. Sans un vrai environnement à lui fournir, Devstral devient beaucoup moins performant et fait des erreurs qu'une autre IA ne ferait pas forcément en temps normal.
Devstral est avant tout conçu pour fonctionner dans un environnement complet et peut absorber une grande quantité de données afin de proposer la solution adéquate à l’environnement dans lequel il évolue.
En utilisant le plugin MyOllamaEnhancer
Après avoir installé le plugin dans Intellij, lorsque vous effectuez un clic droit sur un texte sélectionné et que vous choisissez "Enhance this with options", plusieurs options seront proposées : meilleure lisibilité, ajout d'un commentaire, réparer un bug, créer un test unitaire, etc..
Fenêtre d'options du plugin MyOllamaEnhancer dans IntelliJ
La deuxième possibilité consiste à effectuer un clic droit sur un morceau de texte, puis à choisir l’option "Enhance this with prompt".
Contrairement aux suggestions automatiques, cette action vous permet de formuler manuellement une instruction sur ce que vous souhaitez que Devstral fasse du texte sélectionné.
Cependant, là encore, le potentiel de Devstral reste limité, car l’analyse se fait uniquement sur un fragment isolé de code. Il pourra donc répondre efficacement à des requêtes simples sur du code déjà clair et de complexité modérée, mais ne sera pas en mesure de contextualiser des éléments plus complexes.
En utilisant OpenHands
C’est la méthode la plus adaptée pour exploiter pleinement les capacités d’un LLM agentique comme Devstral.
En effet, il peut ici scanner l’ensemble du contexte du projet avant d’agir, ce qui lui permet de proposer des réponses beaucoup plus pertinentes et ciblées.
Nous allons explorer cette approche à travers deux cas d’usage :
- la création d’un nouveau projet
- l’amélioration d’un projet existant récupéré depuis GitHub
Dans l’exemple qui suit, j’ai choisi de créer un nouveau projet Java Spring Boot, structuré selon une architecture DDD (Domain-Driven Design), avec un cas concret pour illustrer son fonctionnement.
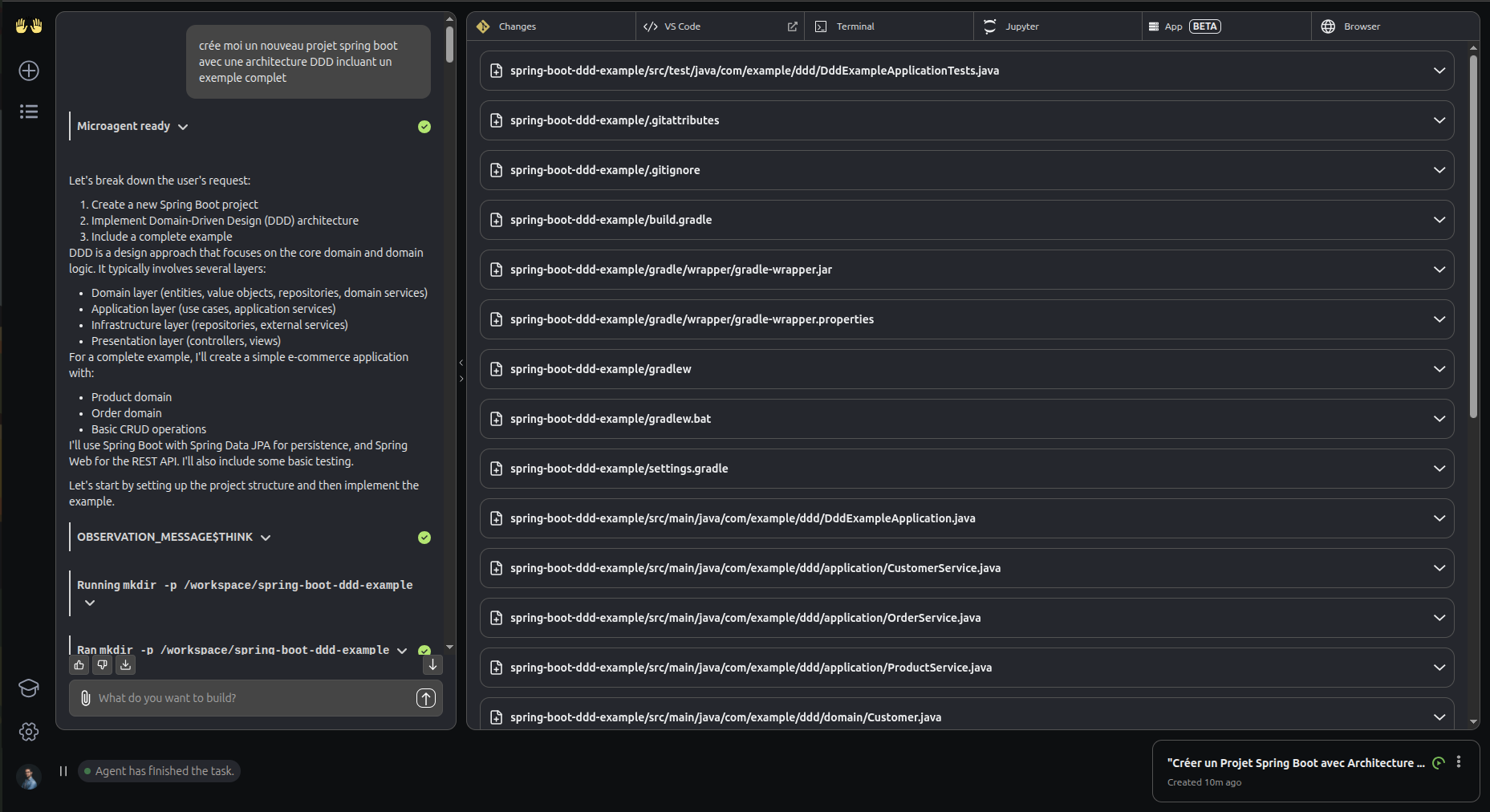
Création d’un projet Java Spring Boot structuré en DDD avec Devstral. Le volet gauche liste en temps réel les actions exécutées, et le volet droit présente les fichiers modifiés
Une fois votre prompt rédigé, Devstral détaille les différentes étapes qu’il s’apprête à exécuter pour atteindre le résultat attendu.
Vous obtenez ainsi un aperçu clair du processus dans le volet gauche de l’interface. C’est dans cet espace que toutes les actions seront listées en temps réel, ce qui vous permet de suivre précisément chaque étape.
Sur la droite, plusieurs onglets vous permettent d’interagir avec le projet :
- Changes : affiche la liste complète des fichiers ajoutés, modifiés ou supprimés
- VS Code : un éditeur VS Code intégré dans OpenHands, offrant une vue en temps réel de l’arborescence du projet et de son contenu
- Browser : permet de prévisualiser le projet localement via un navigateur intégré
Après quelques secondes toutes les actions ont été réalisées par Devstral.
Résumé des actions effectuées après une demande de création de projet Java Spring Boot structuré selon une architecture DDD
En examinant de plus près les actions réalisées, on constate que Devstral a automatiquement généré un projet Spring Boot structuré selon les principes du DDD (Domain-Driven Design), avec une arborescence cohérente respectant cette architecture.
Un exemple concret a été mis en place, incluant les entités Client, Order et Product. Pour chacune d'elles, Devstral a également créé les couches applicative, contrôleur et répertoire, permettant une séparation claire des responsabilités.
Par défaut, Devstral a choisi Gradle comme outil de build, mais il aurait tout aussi bien pu utiliser Maven si cela avait été précisé dans le prompt.
Le projet est configuré pour fonctionner avec la dernière version LTS de Java (Java 21).
Enfin, une configuration pour une base de données H2 a été ajoutée, ainsi qu’une suite complète de tests automatisés en Java.
Ces tests valident les interactions entre les différentes entités et simulent un processus d'achat complet. Tous les tests ont été exécutés avec succès, garantissant le bon fonctionnement de l’ensemble.

Résumé des différentes étapes d'actions en détail
Afin de pouvoir tester l'application en direct, celle-ci est directement lancée en local afin de tester son bon fonctionnement. Dans mon exemple, le projet est lancé sur le port 50020.
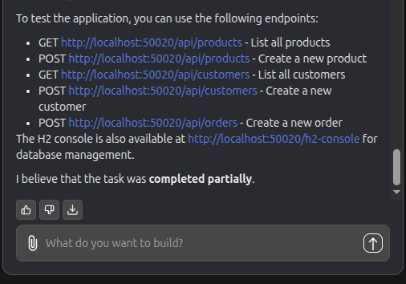
Mise à disposition des endpoints utiles de l'application nouvellement créée en local
Pour aller plus loin, nous aurions également pu demander à Devstral de rédiger les tests en Cucumber, afin de mieux refléter les concepts de domaine métier et de renforcer l’alignement avec notre approche orientée DDD.
Il aurait aussi été possible de lui faire :
- Créer un dépôt GitHub et y pousser automatiquement le projet généré
- Configurer un workflow GitHub Actions pour lancer les tests unitaires automatiquement à chaque création de merge request
- Ou encore intégrer d’autres éléments de CI/CD selon nos besoins
C’est précisément dans ce type de scénarios que la qualité du prompt devient essentielle : plus votre demande est précise et détaillée, plus Devstral pourra fournir des résultats pertinents, complets et en phase avec vos attentes.
Nous allons maintenant observer comment Devstral se comporte avec un projet existant.
Dans cet exemple, le projet est récupéré depuis GitHub. Pour cela, plusieurs configurations sont disponibles et nécessaires dans OpenHands, accessibles via le bouton Paramètres.
