建立历史视角、锤炼远见目光:《数据库简史》一书出版 19 Aug 2024 6:36 PM (last year)
一段时间以来,很多朋友一直问我,新书的进展如何?现在终于可以回复大家:《数据库简史》一书终于正式出版!
《数据库简史》一书是我写作时间最长、遭遇挑战最大、编辑修订最多的一本。之所以说挑战最大,是因为这是一次全新的写作历程,和过往我的书籍完全不同,这本书不是讲数据库的技术细节,而是侧重数据库技术的发展历史。
本书动因
为什么要写作这样一本书?
最直接的因素当然是:中国数据库市场迎来了国产数据库时代!
伴随着国产数据库的研发突飞猛进,中国数据库从产品应用时代进入了产品研发时代,相应的也从DBA时代进入了DEV时代。
而我在数据库行业从业25年,也自然希望能够为中国的"数据库产品研发时代"做点贡献,无论是亲身参与还是呐喊助威。
从亲身参与上,云和恩墨基于 openGauss 推出了国产数据库 MogDB ;从呐喊助威上,创作一本图书的创意就默默酝酿。
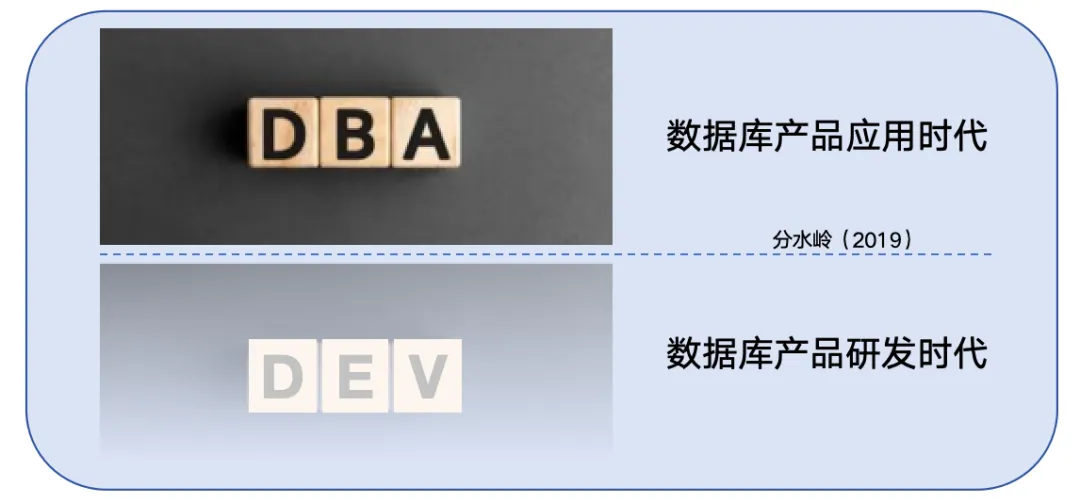
如何能够更好的研发数据库产品?我认为既要洞悉历史,又要洞察未来。而数据库技术经过60多年的发展,历史悠久、积淀深厚、人才辈出...如果能够将数据库的发展历史呈现出来(包括技术演进历程、天才人物贡献、产品成败得失、行业传奇佚事等),一定能为中国数据库产业发展作为借鉴。
最终,《数据库简史》一书中共对30多个国产数据库产品进行了描述和介绍,据编辑统计,全书共涉及人物100多人,数据库产品80多个。
正如李国良教授在给本书的推荐序中写道:
数据库是基础软件皇冠上的明珠,被广泛应用到国家关键基础行业中。数据库有着60多年的发展历史,诞生了很多数据库历史名人和诸多事迹。但是市场上很少有书籍详细介绍数据库技术、系统、开拓者的历史,而《数据库简史》一书弥补了这一空白,为数据库从业者了解数据库历史提供了丰富宝贵的材料。
为什么能够写作这样一本书,正是因为我自己在研究数据库技术时,常常就是追根究底的从历史根源、技术根源开始的。熊伟博士在为本书撰写的序言中同样表达了他在学习数学上的体味心得:
如同想要了解纷繁复杂的数学体系,最好看一下数学发展史一样,如果想对当今数据库体系有一个深入的了解,学习一下数据库的发展史,对于在我们脑海里建立数据库体系的知识大厦大有助益。
除了以史为鉴的写作意图,中国的基础软件产业发展,举步维艰,更需要更多人的了解与支持。所以我也希望写一本能够让更多人了解数据库技术的普及读物,让更多人关注、了解、支持这个行业,也希望有更多的有志之士加入数据库行业,以天时、地利、人和共同铸就中国数据库产业的繁荣。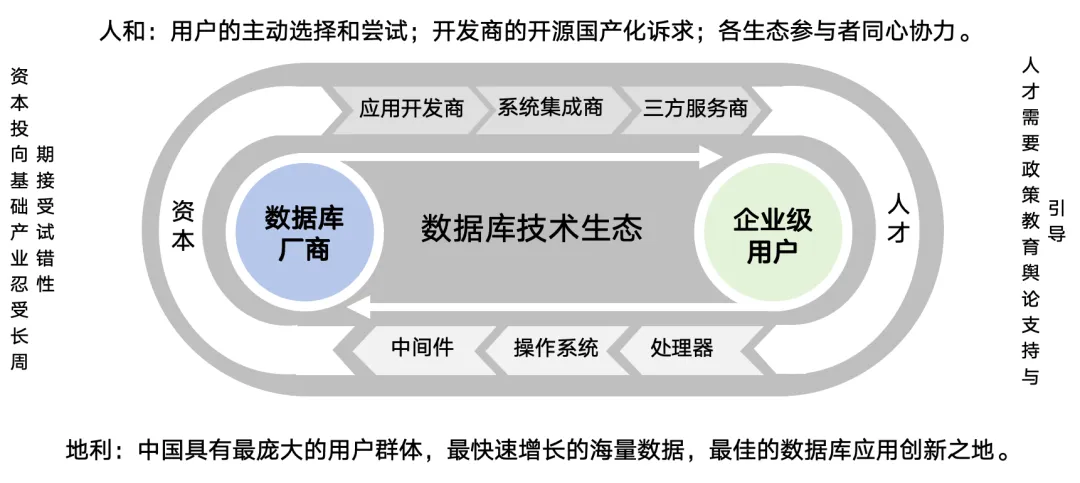
写作起点
灵光一闪并非难事,但是真正下定决心动笔又是一个漫长的心路历程,我在《数据库简史》一书的序言中简要描述了这个过程:
-
当我们踏入数据库基础软件研发领域之后,深刻地感受到了这个领域的艰难与挑战,也切肤之痛般体验到这个领域人才之稀缺、关注之缺乏、力量之分散,我想在自己亲身入局的参与之外,也力所能及的为中国数据库产业做一点点号召和贡献。
-
于是,我们打造了"墨天轮中国数据库技术社区",推出了"中国数据库流行度排行榜",希望以客观中立的视角,为中国数据库的流行度作出参考。
-
随后,我们为了洞悉数据库的历史,展示当下数据库格局,呈现中国数据库创新,精心绘制了一张"数据库简史"海报,将数据库技术发展脉络和突出的品牌凸显出来,为中国数据库产业摇旗呐喊。
-
以上两件事的前因则更是可以追溯到2000年我们发起倡议的ITPUB社区,以及在2013年开始绘制的"Oracle数据库体系结构图",前者曾汇聚360万会员,后者则发行超过5万张。
-
在"数据库简史"海报印行之后,在和一些行业专家、客户交流时,他们就提出建议:"老盖,你画的不错,讲的挺好,可是你走之后我们的印象又淡忘了。你能不能将这些写下来,成为一本书,给行业一个参考?"
有了种种前因,自然还需要一个时点触发。一次机缘巧合之下,人民邮电出版社的蒋艳和李莎老师来公司访问,她们带来了一批优秀图书供我学习,其中有一本书是《人工智能简史》。
蒋老师就提议:"能不能写一本《数据库简史》,为中国蓬勃发展的数据库行业提供借鉴参考?海报还可以作为插图。你特别适合来执笔。"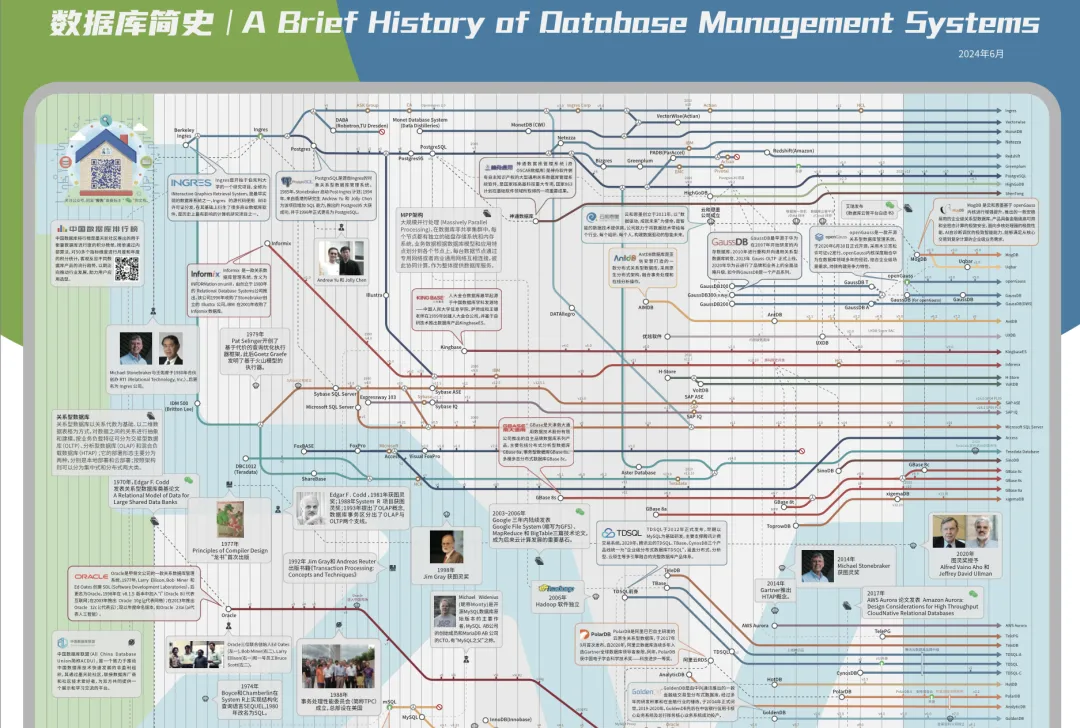
我说:"适不适合不知道,但我可以试试。"
内容组织
头脑一热是很容易的,但是瓜熟蒂落却要十月怀胎。动笔之后,才知道自己虽然有20多年的职业历程,但对行业的认知和了解仍然十分有限,这几乎是一项不可能完成的任务。
但是总归是发愿,自然不能中辍。就且行且珍惜吧。
好在,在持续不断的努力改进之下,在我的编辑的精心校订之后,这本书终于得以呈现在大家面前。
在中国数据库蓬勃发展的时代,我认为回顾历史也非常重要。
回顾历史,呈现当下,探讨未来,全书共分为10个章节。
- 第1章,数据和数据库。以一以贯之的脉络,纵览数据和数据库技术的发展历程,从勒石以记到大语言模型,从概念和应用上探讨了数据和数据库的价值。
- 第2章,数据库技术的拓荒者。试图通过4位数据库领域的图灵奖获得者,阐述这些引领时代的先驱如何洞察和开拓了数据库的广阔天空。在介绍这4位天才之前,我们还简单回顾了计算机的发展历程,以及图灵的传奇一生。
- 第3章,数据库领域的先知。讲述了Oracle公司的故事,在英文中,Oracle一词有"先知"之意,Oracle公司对关系型数据库探索之早、成就之高使其成为了行业中不断研究和学习的对象。Oracle占据了数据库领域的半壁江山,其成功之路值得用一章去重点描述。
- 第4章,数据库产品的先行者。讲述了DB2、dBASE、Ingres和MySQL等4个产品,它们和Oracle一起主导了丰富多彩的早期数据库市场,其中有的产品失败了,有的仍然光彩夺目,值得我们回顾其成就,警示其挫折。
- 第5章,中国数据库的早期探索。回顾了自1977年首届中国数据库学术年会开始,我国学术界和工业界对数据库技术的不懈探索和全方位尝试。从技术到教育,从产品到社区,正是这些探索让数据库人能够薪火相传。
- 第6章,互联网和云的新篇章。揭开了数据库技术变革的新时代,正是因为互联网和云计算的发展,彻底改变了数据库市场的格局,这也使得新兴的数据库创新企业和产品不断崛起,中国的数据库产品开始站上了国际舞台。
- 第7章,开源根社区的崛起。探讨了在全球供应链风险之下,中国数据库根社区的建设和发展。坚持开源、开放,向世界展示中国创新;合力共建共享,让用户和企业必备一个可信的中国选择。
- 第8章,中国数据库的产业格局。分析了国内数据库产品和企业的典型特征、技术路线、开源趋势,对比了国际数据库的创新特性与人才竞争,同时为中国数据库产业的发展提出了建议。
- 第9章,数据库架构演进和未来。通过回溯数据库架构发展脉络,展示了不同要素对于数据库技术的关键影响,以及不同产品在不同阶段实现的架构创新,并探讨了数据库技术演进的未来。
- 第10章,天道酬勤,缘起数据终不悔。这是我自身成长经历的分享和总结。作为在数据库领域摸爬滚打25年的老兵,从程序员到DBA再到创业者,亲历历史,以此作为附录,或许可以为走在不同成长阶段的读者提供一点参考。
总结
中国是否需要自己的数据库?我想这个问题的答案已经清晰无比。在基础软件领域,从操作系统、中间件到数据库,中国企业正在构建起新的技术体系,以保障中国蓬勃发展的数字经济。这有挑战,也是机遇。
正如华为计算产品线总裁张熙伟在本书推荐序中所写的:
数据库被誉为基础软件皇冠上的明珠,是下接算力、上接应用的核心软件,一旦形成突破,必将推动全球相关产业价值链的重构。
中科软总裁左春先生也在本书的推荐序中写道:
作为应用软件最"有感"的系统软件,数据库系统的操作接口标准,也是应用型软件的重要接口,关系重大。
中国数据库产品的发展,也正如阿里云数据库掌门人李飞飞博士所说:
数据库系统从诞生那天起就为信息技术领域带来了翻天覆地的变化,在云计算和人工智能高速发展的今天,中国的数字化和智能化进程一定会带动中国数据库产品走向世界前列。
在2023年的"数据技术嘉年华"大会前,我曾经写了一篇文章,提出了一个问题:当大师遇见大师,他们会谈论什么?