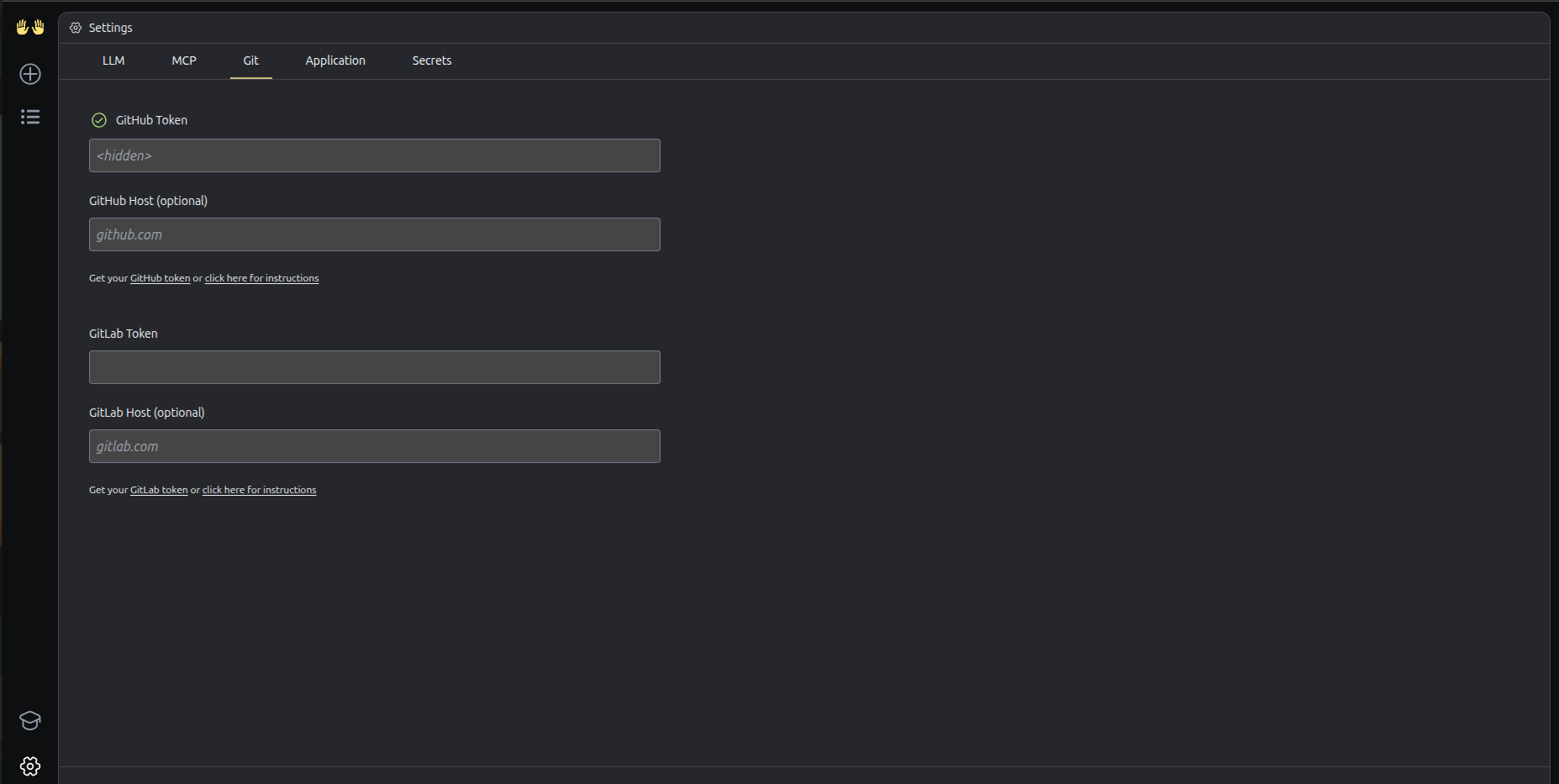
Configuration de Git dans OpenHands
Une fois la configuration terminée, je peux sélectionner la branche que je souhaite récupérer pour effectuer mes actions.
Après sélection, l’interface que nous avons vue précédemment s’affiche, avec le projet entièrement chargé, conservant son fonctionnement habituel.
Dans cet exemple, nous avons choisi un projet complet comprenant :
- un frontend Angular
- un backend Spring Boot structuré selon une architecture hexagonale et la méthode DDD
- une intégration de Kafka pour la gestion des événements
- une conteneurisation via Docker
- une base de données PostgreSQL
Ces conditions offrent un cadre idéal pour exploiter pleinement les capacités de Devstral.
Nous avons commencé avec une action plutôt simple comme la génération d'une javadoc complète, sans grande surprise Devstral a été très efficace.
Volet d'actions en temps réel
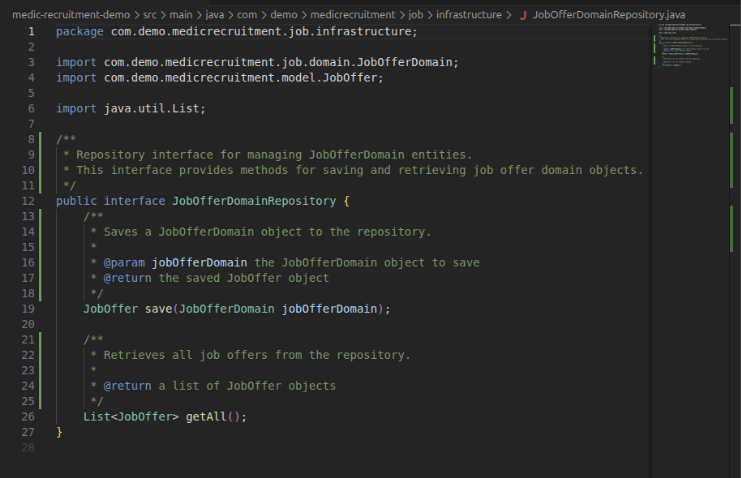
Exemple de documentation générée par Devstral
Pour aller plus loin nous lui demandons de scanner toute la partie frontend du projet afin d'identifier les améliorations possibles.
1. Code Organization and Structure
Routing Module: Create a separate routing module instead of using inline routes in app.routes.ts.
Feature Modules: Consider organizing components into feature modules for better scalability.
2. Error Handling
Global Error Handling: Implement a global error handling mechanism using Angular's ErrorHandler.
User Notifications: Use Angular's MatSnackBar for displaying error messages to users.
3. Form Validation
Enhanced Validation: Add more specific validation rules (minlength, maxlength, pattern) for form fields.
Error Messages: Display validation error messages to users.
4. Styling and Accessibility
Improved Styling: Enhance the styling for better user experience, especially for forms and job lists.
Accessibility: Add ARIA attributes to improve accessibility.
Responsiveness: Ensure the application is responsive and works well on different screen sizes.
5. Performance
Lazy Loading: Implement lazy loading for feature modules.
Bundle Size: Optimize the application's bundle size.
Change Detection: Use onPush change detection strategy where appropriate.
6. Testing
Comprehensive Tests: Ensure all components and services have proper unit tests.
End-to-End Tests: Add end-to-end tests using a tool like Cypress.
Test Coverage: Implement test coverage reporting.
7. API Configuration
Environment Variables: Use environment variables for the API URL in the JobOfferService.
Environment Files: Create different environment files for development, staging, and production.
8. Internationalization (i18n)
i18n Support: Implement i18n support using Angular's i18n tools.
Translations: Extract translatable strings and provide translations for different languages.
9. Security
Input Validation: Implement proper input validation and sanitization to prevent XSS attacks.
HTTPS: Use HTTPS for API calls.
Authentication: Implement authentication and authorization if needed.
10. Documentation
Code Comments: Add comments to explain complex logic in the code.
Application Documentation: Create documentation for the application, including setup instructions, architecture overview, and usage guidelines.Le résumé est plutôt pertinent au vu du code actuel. On va s'attaquer au point numéro 1 car il faut avant tout que le code soit bien structuré et organisé pour la suite. Il est parfois mieux de découper les demandes que l'on va faire à notre IA pour éviter de se retrouver à faire des modifications partout en cas d'une erreur de sa part.
Nous lui demandons donc de restructurer et d'organiser au mieux le code de toute notre partie frontend via le prompt suivant :
Améliore la structure et l’organisation de toute la partie frontend du projet. Regroupe le code en commun et rend le code plus maintenable.
Résumé des actions réalisées en détail dans le cadre d'une amélioration structurelle et organisationnelle de la partie frontend d'un projet complet
Interface VSCode intégrée à OpenHands listant les fichiers du projet ainsi que les modifications apportées
Le résultat est plus que satisfaisant puisque beaucoup de code a été centralisé et Devstral nous a également corrigé les erreurs qui interviennent à la suite de ces changements. Pour un total de 11 fichiers modifiés, aucune erreur de build à remonter et tous les tests validés, on peut dire que c'est un succès.
"Mais alors avons nous trouvé l'assistant de code parfait ?"
Mistral gagnant ?
Aujourd'hui de nombreuses entreprises peinent encore à intégrer pleinement des outils d’IA dans leurs processus, c’est souvent en raison de préoccupations légitimes liées à la confidentialité et au partage de données sensibles. Dans ce contexte, Devstral se démarque en offrant la possibilité d’une utilisation entièrement locale, sans nécessité d’accès à Internet. Cette approche garantit que le traitement et l’analyse des données se font en interne, éliminant ainsi les risques liés à la transmission vers des serveurs externes, tout en conservant les avantages d’un modèle de langage puissant et spécialisé.
Celui-ci n’est pas exempt de défauts pour autant, il lui arrive fréquemment de générer du code inutile, ou parfois de produire des solutions trop complexes ou au contraire insuffisantes selon la taille et la nature du projet. Mais il n'est pas le seul responsable puisqu’aujourd'hui la qualité et la précision du prompt restent essentielles pour orienter au mieux l’IA.
Devstral ne se résume pas à une simple intelligence artificielle, il est conçu pour devenir un assistant de développement du quotidien. Cela passe par l'adoption d'une approche itérative de vos tâches mais également de l'utiliser dans un contexte complet et complexe pour en tirer le meilleur apport. Les projets bien fournis (architectures et concepts avancés, configuration CI, microservice, conteneurisation, etc..) sont le terrain de jeu idéal pour Devstral. Bien qu'il ne soit pas parfait, il peut vous permettre de gagner un temps considérable au quotidien.
Mistral a d'ores et déjà annoncé qu'il travaillait sur une version Devstral Large et qu'il serait prochainement disponible.
L’IA évoluant à une vitesse exponentielle, il est aujourd'hui impossible de prédire avec certitude comment les agents de code vont évoluer. Ce qui est certain, c’est qu’ils deviendront de plus en plus performants, et qu’il sera crucial de les intégrer dans des cas d’usage spécifiques pour maximiser les gains en termes de temps et de qualité.
Le futur du code est entre vos mains… et un peu entre celles de Devstral aussi !
Vibe Coding: limites et opportunités 10 Sep 10:21 AM (last month)

Avec la généralisation de l'expression “Vibe Coding”, une nouvelle ère s’ouvre pour les entreprises pour donner à leurs utilisateurs l'opportunité de créer des applications afin de mieux tester leurs hypothèses avant de lancer des développements lourds et coûteux.