两位图灵奖的获得者斯通布雷克(Stonebraker)和吉姆·格雷(Jim Gray)曾经在2002年的一次大会上表达对于行业同仁的观点:
-
斯通布雷克提出批评:大多数看似创新的想法实际上并不是新的,而是以前提出的。有一个强大的历史视角很重要,可以帮助我们避免重复发明轮子,避免重复历史错误。
-
吉姆·格雷表达激励:如果你有眼光,就一定要追求有远见的研究。尽可能花时间去做自己引以自豪的事情,尽量不做无意义的事情。

两位天才人物不约而同地告诉我们:建立历史视角、锤炼远见目光 非常重要。
丘吉尔也曾说过:"回顾历史越久远,展望未来就越深远。"回顾数据库的历史,对我们研究和思考数据库的未来会有很多有益的启示。
毫无疑问,中国的数据库产业正在崛起,越来越多的产品和创新正在跻身世界尖端。相信在一代又一代数据人的努力之下,一定会迎来数据库的"中国时刻"。我相信,每一分努力都是推动中国数据库技术进步的力量。
点点星光,汇聚星河,此时此刻,中国数据库领域正是群星闪耀时刻。
本文网址:https://www.eygle.com/archives/2024/08/dbbrief_history_release.html









MySQL 第一个版本的正式发布时间 11 Jun 2024 5:18 PM (last year)
关于 MySQL 的历史,有很多不同的描述,但是无疑MySQL AB的创始人阐述的最为准确和可靠。
David Axmark 和 Michael Widenius 在《MySQL Introduction》一文中这样记录了过去:
In May 1996, MySQL version 1.0 was released to a limited group of four people, and in October 1996, MySQL 3.11.1 was released to the public as a binary distribution for Solaris. A month later, a Linux binary and the source distribution were released. The MySQL release included an ODBC driver in source form. This also included many free MySQL clients ported to MySQL.
1996年5月,MySQL 1.0版本发布,仅限四人使用。1996年10月,MySQL 3.11.1版本作为Solaris系统的二进制分发版向公众发布。一个月后,发布了Linux的二进制版本和源代码分发版。MySQL发布包括了以源代码形式提供的ODBC驱动。这也包括了许多移植到MySQL的免费MySQL客户端。
参考链接:https://dl.acm.org/doi/fullHtml/10.5555/328036.328041
本文网址:https://www.eygle.com/archives/2024/06/mysql_first_release.html
循序渐进MogDB:如何通过copy转储表数据到CSV文件 28 May 2024 6:04 PM (last year)
在 MogDB 数据库中,通过 copy 命令可以灵活的将数据复制到数据库中,或者,将表数据转储到磁盘文件。当转储文件时,也可以通过 with 子句指定具体的参数,实现多样化输出文件的支持。
以下是一个范例,通过 with 语句,可以指定导出数据的分隔符(delimiter),是否包含头文件信息等:
MogDB=>copy student to '/home/omm/student.csv' with (format csv,delimiter ',',header on);
COPY 5467MogDB=>copy people to '/home/omm/people.csv' with (format csv,delimiter ',',quote '"',header on);
COPY 518
当然,也可以使用 MogDB 的客户端工具,Mogeaver] 的 Data Transfer 功能进行数据的转换。Mogeaver 的好处是,可以分批次提交,减少内存的耗用。
向数据库中加载 CSV 文件参考:
循序渐进MogDB:通过 copy 加载 CSV 文件到数据库
本文网址:https://www.eygle.com/archives/2024/05/mogdb_copycsv.html
官网更换首页:Oracle旗帜鲜明表明立场支持以色列 18 Oct 2023 12:16 AM (2 years ago)
Oracle谴责针对以色列及其公民的恐怖袭击。Oracle将为其员工、以色列政府和国防机构提供一切必要的支持。
Magen David Adom是一家为以色列公民提供紧急医疗服务的非营利组织,致力于减轻任何地方的人类痛苦,保护所有人的健康和尊严。Oracle将为员工向这一重要组织的捐款提供等额资助。
此前,Oracle已承诺向Magen David Adom捐赠100万美元,并正在发起一场活动,鼓励其15万名员工捐款,Oracle还将为员工捐款实现等额捐助。Oracle首席执行官萨夫拉·卡茨(Safra A. Catz)公开谴责了这些袭击。
Safra A. Catz,出生于以色列,小时候随家人移民到美国,她能讲流利的希伯来语。Catz 自1999年4月起担任甲骨文公司高管,自2001年起担任董事会成员。2011年4月,她被任命为联席总裁兼首席财务官,向创始人拉里·埃里森汇报工作。2014年9月,甲骨文宣布埃里森将辞去首席执行官一职,马克·赫德和卡茨已被任命为联合首席执行官。2019年9月,赫德因健康问题辞职后,卡茨成为唯一的首席执行官。
此外,众所周知,Oracle公司的创始人 Larry Ellison有一半的犹太血统,他母亲是犹太人,父亲是一个意大利飞行员。
Catz 曾经公开表达说:"当你与Oracle公司联系时,你就会明白我们对美国和以色列的承诺。我们对自己的使命没有丝毫弹性,我们对以色列的承诺是首屈一指的。这是一个自由的世界,我爱我的员工,如果他们不同意我们支持以色列国的使命,那么也许我们公司不适合他们。拉里和我公开承诺支持以色列,并将个人时间投入到这个国家,任何人都不应该对此感到惊讶。"
Oracle公司向来旗帜鲜明,这一次也毫不例外。不谈立场,让我们共同期待世界和平。
本文网址:https://www.eygle.com/archives/2023/10/oracle_corp_support_israel.html
Oracle Database 23c 新特性: 基于别名和位置的 GROUP BY 简化 29 Sep 2022 5:18 PM (3 years ago)
在Oracle Database 23c 中,group by 作出了一个期待已久的增强,支持通过别名或者位置的Group by 查询。
在23c之前,group by 要不断重复查询中的复杂逻辑,如下所示:
SELECT EXTRACT(year FROM hiredate) AS hired_year, COUNT(*) from emp
GROUP BY extract(year FROM hiredate) HAVING extract(year FROM hiredate) > 1985;
在23c中,可以通过别名大大简化这一SQL:
SELECT EXTRACT(year FROM hiredate) AS hired_year, COUNT(*) from emp
GROUP BY hired_year HAVING hired_year > 1985;

这是开发者期待已久的,终于在 23中得以实现。
本文网址:https://www.eygle.com/archives/2022/09/oracle_database_23c_groupby.html
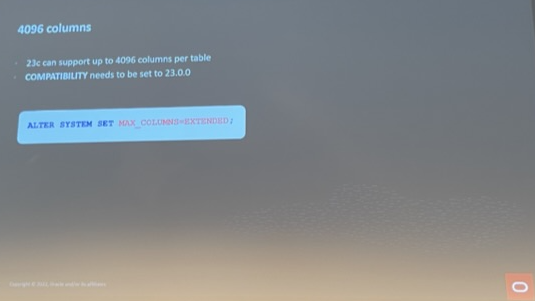
Oracle Database 23c 新特性:4096 列支持和 Schema 权限一次授予 27 Sep 2022 11:33 PM (3 years ago)
我们知道 MogDB 单表最大支持 1600 列,Oracle 此前版本单表支持 1000列。
在23c中,单表支持列数量扩展到 4096 列。启用这一个特性需要将兼容性参数设置为23.0.0,同时将 Max_columns设置为 Extended:
alter system set MAX_COLUMNS=EXTENDED;
在23c之前的版本,如果针对 Schema 对其他用户进行授权,需要通过系统权限 或 对象权限 分别显示的授予,这对数据库带来了额外的安全风险 或 复杂性。
在 Oracle 23 中,可以对 Schema 进行授权,简化了之前的全线操作:
grant select any table on SCHMEA PROD to HR;

详情参考:Oracle Database 23c 十小新特性速览:从Schema权限到4096列支持
本文网址:https://www.eygle.com/archives/2022/09/oracle_database_23c_4096_columns.html
Oracle Database 23c新特性:无需DUAL表和FROM的SELECT快捷查询 27 Sep 2022 11:19 PM (3 years ago)
我们知道,在 MogDB 数据库中,SELECT 是可以不跟 FROM 子句实现一系列的查询功能,例如:
MogDB=#select 2^10;
?column?
----------
1024
(1 row)
MogDB=#select 9*9;
?column?
----------
81
(1 row)
在 Oracle 23c 中,第一次实现了不带From子句的查询,因而原来大量依赖 Dual 表的查询,可以松下了一口气。
现在 Oracle 开始支持 SELECT SYSDATE 直接返回结果:

在23c之前的版本中,DUAL 表是最常用的一个计算和常量返回的虚拟表:
SQL> select sysdate from dual;
SYSDATE
---------
28-SEP-22
SQL> select sysdate;
select sysdate
*
ERROR at line 1:
ORA-00923: FROM keyword not found where expected
详情参考:Oracle Database 23c 十小新特性速览:从Schema权限到4096列支持
本文网址:https://www.eygle.com/archives/2022/09/oracle_database_23c_without_dual.html
MacOS 使用终端连接 MySQL 查询乱码的问题解决 13 Mar 2022 10:46 PM (3 years ago)
最近在使用 MacOS 访问 MySQL 数据库时,查询总是出现乱码,数据库和表的字符集、终端设置都是 UTF8.
最后发现是 MacOS Terminal 的环境变量设置问题:
编辑配置文件
vim ~/.bash_profile
添加一样内容:
export LC_ALL=zh_CN.UTF-8
执行命令,使其生效:
source ~/.bash_profile
即可解决客户端的 Terminal 终端设置导致的乱码问题。
本文网址:https://www.eygle.com/archives/2022/03/macos_mysql_code.html
openGauss 概述 6 Dec 2021 11:35 PM (3 years ago)
本文来源于墨天轮:https://www.modb.pro/db/190317 openGauss数据库是华为公司在深度融合技术应用于数据库领域多年经验的基础上,结合企业级场景要求,推出的新一代企业级开源数据库。
openGauss是关系型数据库(relational database),采用客户端/服务器,单进程多线程架构;支持单机和一主多备部署方式,同时支持备机可读、双机高可用等特性。
openGauss有如下基本功能 :
(1) 支持标准SQL。
openGauss数据库支持标准的SQL(structured query language,结构化查询语言)。SQL标准是一个国际性的标准,会定期更新和演进。SQL标准的定义分为核心特性以及可选特性,绝大部分的数据库都没有100%支撑SQL标准。openGauss数据库支持SQL92/SQL99/SQL2003等,同时支持SQL2011大部分核心特性以及部分可选特性。
(2) 支持标准开发接口。
openGauss数据库提供业界标准的ODBC(open database connectivity,开放式数据库连接)及JDBC(java database connectivity,java数据库连接)接口,保证用户能将业务快速迁移至openGauss。目前支持标准的ODBC3.5及JDBC4.0接口,其中ODBC能够支持CentOS、openEuler、SUSE、Win32、Win64等平台,JDBC无平台差异。
(3) 支持混合存储引擎。
openGauss数据库支持行存储引擎、列存储引擎和内存存储引擎等。行存储分为inplace update和append update两种模式,前者通过单独的回滚段(undo log)来保留元组的前像以解决读写冲突,可以更自然地支持数据更新;后者将更新记录混杂在数据记录中,通过新旧版本的形式来支持数据更新,对于旧版本需要定期做vacuum操作来支持磁盘空间的回收。列存储支持数据快速分析,更适合OLAP(online analytical processing,联机分析处理)业务。内存引擎支持实时数据处理,对有极致性能要求的业务提供支撑。
(4) 支持事务。
事务支持指的是系统提供事务的能力,openGauss支持事务的原子性、一致性、隔离性和持久性。事务支持及数据一致性保证是绝大多数数据库的基本功能,只有支持了事务,才能满足事务化的应用需求。
A(atomicity): 原子性。整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。
C(consistency): 一致性。事务需要保证从一个执行性状态转移到另一个一致性状态,不能违反数据库的一致性约束。
I(isolation): 隔离性。隔离事务的执行状态,使它们好像是系统在给定时间内执行的唯一操作。例如有两个事务并发执行,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。
D(durability): 持久性。在事务提交以后,该事务对数据库所做的更改便持久地保存在数据库之中,不会因掉电、进程异常故障而丢失。 openGauss数据库支持事务的隔离级别有读已提交和可重复读,默认隔离级别是读已提交,保证不会读到脏数据。 事务分为隐式事务和显式事务。显式事务的相关基础接口如下。
Start transaction:事务开启。
Commit:事务提交。
Rollback:事务回滚。
另有用户还可以通过set transaction命令设置事务的隔离级别、读写模式或可推迟模式。
(5) 软硬结合。
openGauss数据库支持软硬件地结合,包括多核地并发访问控制、基于SSD(solid-state drive,固态硬盘)地I/O(input/output,输入/输出)优化、智能地buffer pool(缓冲池)数据管理。
(6) 智能优化器。
openGauss数据库提供了智能的代价模型、智能计划选择,可以显著提升数据库性能。openGauss的执行器包含了向量化执行和LLVM(low level virtual machine,底层虚拟机,一种构架编译器的框架系统)编译执行,可以显著提升数据库性能。
(7) 支持AI。
传统数据库生态依赖于DBA(database administrator,数据库管理员)进行数据地管理、维护、监控、优化。但是在大量的数据库实例中,DBA难以支持海量实例,而AI(artificial intelligence,人工智能)则可以自动优化数据库,openGauss数据库的AI功能包括AI自调优、AI索引推荐、AI慢SQL诊断等。
(8) 支持安全。
openGauss数据库具有非常好的安全特性,包括透明加密(在磁盘的存储文件是加密的)、全密态(数据传输、存储、计算都是加密的)、防篡改(用户不可篡改)、敏感数据智能发现等。
(9) 支持函数和存储过程。
函数和存储过程是数据库中的一种重要对象,主要功能是将用户特定功能的SQL语句集进行封装并方便调用。存储过程是SQL、PL(procedural language SQL,过程语言SQL)/SQL的组合。存储过程可以使执行商业规则的代码从应用程序中移动到数据库,从而实现代码存储一次但能够被多个程序使用。
允许客户模块化程序设计,对SQL语句集进行封装,调用方便。 存储过程会进行编译缓存,可以提升用户执行SQL语句集的速度。 系统管理员通过对执行某一存储过程的权限进行限制,能够实现对相应数据访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。 为了处理SQL语句,存储过程分配一段内存区域来保存上下文。游标是指向上下文区域的句柄或指针。借助游标,存储过程可以控制上下文区域的变化。 支持6种异常信息级别方便客户对存储过程进行调试,支持设置断点和单步调试。存储过程调试是一种调试手段,可以在存储过程开发中,一步一步跟踪存储过程执行的流程,根据变量的值,找到错误的原因或者程序的bug,提高问题定位效率。 openGauss支持SQL标准中的函数及存储过程,增强了存储过程的易用性。
(10) 兼容PostgreSQL接口。
openGauss数据库兼容PSQL客户端,兼容PostgreSQL标准接口。
(11) 支持SQL hint。
openGauss数据库支持SQL hint(hint是SQL语句的注释,可以指导优化器选择人为指定的执行计划),影响执行计划生成,提升SQL查询性能。Plan Hint为用户提供了直接影响执行计划生成的手段,用户可以通过指定join顺序、join方法、Scan方法、结果行数等多个手段进行执行计划的调优,以提升查询性能。
(12)支持Copy接口容错机制。
openGauss数据库中,用户可以使用封装好的函数创建Copy错误表,并能在使用Copy From语句时指定容错选项。指定容错选项后,openGauss数据库在执行Copy From语句过程中不会因"部分解析"、"数据格式"、"字符集"等相关的报错中断事务,而是把这些报错信息记录至错误表中,从而使得Copy From的目标文件即使有少量数据错误也可以完成入库操作。用户随后可以在错误表中对相关的错误进行定位以及进一步排查。
本文网址:https://www.eygle.com/archives/2021/12/opengauss_11.html
openGauss 云安全技术 2 Dec 2021 5:02 PM (3 years ago)
本文来源于墨天轮:https://www.modb.pro/db/185758
数据库最重要的作用是存储数据和处理分析数据。数据是整个数据库系统中最关键的资产。因此在保护系统不受侵害的基础上最为重要的任务就是保护数据的安全。常见的数据安全技术包括数据加密、数据脱敏(Data Masking)、透明加密(Transparent Data Encryption,TDE)和全程加密(Always Encryption)技术。这里囊括了数据的动态流程和静态存储行为。
一、数据加密算法
数据加解密是防止数据隐私泄露最为常见也最为有效的手段之一。数据在经过加密后以密文形式存放在指定的目录下。加密的意义在于,通过一系列复杂的迭代计算,将原本的明文转换为随机的没有任何具体含义的字符串,即密文。当所使用的加密算法足够安全时,攻击者在有限的计算资源下将很难根据密文获取到明文信息。
常见的加密算法可分为对称加密算法和非对称算法。其中最为著名的非对称加密算法叫RSA算法,其密钥长度须达到3072才可以保证其安全性,即强安全。常见的对称加密算法为AES算法,如AES128和AES256。相比于非对称加密算法,对称加密算法运算速度快,密文长度增长少,安全性容易证明,所需要的密钥长度短,但也存在密钥分发困难,不可以用于数字签名等缺点。除了上述介绍的加密算法外,还有很多其他强安全算法,在此不一一介绍。下面将重点介绍openGauss中所支持的数据加密能力。
首先openGauss在内核定义了数据加解密的函数,并对外提供了数据加解密的接口,函数接口为:
gsencryptaes128(text, initial_value);
其中,text为需要加密的明文数据,initial_value为生成密钥时需要的初始化向量。该函数可以被灵活的应用在SQL语法的各个地方。如通过使用INSERT语法插入数据或者查询数据时均可以绑定该函数对数据进行加密处理,具体如下:
SELECT * FROM gsencryptaes128(tbl.col, '1234');
通过该查询,用户可以直接返回表tbl中的col列的密文信息。
与加密函数相对应的是解密函数,其接口格式定义为:
gsdecryptaes128(cypertext, initial_value);
其中cypertext为加密之后的密文,initial_value需要为与加密时所采用的相同的值才可以。否则使用该函数也无法得到正确明文。
除了基本的数据加解密接口外,openGauss还在多个特性功能里提供了数据加解密功能。其中第一个提供加解密功能的特性是数据导入导出;第二个提供加解密功能的特性是数据库备份恢复。
二、数据脱敏技术
在很多应用场景下,用户需要通过拥有表中某一列的访问权来执行任务,但是又不能获取所做事务之外其他的权限。以快递人员举例,快递人员在递送包裹的时候需要知道收件人的联系方式和姓氏,但是无需知道对应的收件人的全称。在快递收件人信息部分,如果同时定义了收件人的姓名和电话,则暴露了收件人的隐私信息,"有心之人"可以通过此信息进行虚假信息构造或利用该隐私信息进行财产欺诈。因此在很多情况下,所定义的敏感信息是不建议对外展现的。