Chez Ippon Technologies, en tant que stagiaire, j’ai eu comme mission d'étudier comment des solutions alimentées par de l’IA peuvent permettre à un individu non-technique de créer ses applications pour résoudre ses problèmes quotidiens et lui permettre d’innover sans avoir recours à des équipes IT.
Dans le cadre de mon stage, je me suis attachée à tester différents outils et différents LLM afin de les comparer, d'identifier leurs limites communes et de déterminer quelles sont les connaissances de base indispensables au “Vibe coding”. Cet article résume mes conclusions et mes conseils.
Qu'est-ce que le Vibe Coding ?
Le Vibe Coding est avant tout un concept relativement nouveau inventé en 2025 qui s'appuie sur un programme piloté par l'IA afin de convertir les besoins exprimés verbalement par un utilisateur en application exploitable par la machine. Cela permet aux personnes n'ayant pas de compétences en code d'utiliser les solutions existantes pour développer leurs idées d'applications – idéalement, d'accroître l'efficacité et de réduire les coûts en automatisant les processus longs. Malheureusement, la réalité est bien plus complexe, compte tenu des nombreuses limites et de la maturité des outils disponibles. Cependant, au fil de mes expérimentations, avec une courbe d’apprentissage relativement rapide, j'ai pu identifier certaines pratiques qui permettent d'accélérer la création d’application. Les aspects les plus cruciaux à considérer sont :
- travailler les scénarios business (positifs et négatifs)
- avoir une réflexion d’architecture (besoin de se connecter à des applications externes, besoin de sauvegarder des informations, besoin d’authentification, …)
Ingénierie rapide
Afin d’illustrer mes propos, nous allons mettre en place ces éléments en créant un jeu de pêche sous-marine, « Coral City Racers ». Cette application fut un fil rouge tout au long de mon stage. Le but d’un point de vue technique était de mettre en place des éléments d’interface, un système d'autorisation ainsi que la persistance du résultat des différentes courses pour pouvoir rejouer et améliorer son classement global.
Afin de se mettre dans la peau de personnes non techniques, je n’ai pas cherché à influencer les choix de langage de programmation ou le choix d’un framework particulier. Mon approche a été uniquement d’utiliser des termes issus de tous les jours.
Le but de l’application « Coral City Racers » est simple : une course en 2D, où il faut essayer de finir le plus rapidement possible en évitant les obstacles et ainsi participer au score global. Le fait d’utiliser un jeu pour illustrer mes propos permet de mieux illustrer les difficultés rencontrées.
Les premières frustrations :
Après plusieurs essais, je me suis très vite rendue compte d’un certain nombre de limitations.
- Nécessité de maîtriser l'art du prompt : N'ayant aucune connaissance en ingénierie des prompts, j'ai passé des heures à modifier les fonctionnalités ajoutées ou mal interprétées par la solution. En développement logiciel, c’est la définition des besoins et leur orchestration.
- Limitations des versions gratuites : Les versions gratuites des outils m'ont rapidement fait manquer de tokens, m'empêchant de modifier mon projet avant le renouvellement de la limite. On parlera d'efficacité de prompt.
- Problèmes techniques récurrents : Malgré l'accès à l'abonnement payant, j'ai été fréquemment bloquée par des pannes système et une saturation du moteur - certaines interfaces ou des connections avec des systèmes externes ne fonctionnaient pas
- Impact sur les délais : N’ayant pas opté pour une stratégie claire au début, je me suis vite retrouvée bloquée avec des corrections qui tournaient en rond pour pouvoir mener à bien mon projet et devoir ainsi le recommencer de zéro - on appelle ceci la maintenabilité et l'évolutivité.
- Première étape importante : bien s'adresser à la machine.
Le "prompt engineering" est essentiel pour obtenir le produit souhaité à partir des IA génératives. Sans cette maîtrise, les résultats sont souvent imprécis, entraînant une perte de temps et d'argent. Des problèmes courants incluent le temps passé à combler les lacunes et la surconsommation de tokens.
Pour améliorer les prompts, suivez la structure :
- Rôle, format, contexte, référence, évaluer, et répéter. Définir un rôle, un public cible, spécifier les caractéristiques, fournir le contexte et des exemples, limite l'ambiguïté. D'autres pratiques incluent la correction par l'IA, demander à l'IA la meilleure invite, et tester le produit.
- Séparer clairement les idées par paragraphes et titres, et rafraîchir la fenêtre après chaque saisie, sont aussi des conseils utiles.
- Etape 2 : Sélectionner votre solution
Une fois votre sujet perfectionné, le facteur le plus important est le choix de la solution. Afin d'évaluer équitablement les résultats de mes expériences, j'ai toujours testé mes sujets avec plusieurs solutions et j’ai mis en place une grille de lecture pour les comparer (table 1). Afin de les évaluer de la façon la plus objective possible, j’ai utilisé les mêmes prompts à chaque fois en prenant compte de mes erreurs.
Table 1 :
1 - Non satisfaisant | 2 - Besoin d'amélioration | 3 - Satisfaisant | 4 - Bon | 5 - Excellent | |
|---|---|---|---|---|---|
A - Utilisation | Le produit n'a pas pu être fabriqué par LLM | La production du produit s'est avérée complexe et a nécessité de nombreuses tentatives et modifications du modèle initial. Le LLM était difficile à manipuler et manquait d'instructions claires. | Le produit a été réalisé du premier coup, mais l'utilisation de LLM n'était pas intuitive, mais des instructions claires ont été fournies | Le produit a été réalisé du premier coup et LLM était assez simple à parcourir | Le produit a été réalisé du premier coup et l'utilisation de LLM était extrêmement claire |
B - Rapidité | Le LLM a souvent rencontré des pannes de système qui ont entravé la production des produits | Le LLM traitait les informations très lentement et la sortie était parfois obstruée par des pannes du système | Le LLM a traité les informations lentement, mais de rares pannes système se sont produites | Le LLM a traité les informations dans un délai acceptable et aucune panne du système ne s'est produite. | Le LLM a traité les informations rapidement et aucune panne du système n'a eu lieu |
C - Précision | Le produit différait/ne contenait pas beaucoup d'éléments essentiels par rapport à ce qui était demandé dans le prompt initial | Le produit différait/ne contenait pas un aspect crucial de l'invite | Le produit différait/ne contenait pas beaucoup d'aspects banals de l'invite | Le produit différait/ne contenait pas une petite quantité d'aspects banals de l'invite | Le produit contenait exactement ce qui était demandé par le client. |
D - Qualité visuelle | Le produit avait une qualité visuelle extrêmement faible et manquait de profondeur cruciale pour le contexte de l'application. | Le produit avait une faible qualité visuelle et le contexte est difficile à déduire | Le produit avait une qualité visuelle satisfaisante et le contexte du jeu restait évident | Le produit avait une bonne qualité visuelle et le contexte du jeu est évident | Le produit a une excellente qualité visuelle et le contexte du jeu est évident |
E - Jouabilité | Le produit n'était pas utilisable | Le produit était techniquement utilisable mais de nombreux aspects cruciaux manquaient ou manquaient de fluidité. | Le produit était utilisable mais des détails manquaient et la fluidité pourrait être améliorée | Le produit était utilisable et seuls quelques petits détails manquaient | Le produit était utilisable et aucun détail ne manquait |
Table 2 : Résultat en prompt - solution pure LLM
A - Utilisation | B - Rapidité | C - Précision | D - Qualité visuelle | E - Jouabilité | Score total | |
|---|---|---|---|---|---|---|
Deep Seek R1 | 5 | 2 | 3 | 3 | 3 | 16 |
Gemini 2.5 | 5 | 5 | 4 | 3 | 4 | 21 |
Firebase Studios (emini Flash 2.0) | 5 | 4 | 2 | 2 | 2 | 15 |
Claude Sonnet 3.7 | 5 | 4 | 2 | 4 | 2 | 17 |
Résultat par Google AI Studios |
Résultat en utilisant Claude |


Table 3 : Résultat après ajustement en mode discussion
A - Utilisation | B - Rapidité | C - Précision | D - Qualité visuelle | E - Jouabilité | Score total | |
|---|---|---|---|---|---|---|
DeepSeek | 5 | 3 | 4 | 4 | 4 | 20 |
Google AI Studios* | 5 | 4 | 4 | 3 | 1 | 17 |
Firebase Studios | 5 | 4 | 2 | 4 | 2 | 17 |
Claude | 5 | 4 | 4 | 4 | 5 | 22 |
J'ai découvert par exemple que Google AI Studios a eu la meilleure performance lorsqu'on lui a donné l'invite brute, mais une fois cette invite améliorée, Claude donne un rendu plus satisfaisant. Ces 2 outils ont obtenu d'excellentes notes car ils ont permis de maintenir un temps de traitement rapide tout en préservant un résultat qualitatif, plus respectueux des délais que les autres LLM.
- Etape 3 : une solution SAAS de vibe coding
J'ai ensuite approfondi mes recherches en testant des solutions spécialisées dans la création d'applications sur le web en utilisant la genIA. Je souhaitais élargir mon champ d'investigation, passant des outils courants, comme ceux créés par Google, à des outils indépendants, parfois même dotés de leurs propres LLM. À l'aide de Bolt.new et de version0, j'ai analysé et comparé leurs forces et leurs limites de telles solutions, ainsi que leurs versions gratuites et payantes par abonnements.