数据脱敏是解决此类问题的最有效方法之一,通过对敏感数据信息的部分信息或全量信息进行特殊处理可以有效掩盖敏感数据信息的真实部分,从而达到保护数据隐私信息的目的。数据脱敏按照脱敏呈现的时机可以分为数据动态脱敏和数据静态脱敏,其中前者在数据运行时对数据进行特殊处理,后者在数据存储的时候进行特殊处理以防止攻击者通过提取数据文件来直接获取敏感信息。在本文中,将重点介绍数据动态脱敏技术。
数据动态脱敏的安全意义在于:
用户在实际操作的时候无需真实数据只需要使用一个变化后的数据进行操作,可有效规避数据信息的直接暴露。 在不同的国家及地区的法律合规中,如GDPR,约定不同的用户在管理数据的时候具有不同的访问对象权限。 对于表中的同一列数据信息,不同的用户应具有不同的用途。
数据动态脱敏功能在数据库内核实际上表现为数据处理函数。通过函数处理使得数据库中的数据在返回给实际查询用户时数据值发生变更,如用户所有的年龄信息值在返回给客户端时均显示为"0";又或是字符串数据中的部分字节位变更为其他字符,如信用卡卡号"1234 5678 0910 1112"在返回给客户端时显示为"XXXX XXXX XXXX 1112"。
在openGauss系统中,数据动态脱敏策略的语法定义如下所示:
CREATE MASKINGPOLICY policyname
(
(masking_clause)
[filter_clause]
[ENABLE|DISABLE]
); 其中具体的参数说明如下:
- maskingclause语法定义如下: MASKINGFUNCTION(PARAMETERS) ON (SCOPE(FQDN)) | (LABEL(resourcelabelname)) [, ...]*;
定义了针对不同数据集合对象所采用的脱敏函数。这里LABEL为数据库安全标签,数据库安全标签实际上定义了一组数据内部的表对象或表中的部分列,用于标记相应数据脱敏策略的范围。
- filterclause语法定义如下: FILTER ON FILTERTYPE(filter_value [, ...]) [, ...];
定义了数据动态脱敏策略所支持的过滤条件。
一个实际的数据动态脱敏案例如下:
CREATE MASKINGPOLICY mymasking_policy
creditcardmasking ON LABEL (mask_credcard),
maskall ON LABEL (mask_all)
FILTER ON IP(local), ROLES(dev);
其中,mymaskpolidy为定义的数据动态脱敏策略名字;creditcardmasking以及maskall为定义的masking处理函数,分别用于处理从属于maskcredcard对象集合和maskall对象集合;maskcredcard和maskall代表不同的Label对象,这些Label对象名称将作为唯一标识记录在系统表中。FILTER表示当前动态脱敏策略所支持的连接源,连接源指的是实际数据库管理员使用何种用户,从何IP源位置发起,使用何种APP应用来访问当前的数据库。通过使用FILTER可以有效定义系统的访问源信息,并规避不应该访问当前系统的行为。
openGauss在系统内部预定义了七种数据脱敏策略。具体如下表所示:
数据脱敏策略

用户在实际使用时,还可以根据自己的需求自行定义数据脱敏策略。
三、透明加密技术
当数据在静态存储状态时,除了使用常见的静态脱敏进行数据隐私保护外。另外一种行之有效的方法是透明加密(TDE)。事实上,静态脱敏在实际应用过程中是存在一定的限制的。用户并不能对所有的数据类型都施加静态脱敏措施。
数据透明加密从加密策略出发,即使用户数据被导出,也可以有效解决数据信息泄露风险。数据透明加密的初衷是为了防止第三方人员绕过数据库认证机制,直接读取数据文件中的数据(数据文件中的数据虽然是二进制数据,但是仍然是明文存放)。所以对数据库的数据文件进行加密后,必须在数据库启动后,用户通过正常途径连接数据库,才可以读取解密后的数据,达到数据保护的目的。
openGauss实施透明加密策略,首先是需要确定一个数据库密钥(Database Encryption Key,DEK),该DEK由系统密钥管理系统(Key Management Service,KMS)生成,数据库密钥密文(Encrypted Database Encryption Key,EDEK)以文件方式(gstdekeys.cipher)存储于数据库系统中。该DEK一次生成,终身使用,不可变更,不可轮换。在快照(即备份)恢复时,需要使用此前的DEK。
数据库节点在每次启动时,通过读取本地存储的密钥信息和密钥密文(EDEK),向KMS机器上的URL地址,传入密钥版本名(version-name),密钥名(name),IV值和数据库加密密钥密文值,从而获取到解密后的数据库加密密钥DEK。此密钥会缓存在节点的内存当中,当数据库需要加解密数据时从内存中拷贝密钥明文。
openGauss支持两种格式的透明加密算法,通过GUC参数transparentencryptionalgo来进行控制,当前支持的算法包括AES-CTR-128和SM4-CTR-128。加密模式选用CTR(CounTeR,计数器模式)的原因是CTR流加密可以保证明文和密文长度相等。明文和密文长度相等是由数据块(Block)的大小决定的,因为内存和磁盘存储格式对Block的大小是有要求的(默认8K)。特别的,在openGauss列存储中,列存储单元(Column Unit,CU)的最大大小是有限制的,所以也不能存在加密后长度超过最大限制。
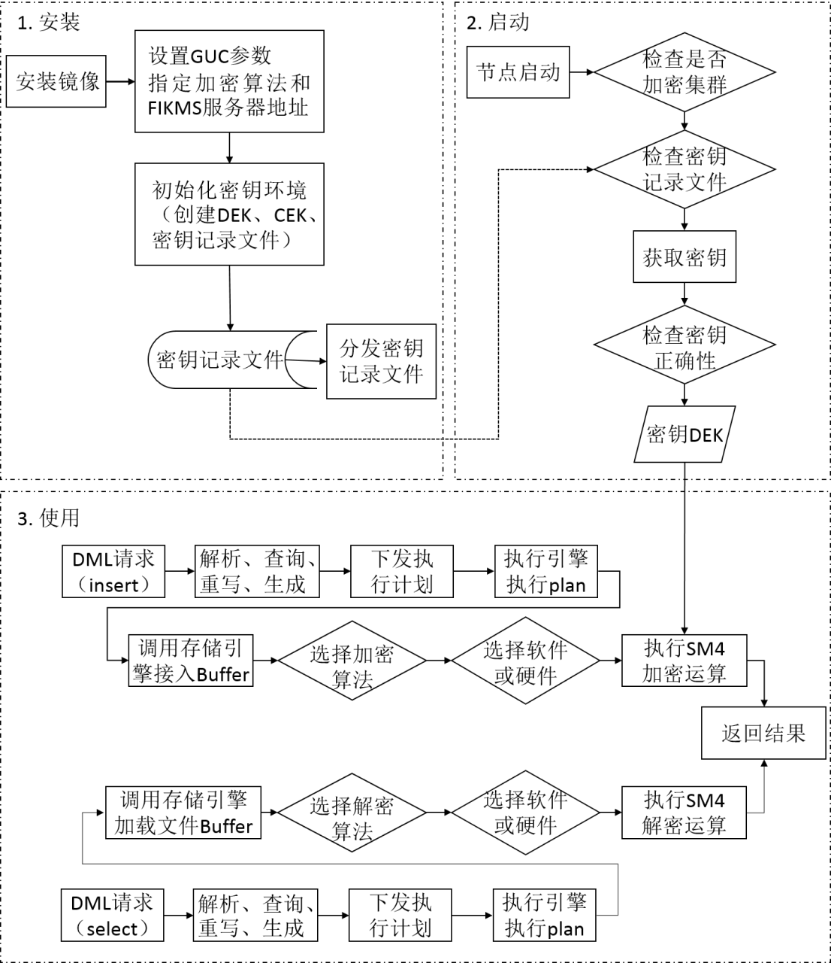
一个完整的透明加密流程如下图所示。即该特性的生命周期共分为3个阶段:安装阶段、启动阶段和使用阶段。
安装阶段用户通过安装部署的配置,生成密钥记录文件和GUC参数。
启动阶段依据密钥记录文件和GUC参数,获取到明文。
使用阶段用户根据密钥算法标记和全局缓存明文,完成数据落盘的加密和数据读取的解密。
四、全程加密技术
无论是当前通用数据脱敏方案,还是数据透明加密方案,其所解决的都是部分状态或部分流程下的数据隐私安全。数据库攻击者可通过其他不同的攻击技术手段在数据以明文存在的阶段或处于内存中的时候抓取数据流信息,从而达到获取数据隐私数据的目的。如果数据在整个生命周期过程中都能够处于加密的形态,且密钥掌握在用户自己手中。则数据库用户可有效的防止数据隐私安全泄露。
全程加密技术就是在这种场景下诞生的。其核心是使得数据从用户手中进入到数据库系统后一直处于加密状态,用户所关心的数据分析过程也在密态状态下完成。在整个数据分析处理过程中,即使用户数据被攻击者窃取,由于密钥一直掌握在客户自己手中,攻击者也无法获得相关的信息。目前该技术处于研发阶段,对应产品尚未向客户发布。
openGauss数据库分成三个阶段来实现完整的全程加密功能。
第一阶段是客户端全程加密能力,系统在客户端提供数据加解密模块和密钥管理模块,在这种设计思路下数据在客户端完成加密后进入数据库,在完成处理分析返回结果的时候在客户端完成解密功能,客户端全程加密的缺陷在于只能支持等值类查询。
在第二阶段,将在服务端实现基于密文场景的密文查询和密文检索能力,使得数据库具备更加强大的处理能力。
第三阶段openGauss将构建基于可信硬件的可信计算能力。在此我们将基于鲲鹏芯片来构建数据库的可信计算能力。在可信硬件中,完成对数据的解密和计算。数据从可信硬件进入到真实世界后,将再加密成密文返回给客户。 一个完整的openGauss数据库全程加密方案架构如图所示。
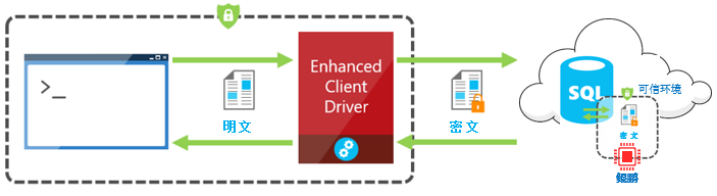
首先来介绍openGauss客户端全程加密方案,我们也称之为客户端列加密方案(Client Column Encryption,CCE)。在该方案中,首先应该由用户来指定对哪一列数据进行加密,通过在指定的属性列后面加上关键字"encrypted"来进行标记,如下述语法所示:
CREATE TABLE test_encrypt(creditcard varchar(19) encrypted);
为了有效保证加密数据的安全性并支持数据的密态查询,在内核中我们选用确定性AES算法,具体来说其加密算法为:
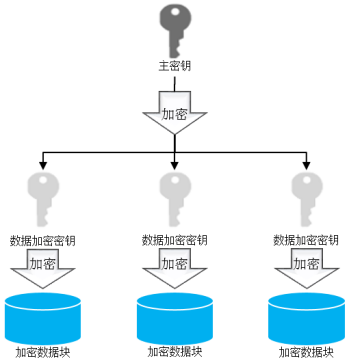
AEADAES256CBCHMACSHA256。整个方案中使用双层密钥方案,第一层根密钥用户向密钥管理中心获取,作为根密钥(master key)。第二层为数据加密密钥,也称之为工作密钥。工作密钥通过根密钥加密后存放在服务器端。在加密列创建完成后,如果没有工作密钥,则系统会单独为该列创建一个工作密钥。不同的属性列可以通过创建语法指定并共享列加密密钥。
为保证整个系统的安全性,加密工作密钥的加密算法强度应高于使用工作密钥加密数据的强度。在openGauss数据库中,我们使用RSA-OAEP算法来加密工作密钥,而根密钥仅存放在客户端。密钥层次关系如图所示。
由于采用确定性加密算法,对于相同的明文,所获取的密文也是相同的。在这种机制下,客户端全程加密可有效的支持等值查询,我们只需要将对应的查询条件中的参数按照对应属性列的加密算法进行加密,并传给服务端即可。一个完整的客户端全程加密逻辑流程如图所示。在流程图的客户端部分,我们需要优先检查相关信息的有效性。
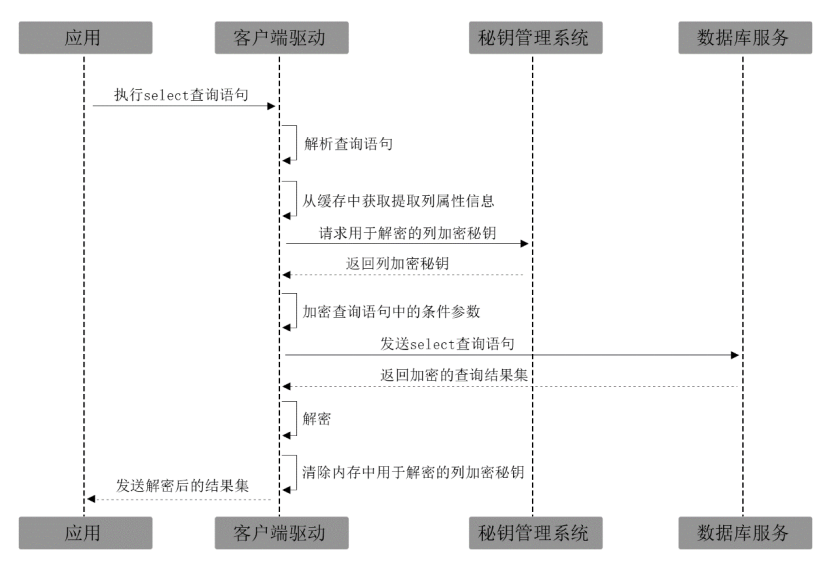 客户端全程加密方案是非常简单易懂的,通过确定加密机制保障结果的正确性和完整性。但对于日益复杂的查询任务来说,客户端全程加密方案是远远不够的。因为客户端全程加密仅仅能满足那些等值查询的查询任务,如等值条件查询、分组、连接操作等等。对于那些更为复杂的数据搜索,比较查询、范围查询等等,则需要更为复杂的密态查询算法或服务端可信硬件方案。
客户端全程加密方案是非常简单易懂的,通过确定加密机制保障结果的正确性和完整性。但对于日益复杂的查询任务来说,客户端全程加密方案是远远不够的。因为客户端全程加密仅仅能满足那些等值查询的查询任务,如等值条件查询、分组、连接操作等等。对于那些更为复杂的数据搜索,比较查询、范围查询等等,则需要更为复杂的密态查询算法或服务端可信硬件方案。
事实上,密文查询算法和检索算法在学术界一直都是热点的研究方向,如OPE(Order Preserve Encryption)/ORE(Order Reveal Encryption)算法、SSE(Symmetric Searchable Encryption)算法等。openGauss将针对排序、范围查询、模糊检索实现纯软件态的密文查询和密文检索。纯软方案的缺陷在于由于在密文状态下进行运算,会导致系统整体性能变慢。为了支持密态计算,需要密文在计算完成后解密的结果与明文计算所获得的结果相同。全同态加密是最行之有效的算法,可有效解决数据在密文形态下的加法和乘法计算,而不暴露相关明文信息。但是全同态加密最大的问题在于其性能过于低效,以至于没有一款商业数据库支持该能力,哪怕是部分同态加密能力,如加法同态或者乘法同态。
在第三阶段,openGauss将提供基于可信硬件的密态计算能力。其核心是数据以密文形态进入服务端可信硬件中并完成所需要的密文计算。可信硬件将系统内核分为安全世界和非安全世界。数据计算完成后再以密文形态返回给非安全世界,并最终返回给客户端。目前通用的Intel芯片和ARM芯片均提供了相类似的功能。在Intel芯片中,该隔离区域被称之为SGX(Software Guard Extensions)。SGX是一个被物理隔离的区域,数据即使以明文形式存放在该物理区域内,攻击者也无法访问。在ARM架构中,与其类似的功能被称之为Trust Zone,基于Trust Zone,人们可以构建可信操作系统(Trusted OS),然后可以开发相对应的可信应用。基于可信计算环境,用户可以解密这些数据进行各类数据库查询操作。当数据离开这些环境后,数据则以密文形态存在,并返回给客户再进行解密。从而起到保护数据隐私的目的。
本文网址:https://www.eygle.com/archives/2021/12/opengauss_10.html
MacOS Monterey在腾讯会议声音不起作用coreaudiod重置 29 Nov 2021 4:10 PM (3 years ago)
最近总是遇到腾讯会议启动,电脑的音频失效情况。经验值,以下重启 coreaudiod 的逻辑有效。
MacOS Monterey 的系统。
启动终端并输入以下命令:
sudo killall coreaudiod按Return ,输入您的管理员密码,然后再次检查声音。 coreaudiod进程应该重新启动。
在极少数情况下,可能还存在听不到声音的问题。可以尝试以下命令:
sudo launchctl start com.apple.audio.coreaudiodlaunchctl命令启动守护进程并重新初始化coreaudiod进程。
在我的情况下,通过第一个命令,声音得到了恢复。
本文网址:https://www.eygle.com/archives/2021/11/macos_montereyc.html
openGauss 分布式事务 24 Nov 2021 9:52 PM (3 years ago)
前面我们简要介绍了单机事务和分布式事务的区别,也指出了在分布式情况下,可能存在特有的原子性和一致性问题。本文主要介绍在openGauss数据库中,如何保证分布式事务的原子性和强一致性。
1 分布式事务原子性和两阶段提交协议
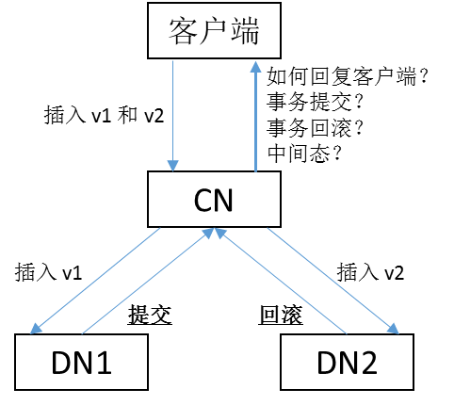
为了保证分布式事务的原子性,防止出现如图10-2中所示的部分DN提交、部分DN回滚的"中间态"事务,openGauss采用两阶段提交(2PC)协议。
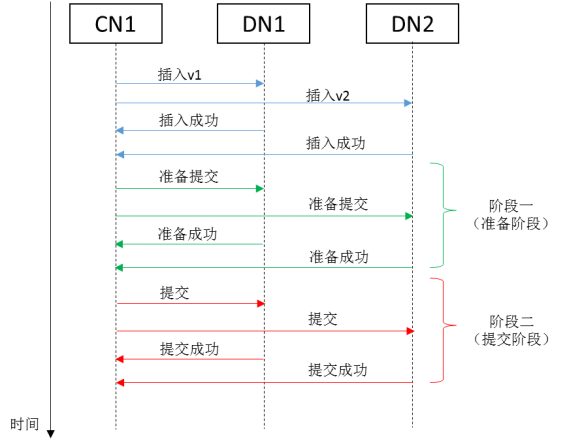
如上图所示,顾名思义,两阶段提交协议将事务的提交操作分为两个阶段:
阶段一,准备阶段(prepare phase),在这个阶段,将所有提交操作所需要使用到的信息和资源全部写入磁盘,完成持久化;
阶段二,提交阶段(commit prepared phase),根据之前准备好的提交信息和资源,执行提交或回滚操作。 两阶段提交协议之所以能够保证分布式事务原子性的关键在于:一旦准备阶段执行成功,那么提交需要的所有信息都完成持久化下盘,即使后续提交阶段某个DN发生执行错误,该DN可以再次从持久化的提交信息中尝试提交,直至提交成功。最终该分布式事务在所有DN上的状态一定是相同的,要么所有DN都提交,要么所有DN都回滚。因此,对外来说,该事务的状态变化是原子的。
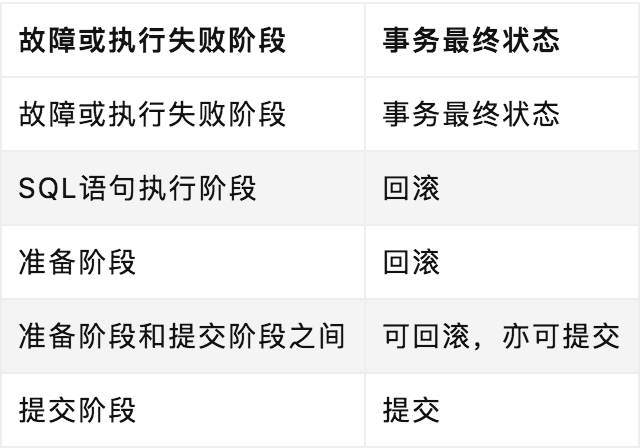
下表总结了在openGauss分布式事务中的不同阶段,如果发生故障或执行失败,分布式事务的最终提交/回滚状态,读者可自行推演,本文不再赘述。
发生故障或执行失败时事务的最终状态
2 分布式事务一致性和全局事务管理
为了防止瞬时不一致现象,支持分布式事务的强一致性,我们需要全局范围内的事务号和快照,以保证全局MVCC和快照的一致性。在openGauss中,GTM负责提供和分发全局的事务号和快照。对于任何一个读事务,其都需要到GTM上获取全局快照;对于任何一个写事务,其都需要到GTM上获取全局事务号。
为了防止瞬时不一致现象,支持分布式事务的强一致性,我们需要全局范围内的事务号和快照,以保证全局MVCC和快照的一致性。在openGauss中,GTM负责提供和分发全局的事务号和快照。对于任何一个读事务,其都需要到GTM上获取全局快照;对于任何一个写事务,其都需要到GTM上获取全局事务号。
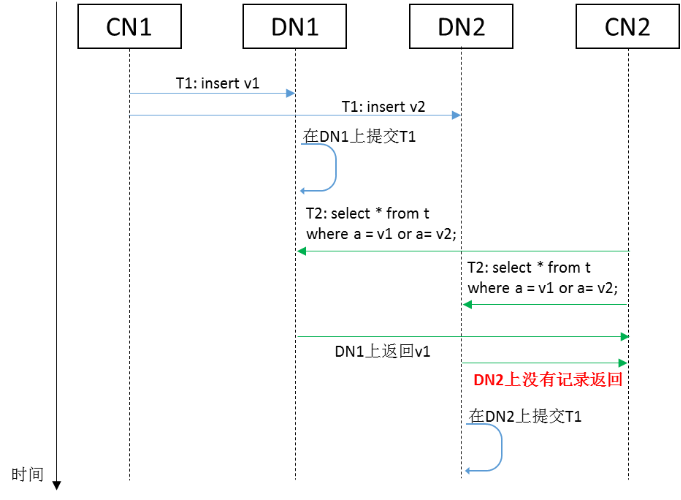
在上图中加入GTM,并考虑两阶段提交流程之后,分布式读-写并发事务的流程如下图所示。对于读事务来说,由于写事务在其从GTM获取的快照中,因此即使写事务在不同DN上的提交顺序和读事务的执行顺序不同,也不会造成不一致的可见性判断和不一致的读取结果。
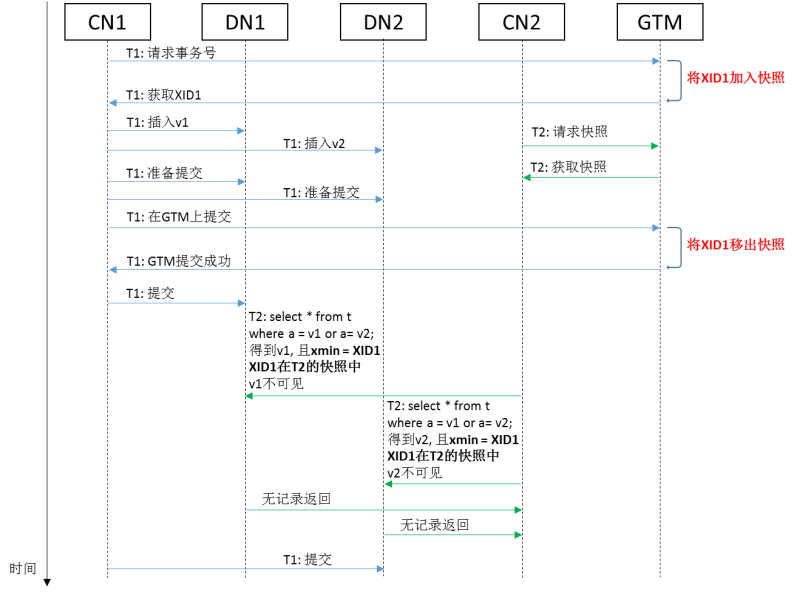
细心的读者会发现,在上图的两阶段提交流程中,写事务T1在各个DN上完成准备阶段之后,首先第一步是到GTM上结束T1事务(将T1从全局快照中移除),然后第二步再到各个DN上进行提交阶段。在这种情况下,如果查询事务T2是在第一步和第二步之间在GTM上获取快照,并到各个DN上执行查询的话,那么T2事务读到的T1事务插入的记录v1和v2,它们xmin对应的XID1已经不在T2事务获取到的全局快照中,因此v1和v2的可见性判断会完全基于T1事务的提交状态。然而,此时XID1对应的T1事务在各个DN上可能还没有全部或部分完成提交阶段,那么就会出现各个DN上可见性不一致的情况。
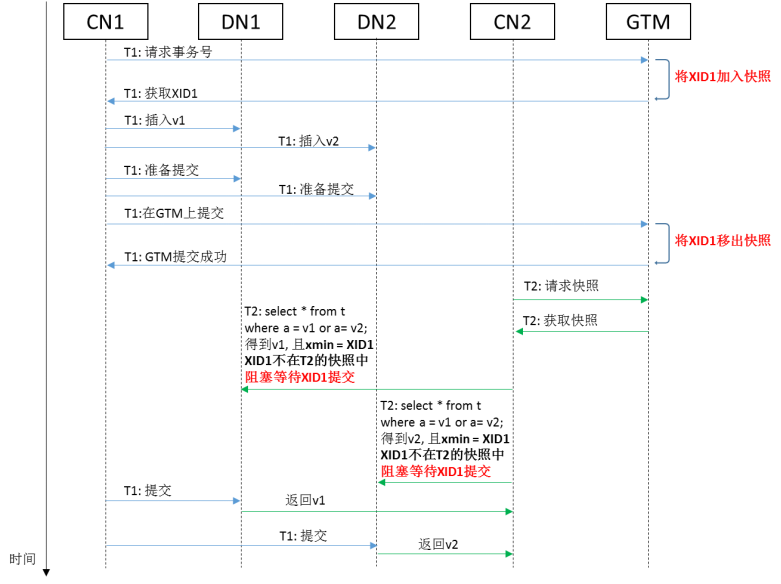
为了防止上面这种问题出现,在openGauss中采用本地二阶段事务补偿机制。如下图所示,对于在DN上读取到的记录,如果其xmin或者xmax已经不在快照中,但是它们对应的写事务还在准备阶段,那么查询事务将会等到这些写事务在DN本地完成提交阶段之后,再进行可见性判断。考虑到通过两阶段提交协议,可以保证各个DN上事务最终的提交或回滚状态一定是一致的,因此在这种情况下各个DN上记录的可见性判断也一定是一致的。
3 小结
本文主要结合openGauss数据库的事务机制和实现原理,基于显式事务和隐式事务,介绍事务块状态机的变化,以及openGauss事务ACID特性的实现方式。尤其的,对于分布式场景下的事务原子性和一致性问题,介绍openGauss采取的多种解决技术方案,以保证数据库最终对外呈现的ACID不受分布式执行框架的影响。
本文网址:https://www.eygle.com/archives/2021/11/opengauss_9.html
openGauss 数据库并发控制 23 Nov 2021 11:17 PM (3 years ago)
文章来源于墨天轮:https://www.modb.pro/db/174555
当数据库中存在并发执行事务的情况下,要保证ACID特性,需要一些特殊的机制来支持。并发控制就是指这样的一种控制机制,能够保证并发事务同时访问同一个对象或数据下的ACID特性。
openGauss并发控制是十分高效的,其核心是MVCC和快照机制。如前文中所述,通过使用MVCC和快照,可以有效解决读写冲突,使得并发的读事务和写事务工作在同一条元组的不同版本上,彼此不会相互阻塞。对于并发的两个写事务,openGauss通过事务级别的锁机制(事务执行过程中持锁,事务提交时释放),来保证写事务的一致性和隔离性。
另一方面,对于底层数据的访问和修改,如物理页面和元组,为了保证读写操作的原子性,需要在每次的读、写操作期间加上共享锁或排他锁。当每次读、写操作完成之后,即可释放上述锁资源,无需等待事务提交,持锁窗口相对较短。
1 读-读并发控制
在绝大多数情况下,并发的读-读事务,是不会、也没有必要相互阻塞的。由于没有修改数据库,因此每个读事务使用自己的快照,就能保证查询结果的一致性和隔离性;同时,对于底层的页面和元组,只涉及读操作,只需要对它们加共享锁即可,不会发生锁等待的情况。
一个比较特殊的情况是执行SELECT FOR UPDATE查询。该查询会对所查到的每条记录在元组层面加排他锁,以防止在查询完成之后,查询结果集被后续其它写事务修改。该语句获取到的元组排他锁,在事务提交时才会释放。对于并发的SELECT FOR UPDATE事务,如果它们的查询结果集有交集,那么在交集中的元组上会发生锁冲突和锁等待。
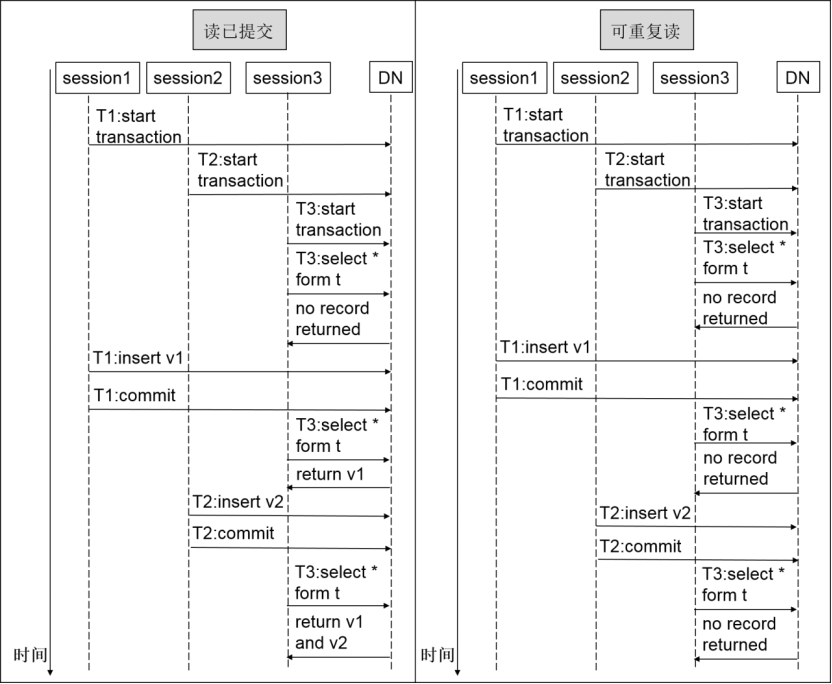
2 读-写并发控制
如下图的例子所示,openGauss中对于读、写事务的并发控制基于MVCC和快照机制,彼此之间不会存在事务级的长时间阻塞。相比之下,采用两阶段锁协议(Two-Phase Locking Protocol,简称2PL协议)的并发控制(如IBM DB2数据库),由于读、写均在记录的同一个版本上操作,因此排在锁等待队列后面的事务至少要阻塞到持锁者事务提交之后才能继续执行。
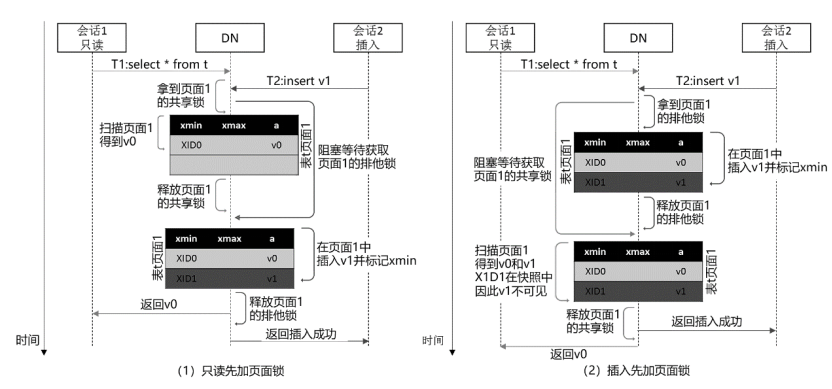
另一方面,为了保证底层物理页面和元组的读、写原子性,在实际操作页面和元组时,需要暂时加上相应对象的共享锁或排他锁,在完成对象的读、写操作之后,就可以放锁。
对于所有可能的三种读-写并发场景,即查询-插入并发、查询-删除并发和查询-更新并发,在下面图1、图2和图3中分别给出了它们的并发控制示意图。
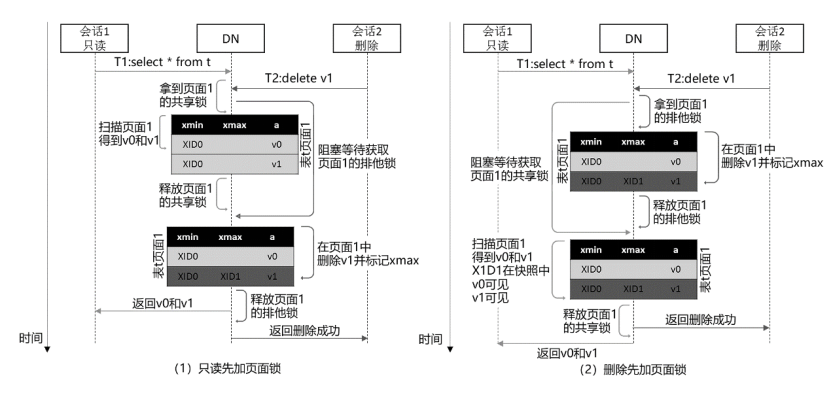
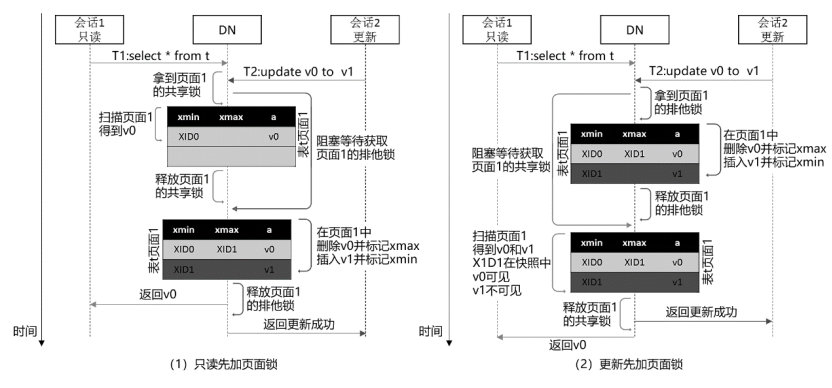
3 写-写并发控制
虽然通过MVCC,可以让并发的读-写事务工作在同一条记录的不同版本上(读老版本,写新版本),从而互不阻塞,但是对于并发的写-写事务,它们都必须工作在最新版本的元组上,因此如果并发的写-写事务涉及同一条记录的写操作,那么必然导致事务级的阻塞。
写-写并发的场景有以下6种:插入-插入并发、插入-删除并发、插入-更新并发、删除-删除并发、删除-更新并发、更新-更新并发。下面就插入-插入并发、删除-删除并发和更新-更新并发的控制流程做简要描述,另外三种并发场景下的控制流程供读者自行思考。
图4为插入-插入事务的并发控制流程图。对于每个插入事务,它们都会在表的物理页面中插入一条新元组,因此并不会在同一条元组上发生并发写冲突。然而,当表具有唯一索引时,为了避免违反唯一性约束,若并发插入-插入事务在唯一键上有冲突(即键值重复),后来的插入事务必须等待先来的插入事务提交以后,再根据先来插入事务的提交结果,才能进一步判断是否能够继续执行插入操作。如果先来插入事务提交了,那么后来插入事务必须回滚,以防止唯一键重复;如果先来插入事务回滚了,那么后来插入事务可以继续插入该键值的记录。
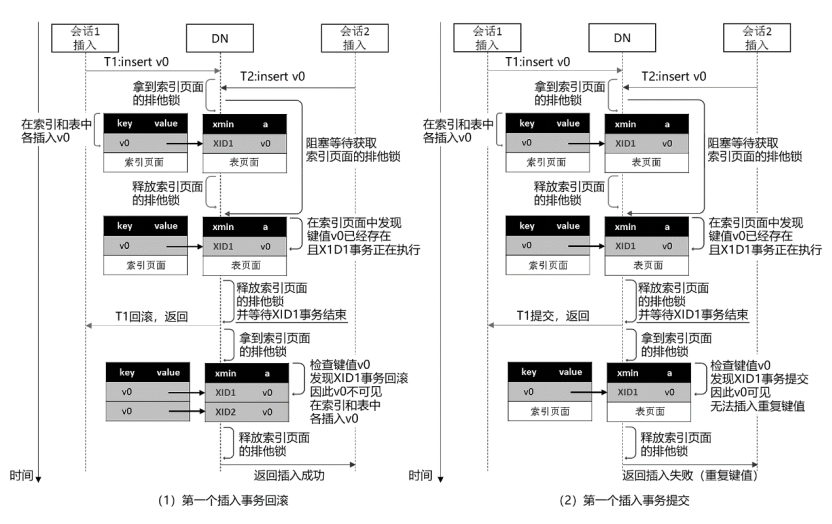
图5为删除-删除事务的并发控制流程图。对于并发的删除-删除事务,它们都会尝试去修改同一条元组的xmax值。我们通过页面排他锁来控制该冲突。对于后加上锁的删除事务,它在再次标记元组xmax值之前,首先需要判断先来删除事务(即元组当前xmax事务号对应的事务)的提交结果。如果先来删除事务提交了,那么该元组对后来删除事务不可见,后来删除事务无元组需要删除;如果先来删除事务回滚了,那么该元组对后来删除事务依然可见,后来删除事务可以继续执行对该元组的删除操作。