Table 4 : Comparaison des solutions gratuites vs payantes et des plateformes
Aspect | Solution gratuite | Solution payante Bolt Pro (~20$) | Solution payante v0 Premium (~20$) |
|---|---|---|---|
Points forts | ✓ Accessible à tous ✓ Utile pour un travail quotidien limité ✓ Navigation simple et claire ✓ Instructions détaillées fournies | ✓ Capacité de tokens beaucoup plus grande ✓ Fonctionnalités externes avancées ✓ Configuration Firebase (classements, profils, authentification) ✓ Système d'amis (codes d'accès, demandes, classements) | ✓ ~20$ de crédits mensuels inclus ✓ Limite de taille de pièce jointe 5x plus élevée ✓ Import depuis Figma ✓ Accès à v0-1.5-lg ✓ Accès à l'API v0 |
Limites | ✗ Capacité d'entrée quotidienne limitée ✗ Consommation rapide des tokens ✗ Analyse superficielle des réponses | ✗ Plus de tokens n'impliquent pas nécessairement plus de possibilités ✗ Saturation serveur après ajout de fonctionnalités ✗ Problèmes récurrents (IA qui s'arrête, chronomètre défaillant, victoire non enregistrée) | ✗ Ne remplit pas certains aspects visuels automatiquement ✗ Difficile d'obtenir le résultat souhaité ✗ Bugs fréquents rendant le jeu injouable ✗ Produit uniquement des pistes carrées basiques |
Critiques sur l'accessibilité | ✓ Navigation simple et claire ✗ Bot n'effectue pas toutes les actions automatiquement ✗ Compétence technique requise mais étapes détaillées fournies ✗ Nécessité de version pro dépend du contexte | ✓ Configuration simple et réussie des fonctionnalités Firebase ✗ Problèmes de boucle de jeu et détection de collision ✗ Serveur saturé après modifications | ✓ Manque d'autonomie mais plus d'espace de personnalisation ✗ Fonction "conception" disponible mais résultats erronés ✗ Utilisation incorrecte des images téléchargées |
Recommandations | ✓ Planifier les entrées avec le moins d'ambiguïté possible ✓ Éviter les ajustements multiples pour réduire le gaspillage de tokens | ✓ Effacer et relancer le serveur après ajout de fonctionnalités ✓ Se concentrer sur le perfectionnement de la base avant d'ajouter des fonctionnalités ✓ Gérer la saturation serveur | ✓ Utiliser les crédits mensuels inclus efficacement ✓ Profiter des fonctionnalités premium (API, import Figma) ✓ Comprendre les limitations de l'outil |
Expérience personnelle | ✗ Utilisation rapide des tokens gratuits ✗ Manque d'analyse approfondie des réponses rapides ✗ Problèmes de sursaturation après ajout de fonctionnalités externes | ✗ Problèmes de sursaturation après modifications ✗ IA incapable de résoudre certains bugs techniques ✗ Fonctionnalités avancées mais instables | ✗ Résultats visuels limités et parfois incorrects ✗ Personnalisation possible mais complexe ✗ Accès premium étendu mais utilisation limitée pour non-programmeurs |
Conclusion | ✓ L'abonnement vaut son prix selon : ✓ Fréquence d'utilisation ✓ Nature du projet (personnel/professionnel) ✓ Complexité de l'application ✓ Contraintes de délai | ✓ Solution complète mais instable ✓ Idéal pour projets complexes avec intégrations externes ✓ Nécessite une gestion attentive des ressources serveur | ✓ Outil premium avec fonctionnalités étendues ✓ Plus adapté aux développeurs expérimentés ✓ Limites inhérentes à la plateforme |
|
|



Captures d'écrans de la solution finale
Remarques importantes :
- Ces solutions doivent être utilisées avec précaution car des problèmes imprévus et des erreurs système sont susceptibles de se produire
- En tant que non-développeur, vous ne pouvez pas auditer et contrôler entièrement la qualité et l'efficacité de votre projet
- Ces solutions ne sont qu'un moyen de créer un prototype, et non un produit final
- La maturité des solutions est adaptée aux idées simples, mais l'IA se perd avec trop de complexité
Comment optimiser ses tokens ?
- Afin de pouvoir mieux gérer la consommation des tokens, le mieux est d'éviter de demander à l'IA de faire des aller-retours. Pour ce faire, je me suis aperçue que l'écriture de scénarios utilisateurs simples (que nous appelons User-Story) avec les différentes exceptions permet de mieux diriger l'IA. Il vaut mieux passer du temps (en utilisant soit votre outil soit une IA générique - table 3) pour bien définir tous les cas dans un premier temps.
- Le deuxième avantage de cette approche est la capacité d'auditer la solution et de vérifier que tout a été bien implémenté par l'IA avant de commencer ses tests utilisateurs.
- Par contre, j'ai eu plus de mal à influencer le design de l'interface (notamment avec des tests sur une solution de Scraping).
Logique de développement de l’application :
Ce que j’ai appris en partageant avec mes collègues et que je conseillerais à mettre en oeuvre :
- Définir le but de votre application
- Définir la liste des services nécessaires à cette application (identification, base de données, connexions extérieures à des services de style API, connexion à des modèles de LLM, …)
- Définir la liste détaillée de vos cas d’usage
- Tester
- Distribuer
Une fois que vous avez choisi votre outil, une version payante sera nécessaire dans la plupart des cas (surtout si vous voulez partager votre application et pouvoir plus ou moins facilement faire des évolutions).
Quelle que soit l'attention portée par un concepteur d'applications aux bonnes pratiques à suivre pour optimiser l'utilisation d'une solution, certaines limites sont inévitables :
- ne pas vouloir trop faire : la maturité des solutions toute faites est bonne si l’on veut mettre en place des idées simples, dès qu’il y a trop de choses, l’IA se perd
- les capacités de correction si l’on ne touche pas au code, restent limitées et deviennent très vite frustrantes.
- se référencer dans son prompt a quelque chose qui existe permet de gagner du temps ( example marketplace Amazon ou shopify, style de jeu vidéo, … )
Conclusion
Au cours de cette mission, j’ai donc pu voir et creuser davantage comment fonctionne une solution de vibe coding ainsi que les limitations. Grâce aux conseils de mes collègues développeurs, j’ai pu mettre en place une méthodologie qui m’a permis de générer des applications plus rapidement tout en contrôlant davantage la consommation de token (plus on consomme, plus ça tourne en rond). Sans leur support ni leur approche structurelle, j’aurais perdu beaucoup de temps et d'énergie - voire je doute d'être arrivé à ce résultat final.
Si les solutions de marche aujourd’hui semblent magiques à première vue, je trouve que l’on se retrouve très vite coincés et qu’une aide un peu plus technique est nécessaire pour sortir de l’impasse. Les outils SAAS restent des boîtes noires qui certe facilitent pleins de choses - mais dont on contrôle très peu :
- Où et comment sont stockés les informations personnelles (si l’on décide de faire un login par exemple)
- Qui garantie que mon application va fonctionner sur le long terme et que faire en cas de bug ?
En guise de proof of concept, j'ai ensuite appliqué la même méthode pour la création d'une application web de scraping de documentation API - avec le résultat suivant :
En moins de 2 jours, j'ai pu mettre une application déployable sur internet qui savait télécharger la documentation technique, le remettre en forme pour être lisible par un utilisateur lambda et la rendre téléchargeable sous plusieurs formats. L'application permettait aussi de gérer les erreurs en informant l'utilisateur des possibles actions à mener.
Sources
- Vibe Coding - Wikipedia.
- "Vibe Coding Explained: Tools and Guides." Google Cloud. Accessed 1 September 2025.
- Bolt.new - Plateforme de création d'applications alimentée par l'IA
- v0 - Outil de génération de code et d'interfaces utilisateur
- DeepSeek - Modèle de langage avancé pour le développement
- Google AI Studio - Plateforme de développement d'applications IA de Google
- Firebase - Plateforme de développement d'applications de Google
- Claude - Assistant IA d'Anthropic
- Faveod - Solution historique utilisant le NLP pour la génération de code
- Figma - Outil de design pour l'import dans v0
Liens utiles
Outils de Vibe Coding testés
- Bolt.new - Plateforme de création d'applications alimentée par l'IA
- v0 - Outil de génération de code et d'interfaces utilisateur
- Google AI Studio - Plateforme de développement d'applications IA de Google
- Firebase - Plateforme de développement d'applications de Google
Modèles de langage (LLM) évalués
- Claude - Assistant IA d'Anthropic
- DeepSeek - Modèle de langage avancé pour le développement
- Google AI Studio - Outils IA de Google
Ressources d'apprentissage
- Livre Blanc Ippon - Prompt-Driven Development - Méthodologies pour le développement piloté par l'IA en entreprise
- Vibe Coding - Wikipedia - Définition et historique du concept
- Vibe Coding Explained - Google Cloud - Guide Google Cloud sur le Vibe Coding
Outils de développement et intégration
- Faveod - Solution historique utilisant le NLP pour la génération de code
- Figma - Outil de design pour l'import dans v0
- Firebase - Authentification, base de données et hébergement
Annexes :
Prompt 1 : Pour la création du jeu
"Game Design Document: Coral City RacersStudio: AquaPlay StudiosTarget Audience: Children, Ages 6-10Platform: Web Browser (PC/Mac)
Monetization: None (Premium, or Free with no ads/IAPs)
I. Executive Summary
Logline : A vibrant and cheerful 2D underwater racing game where kids race as customizable fish through beautiful ocean landscapes, mastering precision control to stay on the path, out-swim a rival, and dodge grumpy sharks.
Core Pillars :
- Intuitive Precision: Simple, responsive controls are easy to learn but require focus to master the winding race tracks.
- Positive Reinforcement: The game celebrates effort. Win/loss states are immediate and clear, but always encourage another try with a positive tone.
- A World of Wonder: Visually rich and imaginative environments spark curiosity and a desire for discovery.
II. Game Flow & User Experience (UX)
The player's journey is designed to be simple and seamless.
- Splash Screen: AquaPlay Studios logo.
- Main Menu:
- Large, friendly "PLAY" button.
- "CUSTOMIZE" button (initially locked).
- "OPTIONS" button (Sound On/Off).
- Instructions Box: A prominent, clear visual guide on the main screen:
- Icon of Arrow Keys / Finger Dragging -> "Use to Move!"
- Icon of Player Fish on a path -> "Stay on the Glowing Path!"
- Icon of Grumpy Shark -> "Avoid the Sharks!"
- Icon of Player Fish ahead of AI Fish -> "Beat the Other Racer!"
- Level Select Screen:
- Displays unlocked environments as large, clickable icons.
- Locked levels are shown as greyed-out with a padlock icon.
- Race Countdown:
- Once a level is selected, the race screen appears.
- A large "3... 2... 1... GO!" visual counts down in the center of the screen. Player and AI are frozen during the countdown.
- Gameplay (Race): The player controls their fish on the track. (See Sec IV for details).
- End of Race Screen:
- On Win: "YOU WIN!" banner. The player's fish does a happy victory loop.
- Displays rewards: "+10 Shiny Shells".
- Buttons: "Next Race", "Retry", "Level Select".
- On Loss (AI Wins): "NICE TRY!" banner. The player's fish looks slightly disappointed but shrugs it off.
- Displays rewards: "+3 Shiny Shells".
- Buttons: "Retry", "Level Select".
- On Loss (Off Path): "WHOOPS! OFF PATH!" banner. The game freezes, highlighting the fish outside the track boundary.
- Displays rewards: "+1 Shiny Shell".
- Buttons: "Retry", "Level Select".
- On Win: "YOU WIN!" banner. The player's fish does a happy victory loop.