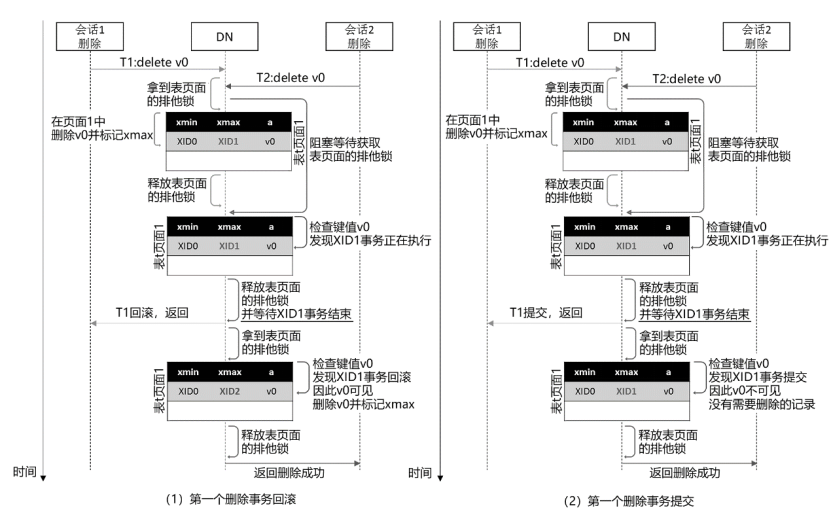
图6为更新-更新事务的并发控制流程图。对于并发的更新-更新事务,与并发删除-删除事务类似,它们首先都会尝试去修改同一条元组的xmax值。我们通过页面排他锁来控制该冲突。对于后加上锁的更新事务,它在再次标记元组xmax值之前,首先需要判断先来更新事务(即元组当前xmax事务号对应的事务)的提交结果。如果先来更新事务提交了,那么该元组对后来更新事务不可见,此时,后来更新事务会去判断该元组更新后的值(先来更新事务插入)是否还符合后来更新事务的谓词条件(即删除范围),如果符合,那么后来的更新事务会在这条新的元组上进行更新操作,如果不符合,那么后来的更新事务无元组需要更新;如果先来更新事务回滚了,那么该元组对后来更新事务依然可见,后来更新事务可以继续在该元组上进行更新操作。
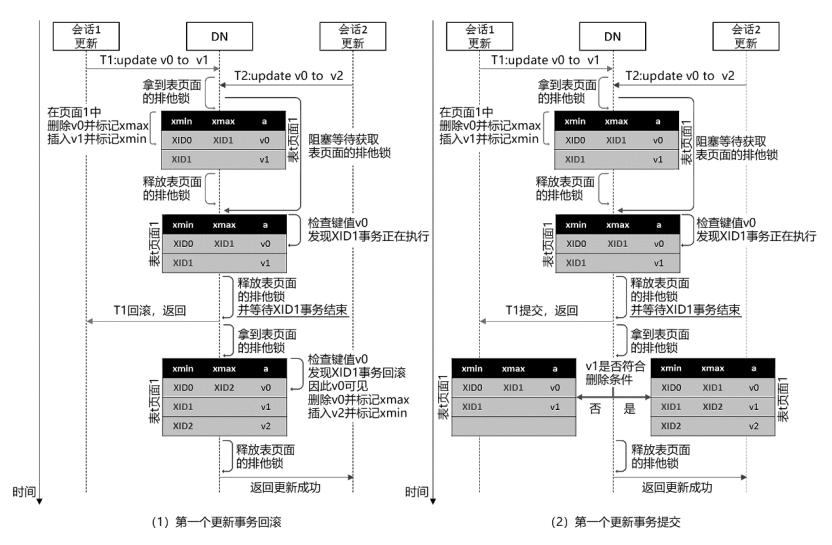
4 并发控制和隔离级别
在上文中介绍写-写并发控制的机制时,其实默认了使用读已提交的隔离级别。回顾图4、图5和图6,我们可以发现,当在某条元组上发生并发写-写冲突时,原本先来事务是在后来事务的快照中的,后来事务是不应该看到先来事务的提交结果的,但是为了解决上述冲突,后来事务会等待先来事务提交之后,再去校验先来事务对元组的操作结果。这种方式是符合读已提交隔离级别要求的,但是显然后来事务在等待之后,又刷新了自己的快照内容(将先来事务从快照中移除)。
基于上述原因,在MVCC和快照隔离的并发控制策略下,若使用可重复读的隔离级别,当发生上述写-写冲突时,后来事务不会再等待先来事务的提交结果,而是将直接报错回滚。这也是openGauss在可重复读隔离级别下,对于写-写冲突的处理模式。
进一步,如果要支持可串行化的隔离级别,对于使用MVCC和快照隔离的并发控制策略,需要解决写偏序(Write Skew)的异常现象,有兴趣的读者可以参考2008年SIGMOD最佳论文《Serializable Isolation for Snapshot Databases》。
5 对象属性的并发控制
在上面并发控制的介绍中,我们覆盖了DML和查询事务的并发控制机制。对于DDL语句,其虽然不涉及表数据元组的修改,但是其会修改表的结构(Schema),因此很多场景下不能和DML、查询并发执行。
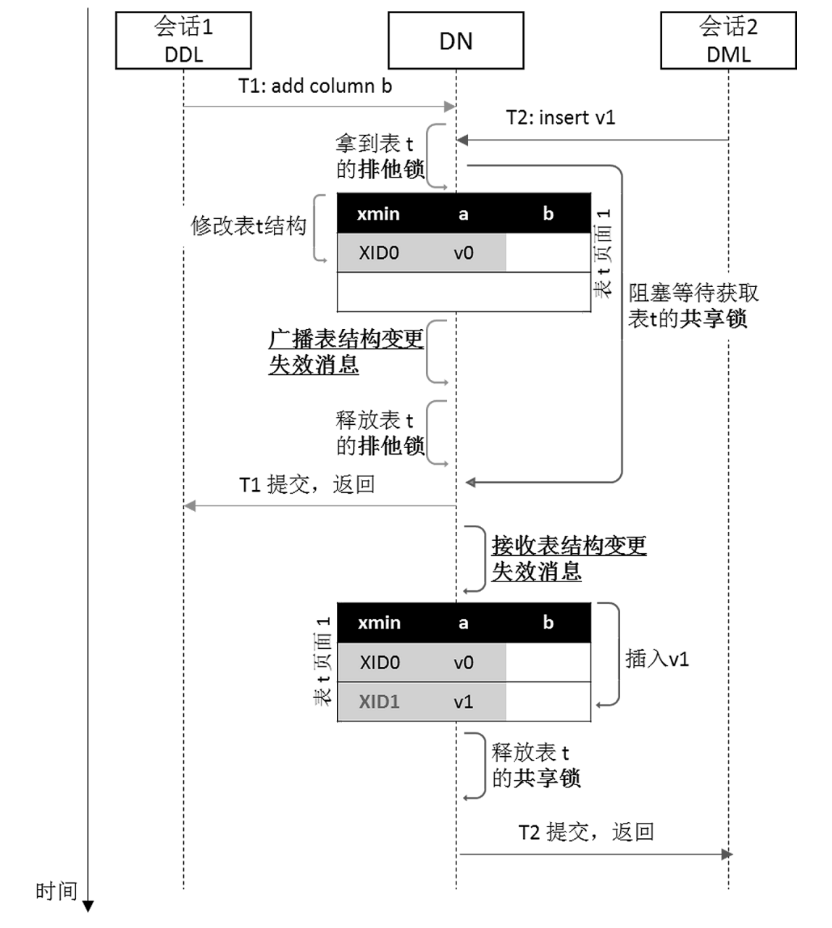
以增加字段的DDL事务和插入事务并发执行为例,它们的并发执行流程如图7所示。首先,DDL事务会获取表级的排他锁,而DML事务在执行之前,需要获取表级的共享锁。DDL事务持锁之后,会执行新增字段操作。然后,DDL事务会给其它所有并发事务发送表结构失效消息,告诉其它并发事务,这个表的结构被修改了。最后,DDL事务释放表级排他锁,提交返回。
DDL事务放锁之后,DML事务可以获取到该表的共享锁。加锁之后,DML事务首先需要处理所有在等锁过程中可能收到的表结构失效消息,并加载新的表结构信息。然后,DML才可以执行增删改操作,并提交返回。
6 表级锁、轻量锁和死锁检测
在前面,已经向读者初步介绍了在事务并发控制中,需要有锁机制的参与。事实上,在openGauss中,主要有两种类型的锁:表级锁和轻量锁。
表级锁主要用于提供各种类型语句对于表的上层访问控制。根据访问控制的排他性级别,表级锁分为1级到8级锁。对于两个表级锁(同一张表)的持有者,如果他们持有的表级锁的级别之和大于等于8级,那么这两个持有者的表级锁会相互阻塞。
在典型的数据库操作中,查询语句需要获取1级锁,DML语句需要获取3级锁,因此这两个操作在表级层面不会相互阻塞(这得益于MVCC和快照机制)。相比之下,DDL语句通常需要获取8级锁,因此对同一张表的DDL操作会和查询语句、DML语句相互阻塞。以修改表结构类型的DDL语句为代表,如果允许在该DDL执行过程中同时插入多条数据,那么前后插入的数据的字段个数可能不一致,甚至相同字段的类型亦可能出现不一致。
另一方面,在创建一个表的索引过程中,一般不允许有并发的DML操作,否则可能会导致索引不正确,或者需要引入复杂的并发索引修正机制。在openGauss中,创建索引语句需要对目标表获取5级锁,该锁级别和DML的3级锁会相互阻塞。
在openGauss中,为表级锁的所有等待者维护了等待队列信息。基于该等待队列,openGauss对于表级锁提供了死锁检测。死锁检测的基本原理是尝试在所有表级锁的等待队列中寻找是否存在能够构成环形等待队列的情况,如果存在环形等待队列,那么就表示可能发生了死锁,需要让其中某个等待者回滚事务退出队列,从而打破该环形等待队列。
在openGauss中,第二种广泛使用的锁是轻量锁。轻量锁只有共享和排他两种级别,并且没有等待队列和死锁检测。一般轻量锁并不对数据库用户提供,仅供数据库开发人员使用,需要开发人员自己来保证并发情况下不会发生死锁的场景。在本章中曾经介绍过的页面锁即是一种轻量锁,表级锁也是基于轻量锁来实现的。
墨天轮,围绕数据人的学习成长提供一站式的全面服务,打造集新闻资讯、在线问答、活动直播、在线课程、文档阅览、资源下载、知识分享及在线运维为一体的统一平台,持续促进数据领域的知识传播和技术创新。
本文网址:https://www.eygle.com/archives/2021/11/opengauss_8.html
openGauss 数据库事务概览 21 Nov 2021 5:25 PM (3 years ago)
本文来源于墨天轮:https://www.modb.pro/db/171689
事务是数据库为用户提供的最核心、最具吸引力的功能之一。简单地说,事务是用户定义的一系列数据库操作(如查询、插入、修改或删除等)的集合,数据库从内部保证了该操作集合(作为一个整体)的原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability),统称事务的ACID特性。其中:
A:原子性是指一个事务中的所有操作要么全部执行成功,要么全部执行失败。一个事务执行以后,数据库只可能处于上述两种状态之一。即使数据库在这些操作执行过程中发生故障,数据库也不会出现只有部分操作执行成功的状态。
C:一致性是指一个事务的执行会导致数据从一个一致的状态转移到另一个一致的状态,事务的执行不会违反一致性约束、触发器等定义的规则。
I:隔离性是指在一个事务的执行过程中,所看到的数据库状态受并发事务的影响程度。根据该影响程度的轻重,一般将事务的隔离级别分为读未提交、读已提交、可重复读和可串行化四个级别(受并发事务影响由重到轻)。
D:持久性是指一旦一个事务的提交以后,那么即使数据库发生故障重启,该事务的执行结果不会丢失,仍然对后续事务可见。
本文主要结合openGauss数据库的事务机制和实现原理,来阐述在openGauss是如何保证事务的ACID特性的。
openGauss是一个分布式的数据库。同样的,openGauss数据库的事务机制也是一个从单机到分布式的双层构架。
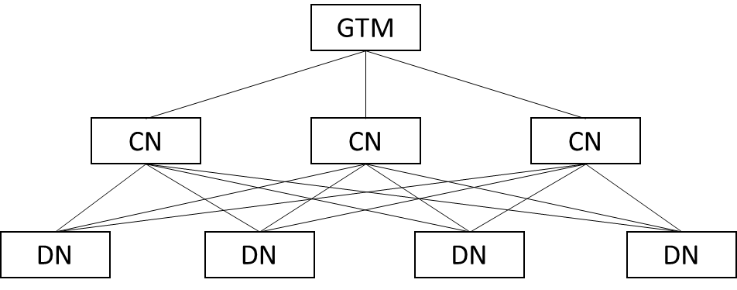
如图所示,在openGauss集群中,事务的执行和管理主要涉及GTM、CN和DN三种组件,其中:
GTM,全称Global Transaction Manager,即全局事务管理器,负责全局事务号的分发,事务提交时间戳的分发以及全局事务运行状态的登记。对于采用多版本并发控制(Multi-Version Concurrency Control,简称MVCC)的事务模型(以openGauss和Oracle为例),GTM本质上可以简化为一个递增序列号(或时间戳)生成器,其为集群的所有事务进行了全局的统一排序,以确定快照(Snapshot)内容和由此决定的事务可见性。在本章10.3节openGauss数据库并发控制中,将进一步详述GTM的作用。
CN,全称Coordinator Node,即协调者实例,负责管理和推进一个具体事务的执行流程,维护和推进事务执行的事务块状态机。
DN,全称Data Node,即数据实例,负责一个具体事务在某一个数据分片内的所有读写操作。
1. 显式事务和隐式事务
显式事务是指,用户在所执行的一条或多条SQL语句的前后,显式添加了开启事务START TRANSACTION语句和提交事务COMMIT语句。
隐式事务是指,用户在所执行的一条或多条SQL语句的前后,没有显式添加开启事务和提交事务的语句。在这种情况下,每一条SQL语句在开始执行时,openGauss内部都会为其开启一个事务,并且在该语句执行完成之后,自动提交该事务。
以一条SELECT语句和一条INSERT语句为例,简要描述显式事务和隐式事务在openGauss集群中的主要执行流程。
显式事务的SQL语句如下(假设表t只包含一个整数类型字段a,且为分布列):
START TRANSACTION; SELECT * FROM t; INSERT INTO t(a) VALUES (100); COMMIT;
1)START TRANSACTION
该SQL语句只在CN上执行,CN显式开启一个事务,并将CN本地事务块状态机从空闲状态置为进行中状态,然后返回客户端,等待下一条SQL命令。
2)SELECT * FROM t
该SQL语句首先在CN上执行,由于openGauss分片采用一致性哈希算法,因此对于不带分布列上谓词条件的查询语句,CN需要将该SQL语句发送到所有DN实例上执行。对于每一个分片对应的DN实例,由于采用了显式事务,CN会先发送一条START TRANSACTION命令给该DN,让该DN显式开启事务(DN上的事务块状态机从空闲状态变为进行中状态),然后CN将SELECT语句发送给该DN。此后,CN在收到所有DN的查询结果之后,返回客户端,等待下一条SQL命令。
3)INSERT INTO t(a) VALUES (100)
该SQL语句首先在CN上执行,由于a为表t的分布列,因此CN可以根据被插入记录中a的具体取值,来决定应该由哪个数据分片对应的DN实例来执行实际的插入操作(这里假设该分片为DN1)。由于采用了显式事务,CN先发送一条START TRANSACTION命令给DN1,由于经过第(2)步DN1的事务块状态机已经处于进行中状态,因此对于该语句DN1并不会执行什么实际的操作,然后,CN将具体的INSERT语句发送给DN1,并等待DN1执行插入成功之后,返回客户端,等待下一条SQL命令。
4)COMMIT
该SQL语句首先在CN上执行,CN进入提交事务阶段后,将COMMIT语句发送给所有参与第(2)步和第(3)步的DN,让这些DN结束该事务,并将DN本地的事务块状态机从进行中状态置为空闲状态。CN在收到所有DN的事务提交结果之后,再将CN本地的事务块状态机从进行中状态置为空闲状态。然后,CN返回客户端,该事务执行完成。
上述操作的隐式事务语句如下(假设表t只包含一个整数类型字段a,且为分布列):
SELECT * FROM t; INSERT INTO t(a) VALUES (1); 1)SELECT * FROM t
该SQL语句首先在CN上执行,CN隐式开启一个事务,将CN本地的事务块状态机从空闲状态置为开启状态(注意不同于显式事务中的进行中状态)。然后,CN需要将该语句发送到所有DN实例上执行。对于每一个分片对应的DN实例,由于采用了隐式事务且该语句为只读查询,CN直接将SELECT语句发送给该DN。
DN收到该SELECT语句之后,亦采用隐式事务:第一步,隐式开启事务,将DN本地的事务块状态机从空闲状态置为开启状态;第二步,执行该查询语句,将查询结果返回给CN;第三步,隐式提交事务,将DN本地的事务块状态机从开启状态置为空闲状态。
CN在收到所有DN的查询结果之后,返回客户端,并隐式提交事务,将CN本地的事务块状态机从开启状态置为空闲状态。
2)INSERT INTO t(a) VALUES (1)
该SQL语句首先在CN上执行,CN隐式开启一个事务,将CN本地的事务块状态机从空闲状态置为开启状态。然后,CN需要将该INSERT语句发送到目的分片的DN实例上执行(这里假设该分片为DN1)。
虽然该语句采用了隐式事务,但是由于该语句为写操作,因此在DN1上会采取显式事务:CN会先发送一条START TRANSACTION命令给DN1,让DN1显式开启事务(DN1上的事务块状态机从空闲状态变为进行中状态),然后CN将INSERT语句发送给DN1,DN1执行完成后,返回执行结果给CN。
CN收到执行结果之后,进入提交事务阶段。先发送COMMIT语句到DN1。DN1收到COMMIT语句后,进行显式提交,将DN1本地的事务块状态机从进行中状态置为空闲状态。CN在收到DN1的事务提交结果之后,本地再进行隐式提交事务,将CN本地的事务块状态机从开启状态置为空闲状态,返回客户端,该事务执行完成。
综上,对于CN来说,使用显式事务还是隐式事务,完全取决于用户输入的SQL语句;对于DN来说,只有当SQL为隐式只读事务时,才会使用隐式事务,当SQL为显式事务或者隐式写事务时,都会使用显式事务。
2. 单机事务和分布式事务
在openGauss这样的分布式集群中,单机事务(亦称单分片事务)是指一个事务中所有的操作都发生在同一个分片(即DN实例)上,分布式事务是指一个事务中有两个或以上的分片参与了该事务的执行。
对于单机事务,其写操作的原子性和读操作的一致性由该DN自身的事务机制就能保证;对于分布式事务,不同分片之间写操作的原子性和不同分片之间读操作的一致性,需要额外的机制来保障。下面结合SQL语句简要介绍下分布式事务的原子性和一致性要求,具体的原理机制在10.4节中说明。
首先,考虑涉及多分片的写操作事务,以如下事务T1为例(假设表t只包含一个整数类型字段a,且为分布列):
START TRANSACTION; INSERT INTO t(a) VALUES (v1); INSERT INTO t(a) VALUES (v2); COMMIT; 上面事务T1的两条INSERT语句均为只涉及一个分片的写(插入)事务,如果v1和v2分布在同一个分片内,那么该事务为单机事务,如果v1和v2分布在两个不同的分片内,那么该事务为分布式事务。
对于只涉及一个DN分片的单机事务,其对于数据库的修改和影响全部发生在同一个分片内,因此该分片的事务提交结果即是该事务在整个集群的提交结果,该分片事务提交的原子性就能够保证整个事务的原子性。在事务T1示例中,如果v1和v2全分布在DN1上,那么在DN1上,如果事务提交,那么这两条记录就全部插入成功;如果DN1上事务回滚,那么这两条记录的插入就全部失败。
对于分布式事务,为了保证事务在整个集群范围内的原子性,必须保证所有参与写操作的分片要么全部提交,那么全部回滚,不能出现部分分片提交,部分分片回滚的"中间态"。如下图所示,如果v1插入到DN1上,且DN1提交成功,同时,v2插入到DN2上,且DN2最终回滚,那么最终该事务只有一部分操作成功,破坏了事务的原子性要求。为了避免这种情况的发生,openGauss采用两阶段提交(Two Phase Commit,简称2PC)协议,来保证分布式事务的原子性,在10.4.1节中会对两阶段提交相关内容进行更详细的介绍。
其次,考虑涉及多分片的读操作事务T2,以如下SQL语句为例(假设表t只包含一个整数类型字段a,且为分布列):
START TRANSACTION; SELECT * FROM t where a = v1 or a = v2; COMMIT; 上面查询事务T2中,如果v1和v2分布在同一个分片内,那么该事务为单机事务,如果v1和v2分布在两个不同的分片内,那么该事务为分布式事务。
对于单机事务,其查询的数据完全来自于同一个分片内,因此该分片事务的可见性和一致性就能够保证整个事务的一致性。
在事务T1和T2示例中,考虑T1和T2并发执行的场景(假设T1提交成功),如果v1和v2全分布在DN1上,那么,在DN1上,如果T1对T2可见,那么T2就能查询到所有的两条记录,如果T1对T2不可见,那么T2不会查询到两条记录中的任何一条。
对于分布式事务,其查询的数据来自不同的分片,单个分片的可见性和一致性无法完全保证整个事务的一致性,不同分片之间事务提交的先后顺序和可见性判断会导致查询结果存在某种"不确定性"。
仍考虑T1和T2并发执行的场景(假设T1提交成功)。如下图所示,如果v1和v2分别分布在DN1和DN2上,若在DN1上,T1事务提交先于T2的查询执行,且对于T2可见,而在DN2上,T2的查询执行先于T1事务提交(或T1事务提交先于T2查询执行,但对T2不可见),那么T2最终只会查询到v1这一条记录。对于以银行为代表的传统数据库用户来说,这种现象破坏了事务作为一个整体的一致性要求。在分布式事务中,亦称为强一致性要求。
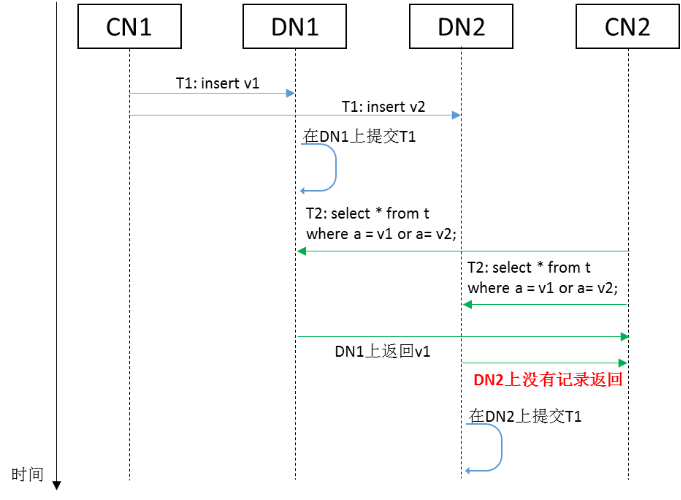
另一方面,如果T1先完成提交,并等待足够长的时间以后(保证所有分片均完成T1的提交,并保证提交结果对T2可见),再执行T2,那么T2将可以看到T1插入的所有两条记录。在分布式事务中,这种一致性表现被称为最终一致性。与传统数据库用户不同,在互联网等新兴业务中,最终一致性是被广泛接受的。
openGauss通过全局一致性的时间戳(快照)技术和本地两阶段事务补偿技术,提供分布式强一致事务的能力,同时,对于追求性能的新兴数据库业务,也支持可选的最终一致性事务的能力。
本文网址:https://www.eygle.com/archives/2021/11/opengauss_7.html
openGauss 数据库内存引擎 18 Nov 2021 5:23 PM (3 years ago)
本文来源于墨天轮:https://www.modb.pro/db/170018
内存引擎作为在openGauss中与传统基于磁盘的行存储、列存储并存的一种高性能存储引擎,基于全内存态数据存储,为openGauss提供了高吞吐的实时数据处理分析能力以及极低的事务处理时延,在不同业务负载场景下可以达到其他引擎事务处理能力的3~10倍不等。
内存引擎之所以有较强的事务处理能力,并不单是因为基于内存而非磁盘带来的性能提升,而更多是因为其全面地利用了内存中可以实现的无锁化的数据及索引结构、高效的数据管控、基于NUMA架构的内存管控、优化的数据处理算法以及事务管理机制。
值得一提的是,虽然是全内存态存储,但是并不代表着内存引擎中的处理数据会因为系统故障而丢失;相反的,内存引擎有着与openGauss原有机制相兼容的并行持久化、checkpoint(检查点)能力,使得内存引擎有着与其他存储引擎相同的容灾能力以及主备副本带来的高可靠能力。
内存引擎总的架构如图所示。
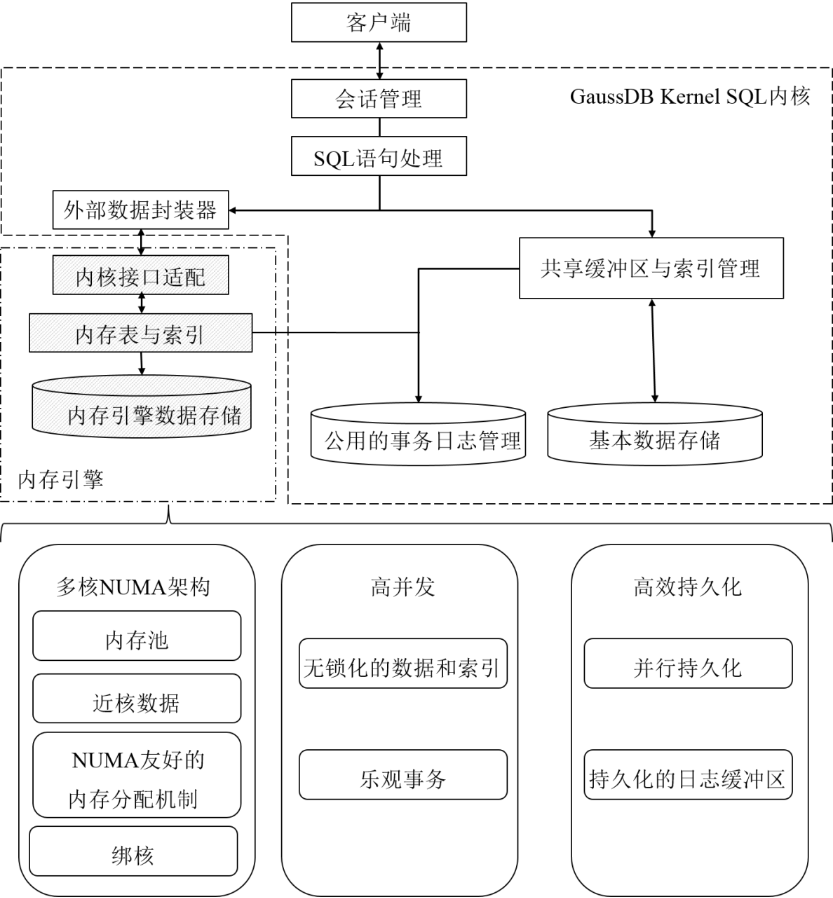
可以看到,内存引擎通过原有的Foreign Data Wrapper(外部数据封装器)扩展能力与openGauss的优化执行流程相交互,通过事务机制的回调以及与openGauss相兼容的WAL机制,保证了与其他存储引擎在这一体系架构内的共存,保证了整体对外的一致表现;同时通过维护内部的内存管理结构、无锁化索引、乐观事务机制来为系统提供极致的事务吞吐能力。
以下将逐步展开讲解相关关键技术点与设计。
1. 内存引擎的兼容性设计
由于数据形态的不同以及底层事务机制的差别,此处如何与一个以段页式为基础的系统对接是内存引擎存在于openGauss中的重点问题之一。
此处openGauss原有的FDW(Foreign Data Wrapper)机制为内存引擎提供了一个很好的对接接口,优化器可以通过FDW来获取内存引擎内部的元信息,内存引擎的内存计算处理机制可以直接通过FDW的执行器接口算子实现直接调起、并通过相同的结构将结果以符合执行器预期的方式(比如Scan(扫描)操作的pipelining(流水线))将结果反馈回执行器进行进一步处理后(如排序、Group by(分组))返回给客户端应用。
与此同时内存引擎自身的Error Handling(错误处理机制),也可以通过与FDW的交互,提交给上次系统,以此同步触发上层逻辑的相应错误处理(如回滚事务、线程退出等)。
内存引擎借助FDW的方式接近无缝的工作在整个系统架构下,与以磁盘为基础的行列存储引擎实现共存。
在内存引擎中Create Table(创建表)的实际操作流程如图所示。
可以看到FDW充当了一个整体交互API的作用。实现中同时扩展了FDW的机制,使得其具有更完备的交互功能,包括:
(1) 支持DDL接口;
(2) 完整的事务生命周期对接;
(3) 支持checkpoint(检查点);
(4) 支持持久化WAL;
(5) 支持故障恢复(Redo);
(6) 支持Vacuum(垃圾清理回收)。
借由FDW机制,内存引擎可以作为一个与原有openGauss代码框架异构的存储引擎存在于整个体系中。
2. 内存引擎索引
内存引擎的索引结构以及整体的数据组织都是基于Masstree实现的。主体如图所示。
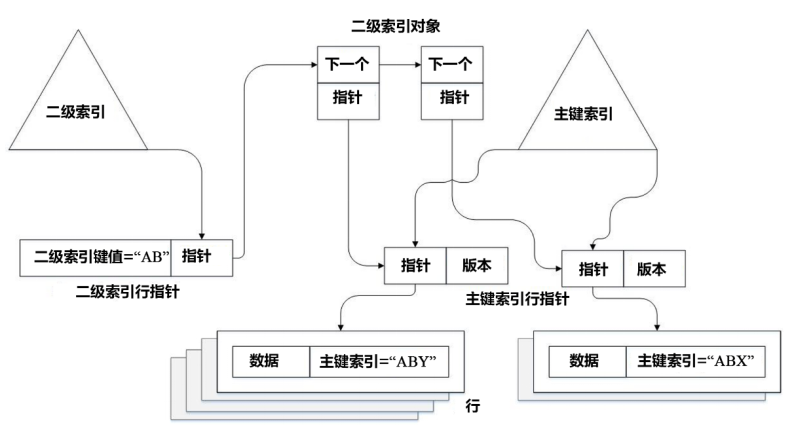
Primary Index(主键索引)在内存引擎的一个表中是必须存在的要素,因此要求表在组织时尽量存在primary index;如果不存在,内存引擎也会额外生成surrogate key(代理键)来用于生成Primary index。Primary Index指向各个代表各个行记录的Sentinel(行指针),由Sentinel来对行记录数据进行内存地址的记录以及引用。Secondary Index(二级索引)索引后指向一对键值,键值的value(值)部分为到对应数据Sentinel的指针。
Masstree作为Concurrent B+ tree(并行B+树),集成了大量B+树的优化策略,并在此基础上做了进一步的改良和优化。其大致实现如图所示。
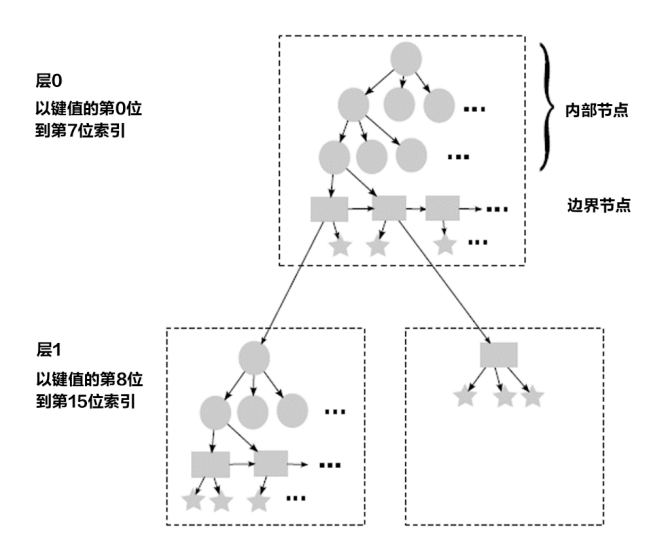
Masstree实现比于传统的B-tree,Masstree实际上是一个类似于诸多B+-树以trie(前缀树)的组织形式堆叠的Radix tree(基数树)模式,以Key(键)的前缀作为索引,每k个字节形成一层B+-树结构,在每层中处理Key(键)中这k个字节对应所需的insert/lookup/update/delete流程。下图为k=8时情况。