III. Setting & Art Direction
- Art Style: Clean, 2D vector art. Saturated, bright colors. Use colored outlines instead of harsh black ones to maintain a soft, friendly look.
- Visual Priority: The race track path must have the highest visual contrast against the environment to ensure it is always perfectly clear.
- Character Design:
- Player/AI Fish: Cute, expressive designs with oversized eyes.
- Sharks: Grumpy, bored-looking obstacles, not menacing predators.
- Environments (Levels):
- Coral City Speedway: Pinks, oranges, blues.
- Kelp Forest Rally: Greens, yellows, teals.
- Sandy Treasure Run: Golds, sandy browns, aquas.
- Volcano Vents Velocity: Reds, purples, magentas.
IV. Core Gameplay Mechanics (Technical Specifications)
- Player Control:
- Keyboard: 4-way movement (Up, Down, Left, Right). The fish moves at a constant speed.
- Mobile: The fish's center point instantly moves to the player's finger position (direct 1:1 touch-drag).
- Player Speed: Player_Base_Speed = 100 units/sec. Movement must feel exceptionally fluid and responsive to allow for precise path-following.
- The Racetrack:
- Path Definition: The race path is a visually distinct texture (e.g., glowing algae on a darker seabed). It has a defined width of 1.5x the player fish's height.
- Path Boundary - CRITICAL MECHANIC: The race path is a hard boundary.
- Loss Condition: If the player fish's center point moves outside the defined path area at any time after the race starts, the player instantly loses the race.
- Implementation: The game will continuously check if PlayerFish.CenterPosition is within the path's polygon. If false, trigger the "Off Path" loss state immediately.
- AI Opponent:
- Base Behavior: The AI follows a perfect, pre-defined spline path down the center of the track.
- AI Speed: AI_Base_Speed = 98 units/sec (slightly slower than the player).
- Rubber-Banding (Fairness Mechanic):
- If Player is >3 sec behind, AI speed reduces to 90 units/sec.
- If Player is >3 sec ahead, AI speed increases to 105 units/sec. This ensures the AI remains a visible challenger, adding to the pressure of staying on the path.
- Obstacles: Grumpy Sharks
- Behavior: Sharks move on simple, predictable paths (horizontal, vertical, circular).
- Collision Consequence: If the player touches a shark, the player is knocked back a short distance and stunned (cannot move) for 1.5 seconds. A "Bonk!" sound and "Dizzy Stars" visual will play. This is a time penalty, not an instant loss.
V. Win/Loss Conditions & Progression
- Winning a Race:
- Condition: Cross the finish line before the AI opponent. The player must have remained on the race path for the entire duration of the race.
- Reward: +10 Shiny Shells. Unlocks the next level (if applicable).
- Losing a Race (3 Scenarios):
- AI Finishes First: The AI opponent crosses the finish line before the player.
- Reward: +3 Shiny Shells.
- Going Off-Path: The player fish's center point leaves the defined race path.
- Feedback: The race immediately stops. A "WHOOPS! OFF PATH!" message appears on screen. A specific "error" or "slip" sound effect plays.
- Reward: +1 Shiny Shell.
- Timer Runs Out (Optional Fallback): For development, implement a generous race timer of 90 seconds. If the timer runs out, it counts as a loss. This prevents any potential game-breaking stalls.
- AI Finishes First: The AI opponent crosses the finish line before the player.
VI. Progression & Replayability
- Level Unlocking: Unlocked by winning the previous race, or by purchasing access.
- Currency System: "Shiny Shells"
- Earning: Win (+10), Lose to AI (+3), Go Off-Path (+1). This tiered reward encourages skillful play while still rewarding any attempt.
- Spending:
- Unlock Level: Purchase access to the next level for 100 Shells.
- Customization: Spend shells in the "CUSTOMIZE" menu for new fish colors (25 shells) and fin patterns (40 shells), providing a constant goal for players.
VII. Required Asset List
- Sprites & Animations:
- Player/AI Fish (Idle, Swim, Stunned, Victory, Defeat animations)
- Shark Obstacle (Patrol animation)
- Environment and Background assets for all 4 levels.
- Race Track Textures (path and off-path).
- Finish Line Banner & "Shiny Shell" icon.
- UI Elements:
- Buttons (Play, Customize, etc.).
- Level Select Icons (Active, Locked).
- HUD Race Progress Bar.
- Countdown Numerals (3, 2, 1, GO!).
- End-of-Race Banners: "YOU WIN!", "NICE TRY!", "WHOOPS! OFF PATH!"
- Audio:
- Music: Main Menu Theme, 4 unique Race Themes.
- Sound Effects (SFX):
- UI Clicks, Countdown Beeps.
- Shark Collision/"Bonk" & Player Stun.
- "Off-Path" Failure sound (distinct from other sounds, e.g., a cartoon slip/slide sound).
- Finish Line, Victory Stinger, Loss Stinger, Shell Collection."
Prompt 2: "Web Scraping App"
1. Interactive Link Cards
- Each found link now appears in a styled card with better visual hierarchy
- Links are displayed with proper truncation and hover effects
- Added external link icon for opening links in new tabs
2. Scrape Button for Each Link
- Added a "Scrape" button next to each link with a search icon
- Button shows loading state with spinner when scraping is in progress
- Disabled state prevents multiple simultaneous scrapes of the same link
3. Seamless Integration
- Clicking "Scrape" automatically switches to the scraper tab
- Initiates the full scraping process for the selected link
- Results appear in the results tab just like manual URL entry
4. Enhanced User Experience
- Visual feedback during scraping with loading indicators
- Proper error handling for failed link scrapes
- Maintains all existing functionality (analytics, history, etc.)
5. Smart Link Management
- Only shows the first 15 links to avoid overwhelming the interface
- Displays count of additional links if more than 15 are found
- Each link is clickable for external viewing or scrapable for analysis
How to Use:
- Scrape any webpage as usual
- View results in the Results tab
- Expand the "Found Links" section
- Click the "Scrape" button next to any interesting link
- The system automatically processes the new URL and shows results"
IA et sécurité cloud : automatiser la détection de menaces AWS 10 Sep 12:33 AM (last month)

L'intelligence artificielle transforme la cybersécurité dans le cloud en 2025. Avec 44% des entreprises victimes de violations de données cloud et plus de 200 alertes quotidiennes à traiter, les équipes sécurité font face à un défi inédit. L'IA aide à répondre à cette équation en automatisant la détection comportementale et en réduisant jusqu’à 85% les faux positifs.
Le paradoxe de la sécurité cloud moderne
Les organisations migrant vers AWS découvrent rapidement un paradoxe troublant : plus elles adoptent de services cloud, plus le volume de données de sécurité explose, tandis que le temps pour réagir aux menaces se réduit.
Ce schéma représente l’organisation et l’interconnexion des principaux services AWS (EventBridge, SageMaker, Lambda) qui collaborent pour collecter, analyser et répondre automatiquement aux menaces via l’IA.
Dans un environnement AWS typique, CloudTrail génère des milliers d'événements par heure, CloudWatch collecte des centaines de métriques, et les VPC Flow Logs capturent chaque paquet réseau. Cette richesse d'informations devient rapidement ingérable avec les approches traditionnelles.
Les systèmes de règles statiques montrent leurs limites. Une règle comme "alerte après 5 tentatives de connexion échouées" ne distingue pas un développeur légitime qui a oublié son mot de passe d'un attaquant sophistiqué. Le résultat : une avalanche de faux positifs qui noient les vraies menaces.
Cette approche binaire ignore le contexte métier, les patterns comportementaux historiques et les corrélations entre événements. Elle traite chaque alerte isolément, sans comprendre qu'une tentative de connexion suspecte, un accès inhabituel à un bucket S3 et une modification IAM peuvent faire partie du même scénario d'attaque.
L'IA comme révolution comportementale
L'IA révolutionne cette approche en introduisant l'analyse comportementale contextuelle. Plutôt que des règles rigides, elle apprend continuellement des patterns normaux pour identifier les anomalies significatives.
Le processus débute par une phase d'apprentissage où l'IA analyse l'historique des activités légitimes. Elle identifie qui se connecte habituellement quand, d'où, avec quels patterns d'utilisation des services AWS. Elle comprend les cycles métier, les pics d'activité normaux, les corrélations entre systèmes.
Cette baseline devient la référence pour détecter les déviations. Quand un utilisateur accède depuis un pays inhabituel à 3h du matin, l'IA analyse le contexte : voyage-t-il fréquemment ? Son équipe travaille-t-elle sur un projet international ? Les services accédés correspondent-ils à ses responsabilités ?
Cette approche contextuelle calcule un score de risque nuancé (entre 0 et 1) plutôt qu'un simple "alerte/pas d'alerte". Un score de 0.3 indique une activité légèrement inhabituelle nécessitant une surveillance renforcée, tandis qu'un score de 0.9 déclenche une investigation immédiate.
Ce schéma détaille le flux opérationnel automatisé depuis la détection d’un événement critique jusqu’à la prise de décision et l’activation des actions de réponse adéquates, illustrant le processus métier que l’IA orchestre pour sécuriser l’environnement AWS.
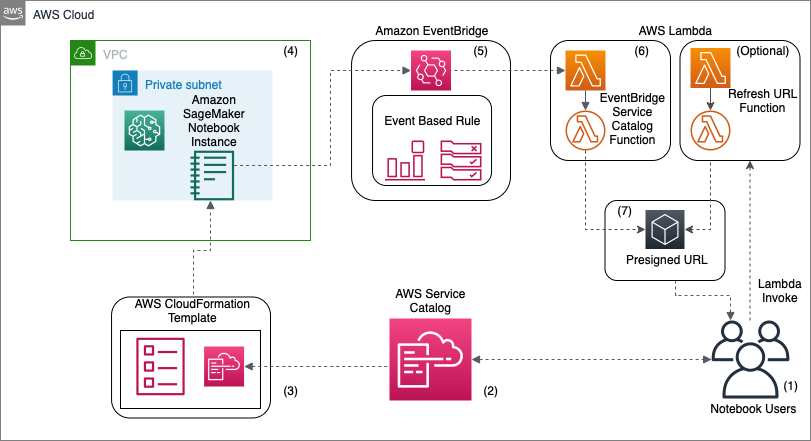
Architecture technique en trois composants
L'implémentation s'articule autour de trois composants qui s'intègrent dans l'écosystème AWS existant.
Premier composant : Collecte intelligente Amazon EventBridge capture en temps réel les événements de CloudTrail, GuardDuty, Security Hub et VPC Flow Logs, en appliquant des filtres intelligents pour router différents types d'événements selon leur criticité.
resource "aws_cloudwatch_event_rule" "security_intelligence" {
name = "ai-threat-detection"
event_pattern = jsonencode({
source = ["aws.guardduty", "aws.securityhub", "aws.cloudtrail"]
detail-type = ["GuardDuty Finding", "Security Hub Findings"]
})
}
Deuxième composant : Analyse IA Amazon SageMaker héberge des modèles de machine learning spécialisés dans la détection d'anomalies. L'algorithme Isolation Forest analyse les patterns d'utilisation pour identifier les comportements suspects.
class CloudSecurityAI:
def __init__(self):
self.isolation_forest = IsolationForest(contamination=0.1)
def analyze_user_behavior(self, cloudtrail_events):
features = self.extract_behavioral_features(cloudtrail_events)
anomaly_scores = self.isolation_forest.decision_function(features)
return {
'threat_level': self.calculate_risk_score(anomaly_scores),
'suspicious_patterns': self.identify_attack_vectors(features),
'recommended_actions': self.generate_response_strategy(anomaly_scores)
}
Troisième composant : Réponse automatisée AWS Lambda orchestre les actions selon le niveau de risque. Pour une menace critique (score > 0.8), isolation automatique de la ressource. Pour une menace modérée (0.5-0.8), monitoring renforcé et investigation. Pour une activité inhabituelle (<0.5), enrichissement des logs.
Services AWS intelligents
Amazon GuardDuty utilise déjà le machine learning pour identifier les activités malveillantes en analysant des téraoctets de données en temps réel. Sa nouveauté : l'analyse du trafic réseau des fonctions Lambda et la détection d'activités de cryptominage.
AWS Security Hub agit comme cerveau central, agrégeant et corrélant les findings multiples. Son IA excelle dans la réduction du bruit en regroupant automatiquement les alertes connexes et en calculant des scores de priorité contextuels.
Amazon Macie utilise l'IA pour découvrir et protéger automatiquement les données sensibles. Au-delà de la reconnaissance de formats, Macie comprend le contexte métier et détecte les fuites subtiles comme l'accès inhabituel à des documents confidentiels.
Implémentation progressive
L'implémentation suit trois phases pour minimiser les risques de perturbation.
Phase 1 : Baseline (2-4 semaines) Établissement de la baseline comportementale sans actions automatiques. L'IA apprend les patterns normaux incluant différents cycles métier.
Phase 2 : Détection passive L'IA génère des scores de risque sans déclencher d'actions automatiques. Objectif : moins de 15% de faux positifs avant l'automatisation.
Phase 3 : Automatisation graduée Activation des réponses automatiques pour les scénarios critiques, supervision humaine maintenue pour les cas complexes.
Mesurer le succès
Le succès se mesure par trois indicateurs clés :
Temps moyen de détection (MTTD) : réduction typique de 4 heures à 15 minutes pour les menaces critiques.
Réduction des faux positifs : passage de 85% à 12%, transformant l'expérience des équipes sécurité.
Automatisation des réponses : 80% des incidents de niveau 1 traités automatiquement.
def calculate_security_metrics():
detection_metrics = {
'mean_time_to_detection': calculate_mttd(),
'false_positive_rate': calculate_false_positive_ratio(),
'automated_response_rate': calculate_automation_percentage()
}
# Publication vers CloudWatch
for metric_name, value in detection_metrics.items():
cloudwatch.put_metric_data(
Namespace='Security/AI',
MetricData=[{'MetricName': metric_name, 'Value': value}]
)
Vers une sécurité autonome
L'évolution ne s'arrête pas à la détection. L'IA générative transforme l'investigation d'incidents en automatisant la génération de rapports détaillés et de recommandations. La prédiction de menaces permet d'anticiper les vecteurs d'attaque probables et de suggérer des mesures préventives.
L'objectif : une sécurité autonome gérant les incidents de routine tout en apprenant continuellement, avec maintien de l'expertise humaine pour les cas complexes.
L'IA comme multiplicateur d'expertise
L'automatisation intelligente, optimisée par l'IA, renforce considérablement la sécurité cloud en agissant comme un multiplicateur d'expertise humaine. L'IA analyse des volumes massifs de données et détecte des modèles complexes, permettant aux experts de se concentrer sur des tâches critiques. Cette synergie entre l'IA et l'humain marque une nouvelle ère pour la sécurité, où la technologie décuple les capacités d'analyse sans compromettre la prise de décision. Investir dans l'IA pour la sécurité offre un avantage concurrentiel durable, protégeant les actifs numériques et favorisant l'agilité nécessaire à la transformation digitale.
Sources et ressources
Documentation AWS officielle :
- Security in AWS Lambda
- Best practices for working with AWS Lambda functions
- AWS Lambda Security Best Practices - CloudViz
- How To Ensure your AWS Lambda Security - Sysdig
- The Future of Cloud Security: 7 Key Trends in 2025 - Cymulate
- Top Cloud Security Trends in 2025 - Check Point
- AWS Security Best Practices 2025 - SentinelOne
- US Cloud Security Challenges: Key Insights For 2025 - Cyble
- Top 2025 Cloud Security Predictions - Orca Security
À la découverte de Hunspell et autres spell checkers 8 Sep 12:22 AM (last month)

Si vous cherchez à construire une application de traduction ou de dictionnaire, votre principal souci sera d’avoir des données de qualité. Ajoutons en contraintes le fait que certaines langues sont à déclinaisons. Les personnes qui auront fait du latin ou de l’allemand reconnaîtront ce terme.
Dans une langue à déclinaisons, les mots changent de forme selon leur rôle grammatical dans la phrase. En albanais, il y a 5 cas grammaticaux : Nominatif (Sujet), Accusatif (COD), Datif (COI), Génitif (Indique la possession, souvent le complément du nom), Ablatif (Souvent utilisé avec des prépositions qui indiquent une origine).
Pourquoi l’albanais ? Parce que je développe justement une application mobile qui doit m’aider à déterminer les déclinaisons d’un mot albanais !
Autre particularité de cette langue : un mot se décline selon son rôle grammatical, mais aussi son nombre (singulier ou pluriel) et son caractère défini ou indéfini (le chien ou un chien). Un même mot a donc 20 déclinaisons possibles.
Pour illustrer, voici les déclinaisons du mot makinë (voiture) :
| singulier (numri njёjёs) |
pluriel (numri shumёs) |
|||
|---|---|---|---|---|
| forme indéfinie (trajta të pashquara) |
forme définie (trajta të shquara) |
forme indéfinie (trajta të pashquara) |
forme définie (trajta të shquara) |
|
| nominatif (emërore) |
(një) makinë | makina | (disa) makina | makinat |
| accusatif (kallëzore) |
(një) makinë | makinën | (disa) makina | makinat |
| génitif (gjinore)(i/e/të/së) |
(një) makine | makinës | (disa) makinave | makinavet |
| datif (dhanore) |
(një) makine | makinës | (disa) makinave | makinavet |
| ablatif (rrjedhore) (prej) |
(një) makine | makinës | (disa) makinash | makinavet |
Ce qui compte pour apprendre les déclinaisons en albanais, c’est de savoir la forme que prend le mot au nominatif pour chaque nombre et pour chaque caractère défini ou indéfini :
- nominatif indéfini singulier (Një makinë e kuqe - une voiture rouge)
- nominatif défini singulier (Makina e kuqe - la voiture rouge)
- nominatif indéfini pluriel (Disa makina të kuqe - des voitures rouges)
- nominatif défini pluriel (Makinat e kuqe - les voitures rouges)
En effet, même si les déclinaisons sont en général régulières, il existe des mots qui sont irréguliers. Certains dictionnaires fournissent donc une description des formes au nominatif du mot recherché.
Par exemple, sur fjalorthi.com, voici le résultat obtenu en recherchant makinë :
Ici, makin est le radical du mot, avec successivement :
- /ë pour le nominatif indéfini singulier, donc makin + ë, makinë
- -a pour le nominatif défini singulier, donc makin + a, makina
- -a pour le nominatif indéfini pluriel, donc makin + a, makina
- (t) pour le nominatif défini pluriel, donc makin + at, makinat
Obtenir un dataset qui fournit toutes les informations nécessaires à construire les déclinaisons
La complexité pour cette langue, qui est finalement assez peu parlée (environ 8 millions de locuteurs dans le monde), est d’avoir de la donnée libre de droit, gratuite et de qualité. C’est donc compliqué de savoir si un mot que vous écrivez est correct. D’ailleurs, comment les logiciels comme LibreOffice font-ils pour vérifier le format de ce qui est écrit ?
Hunspell, MySpell & Ispell, les spell checkers utilisés pour vérifier les mots
Hunspell est un spell checker. Littéralement, il vérifie comment un mot est épelé. C’est justement l’outil utilisé dans LibreOffice et dans nombre d'autres logiciels pour faire le spell checking (Firefox, Thunderbird, macOS, Opera…). Il s’agit de la troisième génération de spell checkers. Hunspell se base sur MySpell, lui-même basé sur ASpell et ISpell.
Installation
Hunspell s’installe facilement avec apt sur Linux ou avec brew pour MacOS. Vous pouvez aussi télécharger et compiler les sources si jamais ces méthodes ne vous conviennent pas. L’exemple sera sur MacOS.
brew install hunspell
Pour vérifier que l’installation s’est bien déroulée. Exécutez la commande suivante :
hunspell -v
Vous devriez avoir un résultat comme celui-ci (notez qu’Ispell et Myspell sont mis en avant) :
@(#) International Ispell Version 3.2.06 (but really Hunspell 1.7.2)
Copyright (C) 2002-2022 László Németh. License: MPL/GPL/LGPL.
Based on OpenOffice.org's Myspell library.
Myspell's copyright (C) Kevin Hendricks, 2001-2002, License: BSD.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE,
to the extent permitted by law.
Usage
Pour changer l’encodage de Hunspell, passez -i en argument. Par exemple :
hunspell -d sq_AL -i UTF-8
-d spécifie le dictionnaire à utiliser. Dans l’exemple ci-dessus, nous utilisons l’albanais. SQ est l’abréviation de Shqip, qui veut dire Albanais en Albanais.
Il y a de fortes chances que l’exécution de la commande ci-dessus produise cette erreur :
Can't open affix or dictionary files for dictionary named "sq_AL".