Masstree中的读操作使用了类OCC(Optimistic Concurrency Control,乐观并发控制)的实现,而所有的update(更新)锁仅为本地锁。在树的结构上,每层的interior node(内部节点)和leaf node(叶子节点)都会带有版本,因此可以借助version validation(版本检查)来避免fine-grained lock(细粒度锁)的使用。
Masstree除了lockless(无锁化)之外,最大的亮点是cache line(缓存块)的高效利用。Lockless本身一定程度避免了lookup/insert/update操作互相invalidate共享cache line(失效共享缓存块)的情况。而基于prefix(前缀)的分层,辅以合适的每层中B+-树fanout(扇出)的设置,可以最大程度的利用CPU prefetch(预取)的结果(尤其是在树的深度遍历过程中),减少了与DRAM交互带来的额外时延。
Prefetch(预取)在Masstree的设计中显得尤为关键,尤其是在Masstree从tree root(树根节点)向leaf node(叶子节点)遍历、也就是树的下降过程中。此过程中的执行时延大部分由于内存交互的时延组成,因此prefetch(预取)可以有效地提高masstree traverse(遍历)操作的执行效率以及cache line(缓存块)的使用效率(命中)。
3. 内存引擎的并发控制
内存引擎的并发控制机制采用OCC,在操作数据冲突少的场景下,并发性能很好。
内存引擎的事务周期以及并发管控组件结构,如图所示。
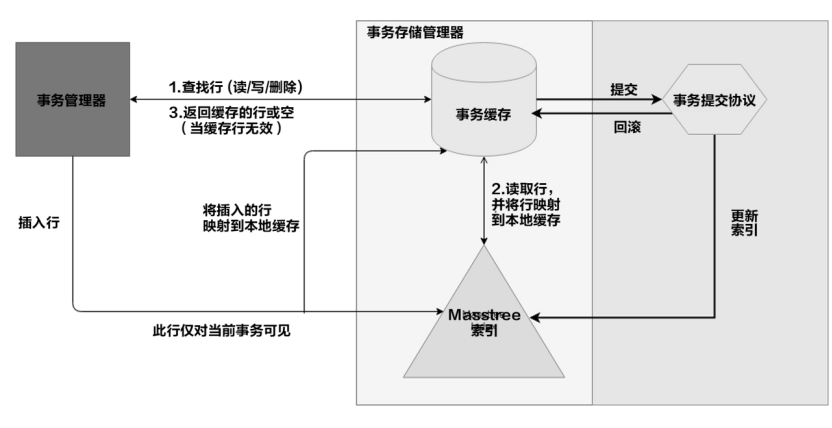
这里需要解释一下,内存引擎的数据组织为什么整体是一个接近无锁化的设计。
除去以上提到的Masstree本身的无锁化机制外,内存引擎的流程机制也进一步最小化了并发冲突的存在。
每个工作线程会将事务处理过程中所有需要读取的记录,复制一份至本地内存,保存在read-set(读数据集)中,并在事务全程基于这些本地数据进行相应计算。相应的运算结果保存在工作线程本地的write set(写数据集)中。直至事务运行完毕,工作线程会进入尝试提交流程,对read set(读数据集)和write set进行validate(检查验证)操作并在允许的情况下对write set中数据对应的全局版本进行更新。
这样的流程,会把事务流程中对于全局版本的影响,缩小到validation的过程,而在事务进行其他任何操作的过程中都不会影响到其他的并发事务。并且,在仅有的validation(检查验证)过程中,所需要的也并不是传统意义上的锁,而仅是记录头部信息中的代表锁的数位(lock bit)。相应的这些考虑,都是为了最小化并发中可能出现的资源争抢以及冲突,并更有效地使用CPU缓存。
同时read set(读数据集)和write set(写数据集)的存在,可以良好地支持各个隔离级别,不同隔离级别可以通过在validation(检查验证)阶段对read set(读数据集)和write set(写数据集)进行不同的审查机制来获得。通过检查两个set(数据集)中行记录在全局版本中对应的lock bit(锁定位)以及行头中的TID结构,可以判断自己的读、写与其他事务的冲突情况,进而判断自己在不同隔离级别下是否可以commit(提交)、或是需要abort(终止)。同时由于Masstree中Trie node中存在版本记录,Masstree的结构性改动(insert/delete,插入/删除)会更改相关Trie node(节点)上面的版本号。因此维护一个Range query(范围查询)涉及的node set(节点集),并在validation(检查验证)阶段对其进行对比校验,可以比较容易地在事务提交阶段检查此Range query所涉及的子集是否有过变化,从而能够检测到Phantom(幻读)的存在,是一个时间复杂度很低的操作。
4. 内存引擎的内存管控
由于内存引擎的数据是全内存态的,因此可以按照记录来组织数据,不需要遵从页面的数据组织形式,从而从数据操作的冲突粒度这一点上有着很大优势。摆脱了段页式的限制,不再需要共享缓存区进行缓存以及与磁盘间的交互淘汰,设计上不需要考虑IO以及磁盘性能的优化(比如索引B+ 树的高度以及HDD(Hard Disk Driv,磁盘)对应的随机读写问题),数据读取和运算就可以进行大量的优化和并发改良。
由于是全内存的数据形态,内存资源的管控就显得尤为重要,内存分配机制及实现会很大程度上影响到内存引擎的计算吞吐能力。内存引擎的内存管理主要分为3层,如图所示。
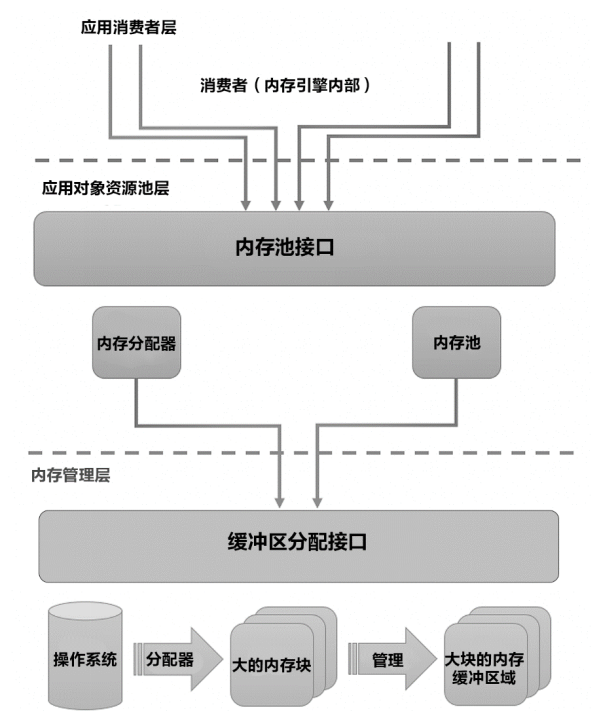
下面分别对3层设计进行介绍:
(1) 第一层为内存引擎自身,包含了临时的内存使用以及长期的内存使用(数据存储)。
(2) 第二层为对象的内存池,主要负责为第一层对象如表、索引、行记录、Key值、以及Sentinel(行指针)提供内存。该层从底层索取大块内存,再进行细粒度的分配。
(3) 第三层为资源管理层,主要负责与操作系统之间的交互,以及实际的内存申请。为降低内存申请的调用开销,交互单位一般在2 MB左右。此层同时也有内存预取和预占用的功能。
第三层实际上是非常重要的,主要因为:
(1) 内存预取可以非常有效的降低内存分配开销,提高吞吐量。
(2) 与NUMA库进行交互的性能成本非常高,如果直接放在交互层会对性能产生很大影响。
内存引擎对短期与长期的内存使用针对NUMA结构适配的角度也是不同的。短期使用,一般为事务或session(会话)本身,那么此时一般需要在处理该session的CPU核对应的NUMA节点上获取本地内存,使得transaction(交易)本身的内存使用有着较小的开销;而长期的内存使用,如表、索引、记录的存储,则需要NUMA概念中interleaved内存,并且要尽量平均分配在各个NUMA节点上,来防止单个NUMA节点内存消耗过多带来的性能下降。
短期的内存使用,也就是NUMA角度的本地内存,也有一个很重要的特性,就是这部分内存仅供本事务自身使用(比如复制的读取数据以及做出的更新数据),因此也就避免了这部分内存上的并发管控。
5. 内存引擎的持久化
内存引擎基于同步的WAL机制以及checkpoint(检查点)来保证数据的持久化,并且此处通过兼容openGauss的WAL机制(即Transaction log,事务日志),在数据持久化的同时,也可以保证数据能够在主备节点之间进行同步,从而提供RPO=0的高可靠以及较小RTO的高可用能力。
内存引擎的持久化机制如图所示。
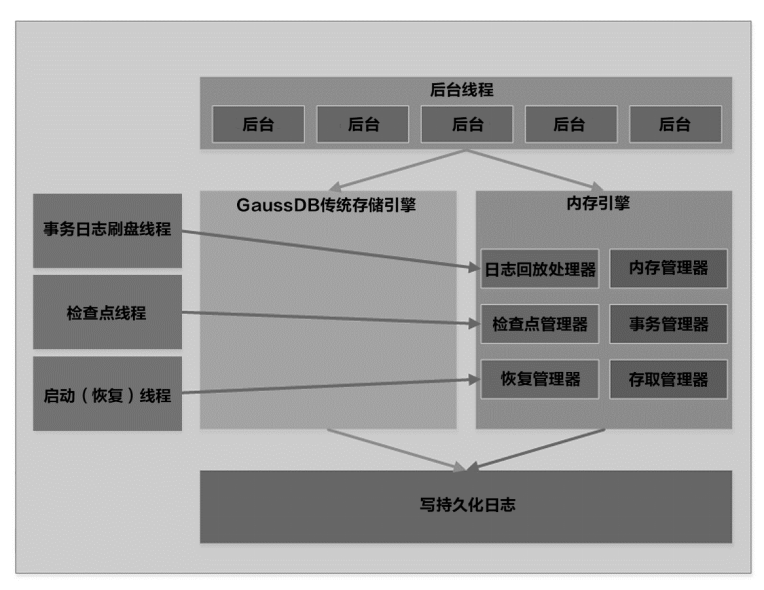
可以看到,openGauss的Xlog模块被内存引擎对应的manager(管理器)所调用,持久化日志通过WAL的writer线程(刷新磁盘线程)写至磁盘,同时被walsender(事务日志发送线程)调起发往备机,并在备机walreceiver(事务日志接收线程)处接收、落盘与恢复。
内存引擎的Checkpoint也是根据openGauss自身的checkpointer机制被调起。
openGauss中的checkpoint机制是通过在做checkpoint时进行shared_buffer(共享缓冲区)中脏页的刷盘,以及一条特殊checkpoint日志来实现的。内存引擎由于是全内存存储,没有脏页的概念,因此实现了基于CALC的Checkpoint机制。
这里主要涉及一个部分多版本(partial multi-versioning)的概念:当一个checkpoint指令被下发,使用两个版本来追踪一个记录:活跃(live)版本,也就是该记录的最新版本;稳定(stable)版本,也就是在checkpoint被下发、形成虚拟一致性点时此记录对应的版本。在一致性点之前提交的事务需要更新活跃(live)和稳定(stable)两个版本,而在一致性点之后的事务仅更新活跃(live)版本本保持stable版本不变。在无checkpoint状态的时候,实际上稳定(stable)版本是空的,代表着stable与live版本在此时实际是相同的值;仅有在checkpoint过程中,在一致性点后有事务对记录进行更新,此时才会需要根据双版本来保证checkpoint与其他正常事务流程的并行运作。
CALC(Checkpointing Asynchronously using Logical Consistency,逻辑一致性异步检查点)的实现有5个阶段:
(1) rest(休息)阶段:这个阶段内,没有checkpoint(检查点)的流程,每个记录仅存储live版本。
(2) prepare(准备)阶段:整个系统触发checkpoint后,会马上进入这个阶段。在这个阶段中事务对读写的更改,也会更新live版本;但是在更新前,如果stable版本不存在,那么在更新live版本前,live版本的数据会被存入stable版本。在此事务的更新结束,在放锁前,会进行检查:如果此时系统仍然处于prepare阶段,那么刚刚生成的stable版本可以被移除;反之,如果整个系统已经脱离prepare阶段进入下一阶段,那么stable版本就会被保留下来。
(3) resolve(解析)阶段:在进入prepare阶段前发生的所有事务都已提交或回滚后,系统就会进入resolve阶段,进入这个阶段也就代表着一个虚拟一致性点已经产生,在此阶段前提交的事务相关的改动都会被反映到此次checkpoint中。
(4) capture(捕获)阶段:在prepare阶段所有事务都结束后,系统就会进入capture阶段。此时后台线程会开始将checkpoint对应的版本(如果没有stable版本的记录即则为live版本)写入磁盘,并删除stable版本。
(5) complete(完成)阶段:在checkpoint写入过程结束后,并且capture阶段中进行的所有事务都结束后,系统进入complete阶段,系统事务的写操作的表现会恢复和rest阶段相同的默认状态。
CALC有着以下优点:
(1) 低内存消耗:每个记录至多在checkpoint时形成两份数据。在checkpoint进行中如果该记录stable版本和live版本相同,或在没有checkpoint的情况下,内存中只会有数据自身的物理存储。
(2) 较低的实现代价:相对其他内存库checkpoint机制,对整个系统的影响较小。
(3) 使用虚拟一致性点:不需要阻断整个数据库的业务以及处理流程来达到一份物理一致性点,而是通过部分多版本来达到一个虚拟一致性点。
6. 小结
openGauss整个系统设计是可插拔、自组装的, openGauss通过支持多个存储引擎来满足不同场景的业务诉求,目前支持行存储引擎、列存储引擎和内存引擎。其中面向OLTP不同的时延要求,需要的存储引擎技术是不同的。例如在银行的风控场景里,对时延的要求是非常苛刻,传统的行存引擎的时延很难满足业务要求。openGauss除了支持传统行存引擎外还支持内存引擎。在OLAP联机数据分析处理上openGauss提供了列存储引擎,有极高的压缩比和计算效率。另外一个事务里可以同时包含三种引擎的DML操作,且可以保证ACID。
本文网址:https://www.eygle.com/archives/2021/11/opengauss_6.html