Cela signifie que Hunspell n’a pas le dictionnaire correspondant à l’entrée demandée (sq_AL). Dans ce cas, il faut en télécharger un. Hunspell travaille avec un couple de fichiers .dic et .aff qui ont des rôles bien définis.
Anatomie des fichiers .dic et .aff
Un fichier .dic liste ses mots un par un, avec un saut de ligne entre chaque :
ënjtur/LK
ënjtura/Z
ënjture
*ënjturëtet
Des caractères spéciaux sont aussi insérés. Le slash indique qu’une ou plusieurs règles sont définies dans le fichier .aff et s’appliquent à ce mot. Pour ënjtur, il s’agit de la règle L et de la règle K. Pour ënjtura, il s’agit de la règle Z. L’astérisque en préfixe indique un mot interdit dans le dictionnaire.
En regardant dans le fichier .aff pour chercher la règle Z, voici ce qu’on observe :
PFX Z Y 1
PFX Z 0 ç' .
Cela signifie :
- PFX = règle de préfixe
- Z = le nom de l’indicateur (c’est à cela que /Z fait référence dans le mot du dictionnaire)
- Y = ce préfixe peut être combiné avec des règles de suffixe si nécessaire
- 1 = il n’existe qu’une seule transformation de préfixe pour cet indicateur
Transformation : 0 ç’.
- 0 signifie « ne rien supprimer du début du mot »
- ç’ signifie « ajouter ceci au début »
- . (oui il y a un point à la fin de la deuxième ligne) signifie « appliquer à tous les mots » (aucune restriction de motif)
Donc, /Z indique à Hunspell “Génère une forme supplémentaire du mot précédée de ç’”
Par exemple :
- Forme de base : ënjtura
- Avec /Z : ç'ënjtura (qui signifie approximativement « ce qui est gonflé » au sens de « ce qui a gonflé » précédé d’un clitique « ç’ » comme « quoi » ou « lequel » en albanais).
Les règles sont nombreuses et le manpage de hunspell bien fourni. Je vous invite à lire le reste ! Finalement, ce double format plutôt malin de sources permet à partir de fichiers relativement petits de générer beaucoup de mots.
Récupérer et utiliser des fichiers .dic et .aff
Ces fichiers sont disponibles à plusieurs endroits en ligne. Dans mon cas, j’ai choisi de télécharger le dictionnaire MySpell mis à disposition par Shkenca ici :
https://www.shkenca.org/k6i/albanian_dictionary_for_myspell_en.html
C’est une organisation qui met en ligne de nombreuses ressources sur la langue albanaise, dont un dictionnaire en ligne et ce fichier. Hunspell est bien compatible avec MySpell.
C’est un zip. Décompressez-le dans un répertoire de travail. Commencez par faire attention à l’encodage des fichiers .dic et .aff. Par défaut, Hunspell travaille en UTF-8 mais les fichiers sont régulièrement dans un autre encodage. Dans ce cas, ou vous changez l’encodage des fichiers, ou vous spécifiez en option de Hunspell l’encodage à utiliser.
Attention cependant, le fichier .aff spécifie l’encodage à utiliser en début de fichier via l’instruction SET <encoding>.
Il faut que l’ensemble soit cohérent :
- encodage des fichiers .dic et .aff
- SET <encoding>
- argument -i.
Lorsque c’est fait, spécifiez le chemin des dictionnaires .dic et .aff. Il faut que le nom du fichier soit le même et que seule l’extension change. Pour des fichiers nommés sq_AL.dic et sq_AL.aff, voici la commande correspondante :
hunspell -d <path>/sq_AL -i utf8
Si tout se passe bien, l’interpréteur se lance :
Hunspell 1.7.2
À partir de là, vous pouvez soumettre vos mots albanais et voir ce que Hunspell va vous répondre. Essayez avec makinë :
makinë
*
L’astérisque signifie que le mot est valide pour Hunspell.
Essayez maintenant une déclinaison du mot qui n’existe pas :
makino
& makino 3 0: makine, makina, makinë
Ici, Hunspell indique qu’il y a une erreur dans la saisie et suggère 3 mots comme correction (d’où le chiffre 3 dans 3 0). Le chiffre 0 spécifie l’index dans la ligne du premier caractère du mot en erreur.
Essayons avec plusieurs mots. Pour tridhjetë e pesë makino (35 voitures) :
tridhjetë e pesë makino
*
*
*
& makino 3 17: makine, makina, makinë
Nous avons trois astérisques. Ils valident les 3 premiers mots. Le dernier mot est en erreur.
Limitations
Hunspell ne vérifie pas la bonne exécution des règles de grammaire. Il vérifie uniquement que les mots saisis existent en calculant un certain nombre de règles. Par exemple, si on lui soumet un équivalent albanais grammaticalement faux de “Ma voiture”...
makinë ime
*
*
…Hunspell considère que c’est valide, alors que makinë correspond au nominatif indéfini et ime au nominatif défini.
La version correcte serait makina ime :
makina ime
*
*
Attention alors à bien mesurer pour quel travail vous utilisez cet outil. Un correcteur orthographique mot à mot oui, mais il n’y aura pas de vérification de cohérence sur toute une phrase.
Dernier regret : il n’est pas possible de créer un dictionnaire “classique” à partir de dictionnaires construits pour Hunspell. L’open data sur l’albanais manquant un peu, ça aurait pu s’avérer très utile.
Conclusion
Connaître comment fonctionne Hunspell permet de comprendre comment fonctionnent certains correcteurs orthographiques, que ce soit pour leurs avantages et pour leurs limitations. Attention à bien le configurer et à maîtriser les objectifs recherchés. Malgré tout, c’est un super outil du monde opensource, dont le code et les dictionnaires sont maintenus de manière communautaire sur Weblate.
Pour aller plus loin
Il existe des implémentations dans beaucoup de langages de bibliothèques qui utilisent Hunspell. Pensez par exemple à Pyspell en Python !
Sources
- Page GitHub de Hunspell : https://hunspell.github.io
- Editing the spell checking dictionaries : https://www.chromium.org/developers/how-tos/editing-the-spell-checking-dictionaries
- Man Hunspell : https://linux.die.net/man/4/hunspell
- Weblate pour Hunspell : https://hosted.weblate.org/engage/hunspell
- Définition de clitique : https://fr.wikipedia.org/wiki/Clitique#:~:text=Un%20clitique%20est%2C%20en%20linguistique,plus%20pertinent%2C%20retirez-le.
Industrialiser vos modèles ML avec AWS SageMaker Batch Transform : Guide pratique BYOC 5 Sep 4:30 AM (last month)

Nous remercions Victor Barrau, notre collaborateur avec qui nous avons écrit cet article.
Dans un contexte où l'industrialisation des modèles de machine learning devient critique pour les entreprises, AWS SageMaker Batch Transform se présente comme une solution robuste pour le traitement par lots des inférences. Cet article explore comment adapter un modèle externe (BYOC - Bring Your Own Container) à SageMaker Batch Transform et pourquoi cette approche peut être pertinente pour votre cas d'usage.
Pourquoi faire du batch ?
Le choix du traitement par batch plutôt que du temps réel repose sur plusieurs considérations stratégiques :
- Optimisation des ressources : un endpoint en temps réel implique des ressources allouées en permanence, même lorsqu’il n’est pas sollicité. Le batch processing, en revanche, fonctionne à la demande, optimisant l’usage des infrastructures.
- Réduction des coûts : la facturation est basée uniquement sur l’exécution des tâches, ce qui est idéal pour les charges de travail intermittentes.
- Scalabilité : capable de gérer de vastes volumes de données, le batch processing est adapté aux besoins où la latence en temps réel n’est pas nécessaire.
- Simplicité opérationnelle : la gestion des infrastructures est plus simple qu’une architecture en temps réel, réduisant ainsi la complexité de déploiement et de maintenance.
Le traitement par batch est pertinent pour des tâches comme l’inférence sur un grand jeu de données en une seule exécution, l’analyse d’images ou de documents en masse, ou encore la classification de contenus. Ces cas d’usage ne nécessitent pas une réponse instantanée, car les résultats peuvent être exploités après coup sans impacter directement l’expérience utilisateur ou le processus métier en temps réel.
Quand choisir AWS Sagemaker et pourquoi ?
AWS SageMaker est une plateforme managée qui propose un ensemble de services pour le développement, l'entraînement et le déploiement de modèles de machine learning. Cette approche managée délègue la gestion des infrastructures à AWS, permettant aux équipes de se concentrer sur le développement des modèles plutôt que sur l'orchestration des ressources.
La plateforme offre une intégration native avec l'écosystème Python et les frameworks ML courants (TensorFlow, PyTorch, Scikit-Learn). SageMaker couvre différentes étapes du cycle de vie ML à travers des services modulaires : développement interactif (Studio, Data Wrangler), entraînement (Training distribué, AutoML) et déploiement (Batch Transform, Endpoints, Pipelines, Model Monitor).
Cette approche modulaire permet aux équipes d'adopter uniquement les services nécessaires à leur projet. L'intégration avec les autres services AWS (S3, IAM, CloudWatch, Lambda) facilite l'intégration dans un écosystème existant.
Cependant, cette approche présente certaines contraintes :
- Couplage avec l'écosystème AWS
- Courbe d'apprentissage pour maîtriser les spécificités SageMaker
- Coûts potentiellement plus élevés pour des cas d'usage simples
- Moins de contrôle granulaire comparé à une solution sur-mesure
Le choix de SageMaker dépend donc du contexte : taille de l'équipe, expertise DevOps disponible, contraintes budgétaires et besoins de scalabilité.
Par exemple, les équipes disposant d'une forte expertise Kubernetes préféreront souvent Kubeflow pour sa portabilité multi-cloud et la maîtrise complète de l'orchestration.
De même, les projets nécessitant un contrôle fin de l'infrastructure, comme le debugging avancé des modèles ou l'implémentation d'optimisations système spécifiques, trouveront les abstractions de SageMaker limitantes. Dans ces cas, une approche custom sur EC2 ou Kubernetes offre la granularité nécessaire, même si elle implique une charge opérationnelle plus importante.
Enfin, les contraintes de souveraineté des données peuvent rendre SageMaker inadapté lorsque l'hébergement doit se faire dans des datacenters spécifiques ou sous certaines juridictions.
Alternatives à SageMaker Batch Transform dans l’environnement AWS
Bien que SageMaker Batch Transform soit une solution robuste, d'autres approches méritent considération selon le contexte et les contraintes spécifiques du projet.
AWS Batch avec Step Functions constitue une alternative pour les équipes recherchant un contrôle sur l'infrastructure tout en conservant les bénéfices d'un service managé. Cependant, elle demande une expertise plus poussée en configuration AWS et peut présenter des temps de démarrage à froid impactant les performances pour des tâches courtes.
ECS avec Step Functions s’adresse aux équipes techniques privilégiant la flexibilité maximale. Cette architecture permet un paramétrage fin des ressources et des stratégies d'auto-scaling. La contrepartie réside dans une complexité opérationnelle significative et des coûts potentiellement plus élevés sans un monitoring rigoureux.
Amazon EKS (Elastic Kubernetes Service) représente une option intéressante pour les équipes déjà familiarisées avec l'écosystème Kubernetes. Cette approche offre une portabilité multi-cloud et permet d'exploiter des outils spécialisés comme Kubeflow pour les workflows ML. EKS convient particulièrement aux organisations ayant une stratégie container-first ou souhaitant maintenir une cohérence technologique avec leurs autres applications. Cependant, cette solution nécessite une expertise Kubernetes solide et implique une charge opérationnelle plus importante que les services managés.
Le choix optimal dépend de plusieurs facteurs : la maturité de l'équipe, les contraintes budgétaires et la stratégie cloud de l'organisation. SageMaker reste pertinent pour les équipes privilégiant la rapidité de mise en œuvre et l'intégration native avec l'écosystème AWS, tandis que les alternatives offrent plus de contrôle au prix d'une complexité accrue.
Comment utiliser Batch Transform pour différents besoins ?
Si SageMaker Batch Transform est principalement conçu pour l'inférence par lots, son utilisation peut être étendue à d'autres cas d'usages stratégiques dans le cycle de vie des modèles de machine learning. Cette section explore les applications pratiques de Batch Transform au-delà de son utilisation conventionnelle.
Batch Transform appliqué au cycle de développement et validation.
Même si l'entraînement classique se fait généralement via des jobs dédiés, Batch Transform offre des atouts significatifs pour la phase de validation et d'expérimentation. Cette approche permet de couvrir une multitude d'actions nécessaires pour la mise en production :
- Validation à grande échelle : après l'entraînement, évaluer la robustesse du modèle sur des datasets étendus via des jobs parallélisés, sans nécessiter d'endpoints permanents.
- Tests A/B comparatifs : appliquer différentes versions de modèles sur des batchs identiques pour une analyse objective des performances et décider quelle version déployer en production.
- Détection de data drift : le "data drift" désigne la divergence entre données d'entraînement et de production, causant une dégradation des performances. Un modèle de ventes de glaces entraîné sur des données d'été perdra en précision l'hiver. Batch Transform permet de détecter périodiquement ces dérives sur des échantillons récents, anticipant ainsi les besoins de ré-entraînement avant une dégradation significative.
Comment créer un modèle Sagemaker à partir d’un modèle de machine learning entraîné en local
Un modèle Sagemaker est capable d’exécuter un ou plusieurs modèles de machine learning. Pour créer un modèle Sagemaker, il est nécessaire de fournir une image de conteneur qui sera utilisée pour effectuer les inférences. Cette image est appelée image primaire. Des images secondaires peuvent également être fournies au modèle si nécessaire.
Supposons que nous disposons d’un modèle de machine learning entraîné hors de Sagemaker (approche BYOC) et possédant des fichiers de poids (dans le cadre du transfert learning par exemple). Pour importer ce modèle dans Sagemaker afin de l’utiliser pour effectuer des inférences, il faut que ce modèle soit partie intégrante d’un modèle Sagemaker.
Pour ce faire, il faut procéder comme suit :
- Conteneuriser le modèle (s’il ne l’est pas déjà) et stocker l’image du conteneur dans un registre ECR (Elastic Container Registry).
- Créer une archive (au format tar.gz) contenant les artefacts du modèle de machine learning (ici le dossier contenant les fichiers de poids) puis stocker cette archive dans un bucket S3. En effet, Sagemaker exige dans certains cas tels que l’utilisation de Batch Transform, que les artefacts du modèle soient stockés dans un fichier compressé. Hormis ces cas, il est possible de créer un modèle ne nécessitant pas de compression préalable des artefacts en spécifiant à la création du modèle l’option ModelDataSource afin d’indiquer l’emplacement dans S3 où sont stockés les artefacts du modèle.
- Créer le modèle Sagemaker en lui fournissant l’image primaire à utiliser et le lien vers l’archive contenant les artefacts du modèle.

Comment optimiser les inférences avec Sagemaker ?
Sagemaker propose un large éventail d’instances pour la réalisation d’inférences. Le choix du type d’instance approprié à vos besoins dépend des performances que vous souhaitez atteindre et de votre budget. Optimiser les inférences nécessite d’effectuer des tests de charge sur différents types d’instances et avec différentes configurations telles que l’exécution de tâches sur une seule instance ou la parallélisation de tâches sur plusieurs instances.
Dans le cas d’une tâche Batch Transform, il est possible d’optimiser l’inférence en modifiant dans la configuration de lancement de la tâche les valeurs par défaut de certains paramètres tels que MaxConcurrentTransforms, BatchStrategy, et MaxPayloadInMB. Si aucune valeur n’a été renseignée pour ces paramètres, avant d’utiliser leurs valeurs par défaut, SageMaker enverra une requête HTTP GET à l'instance lorsqu’elle démarrera, sur le point de terminaison /execution-parameters (si vous l’avez implémenté dans le modèle).
Paramètre | Description | Valeur par défaut |
MaxConcurrentTransforms | Nombre maximal de requêtes pouvant être envoyées en parallèle à chaque instance dans une tâche. Si la valeur n’est pas définie ou est égale à 0 et que le point de terminaison / execution-parameters n’a pas été implémenté dans le modèle, la valeur par défaut sera utilisée. | 1 |
BatchStrategy | Stratégie à utiliser pour les enregistrements. Un enregistrement correspond à une unité de données d'entrée (par exemple une ligne dans un fichier CSV) sur laquelle une inférence peut être réalisée. Pour n'utiliser qu'un seul enregistrement par requête d’inférence, spécifiez la configuration suivante :
Pour inclure dans chaque requête d’inférence autant d'enregistrements que la limite MaxPayloadInMB le permet, utilisez la configuration suivante :
| MULTI_RECORD |
MaxPayloadInMB | Taille maximale (en Mo) autorisée pour la charge utile. La charge utile correspond aux données d'un enregistrement, sans les métadonnées. La valeur de MaxPayloadInMB doit être supérieure ou égale à la taille d'un enregistrement. Pour estimer la taille d'un enregistrement en Mo, il suffit de diviser la taille de votre jeu de données par le nombre d'enregistrements. Afin de garantir que les enregistrements respectent la taille maximale de la charge utile, AWS recommande d'utiliser une valeur légèrement supérieure. La valeur maximale de MaxPayloadInMB est de 100 Mo. Si le paramètre MaxConcurrentTransforms est spécifié, la valeur de MaxConcurrentTransforms x MaxPayloadInMB ne peut pas non plus dépasser 100 Mo. | 6 |
Méthodologie pour les tests de charge
La première étape consiste à tester votre modèle sur une instance de base (ml.m5.large par exemple) avec les paramètres par défaut. Cette baseline vous permettra d'évaluer l'impact des optimisations suivantes.
Testez ensuite différentes configurations en ne modifiant qu'un paramètre à la fois. Par exemple, augmentez progressivement MaxConcurrentTransforms de 1 à 4, puis testez différentes valeurs de MaxPayloadInMB. Cette approche méthodique permet d'identifier l'impact de chaque paramètre indépendamment.
Les métriques clés à surveiller incluent :
- Le débit : nombre d'inférences par minute
- La latence moyenne : temps moyen par requête
- L'utilisation des ressources : CPU, mémoire et GPU si applicable
- Le coût par inférence : calcul du coût total divisé par le nombre d'inférences
Comme nous pouvons le constater, l’optimisation des inférences nécessite des compétences en machine learning, du temps et des efforts (qui peuvent parfois être conséquents) pour pouvoir effectuer les tests nécessaires. Afin de faciliter ce processus, Sagemaker dispose d’une fonctionnalité nommée SageMaker Inference Recommender : c’est un outil qui permet d’automatiser les tests de charge et d’effectuer des recommandations sur les instances susceptibles d’être les plus adaptées à la réalisation d’inférences avec votre modèle.
SageMaker Inference Recommender automatise ce processus d'optimisation en lançant des tests comparatifs sur différents types d'instances et configurations. L'outil évalue automatiquement diverses valeurs pour MaxConcurrentTransforms, BatchStrategy et MaxPayloadInMB, puis présente les résultats sous forme de métriques de performance et d'utilisation des ressources. Cette approche vous évite les tests manuels fastidieux et vous aide à identifier rapidement la configuration optimale pour vos besoins spécifiques.
Choix CPU vs GPU
Important à retenir : SageMaker Batch Transform ne propose pas d'autoscaling automatique. Le nombre d'instances est défini au lancement du job et reste fixe pendant toute sa durée. Cette approche diffère des endpoints en temps réel qui supportent l'autoscaling.
Choix entre CPU et GPU : Les instances CPU (séries ml.m5, ml.c5) sont généralement suffisantes pour :
- Les modèles de machine learning classiques (régression, classification avec scikit-learn)
- Le traitement de données tabulaires
- Les modèles de NLP légers
Les instances GPU (séries ml.p3, ml.g4dn) sont nécessaires pour :
- Les réseaux de neurones
- Le traitement d'images
- Les modèles de NLP volumineux
- Toute inférence nécessitant des calculs matriciels intensifs
Conclusion
AWS SageMaker Batch Transform constitue une option viable pour l'industrialisation des modèles de machine learning lorsque l'inférence en temps réel n'est pas requise. Cette solution peut s'étendre au-delà du traitement par lots classique pour couvrir la validation de modèles, la détection de data drift, ou l'optimisation des pipelines MLOps.
L'approche BYOC (Bring Your Own Container) offre la flexibilité nécessaire pour adapter des modèles existants. Cette flexibilité implique cependant une responsabilité en termes d'optimisation : comprendre les paramètres de configuration et mettre en place une méthodologie de test appropriée reste essentiel pour obtenir des performances satisfaisantes.
Avant de choisir cette solution, il convient d'évaluer si les bénéfices (infrastructure managée, intégration AWS) compensent les contraintes (couplage, coûts, courbe d'apprentissage) par rapport aux alternatives disponibles.